
Meta发布了人工智能模型SeamlessM4T,SeamlessM4T支持对近百种语言进行语音以及文本识别,同时支持近 100 种输入语言和 36 种输出语言的语音到语音翻译。
官方发布地址:https://ai.meta.com/blog/seamless-m4t/

SeamlessM4T:大规模多语种多模态机器翻译
SeamlessM4T—Massively Multilingual & Multimodal Machine Translation
-
论文:https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf
-
Code:https://github.com/facebookresearch/seamless_communication
-
Hugging Face:https://huggingface.co/spaces/facebook/seamless_m4t
动机:为了解决语音翻译中的挑战,构建一个支持多语言和多模态的机器翻译系统。
方法:使用自监督的语音表示学习方法和自对齐的语音翻译语料库构建技术,开发了一个支持语音到语音、语音到文本、文本到语音和文本到文本的统一模型。
优势:提出的SeamlessM4T模型在多个评估指标上取得了显著的提升,支持多种语言的翻译,并且具有更好的鲁棒性和翻译安全性。
介绍了SeamlessM4T模型,通过自监督学习和自对齐构建了一个支持多语言和多模态的机器翻译系统,取得了显著的性能提升。
SeamlessM4T支持:
近100种语言的自动语音识别
近100种输入和输出语言的语音到文本翻译
近100种输入语言和35种(加上英语)输出语言的语音到语音翻译
近100种语言的文本到文本翻译
近100种输入语言和35种(加上英语)输出语言的文本到语音翻译
-
语音翻译在覆盖范围和性能上落后于文本翻译,当前的语音翻译系统主要是翻译成英语,而不是从英语进行翻译。 -
语音是比文本更丰富的媒介,通过语调、表达和交互传递更多信息,这使语音翻译具有挑战性,但也更自然和社交性。 -
对许多群体而言,如文盲或视力障碍者,语音比文本更便于访问,能翻译语音的系统能促进包容性。 -
对于使用不同文字的语言,语音翻译避免了文本翻译可能出现的无法辨认的输出问题。 -
目前的语音翻译依赖级联系统,将ASR、MT和TTS模型链式组合。这可能会传播错误和导致失配。 -
本文提出一个统一的模型SeamlessM4T,可以处理ASR、语音到语音、语音到文本、文本到语音和文本到文本翻译。 -
SeamlessM4T扩展了源语言和目标语言的覆盖范围,从100种语言翻译到英语,以及从英语翻译到35种语言。 -
达到了新的最先进水平,在翻译到英语的语音到文本翻译上,BLEU分数比以前的模型提高了20%。 -
该模型开源,还开源了对齐的语音数据、挖掘工具和其他资源,以促进语音翻译研究。
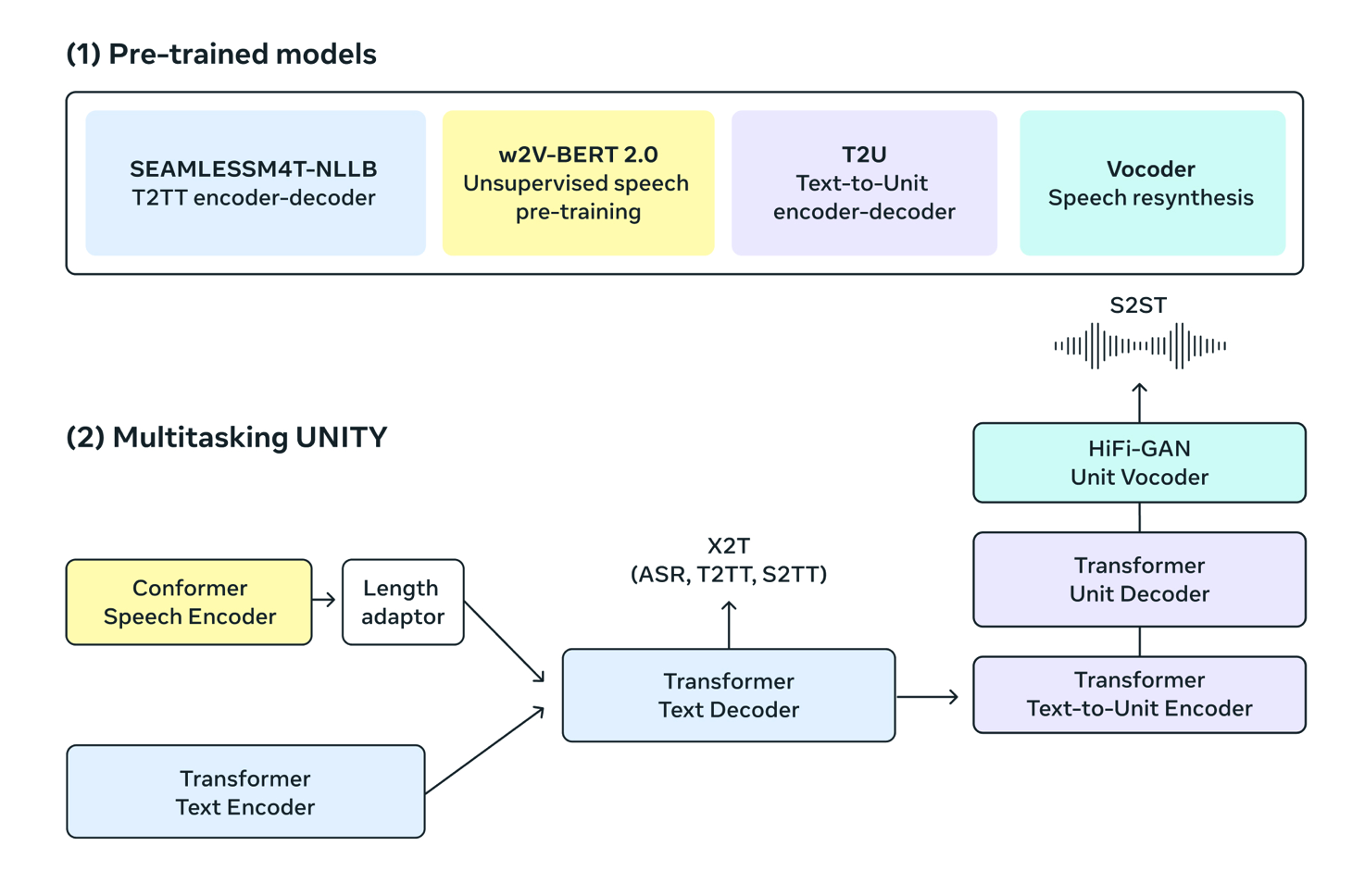
编码器如何处理语音
为了让编码器能够处理语音,我们使用了一个基于卷积神经网络(CNN)的前端 ,它将原始的语音信号转换为一系列的特征向量。这些特征向量被送入一个Transformer编码器,它由多个自注意力(self-attention)层组成,可以捕捉语音中的长期依赖关系。我们使用了一种称为动态卷积(dynamic convolution) 的技术,它可以根据输入的语音动态地生成卷积核,从而提高编码器的表示能力。我们还使用了一种称为深度因子化(depth factorization)的技术,它可以将每个自注意力层分解为两个较浅的子层,从而减少计算量和内存消耗。
编码器如何处理文本
为了让编码器能够处理文本,我们使用了一个基于字节对编码(byte pair encoding,BPE) 的子词(subword)分词器 ,它将不同语言的文本切分为一系列的子词单元。这些子词单元被嵌入到一个高维空间中,并被送入一个Transformer编码器,它与处理语音的编码器共享参数。这样做的好处是可以让模型在不同语言和模态之间进行知识迁移,提高模型的泛化能力。我们还使用了一种称为适应性输入(adaptive input) 的技术,它可以根据子词单元的频率动态地调整嵌入维度,从而降低参数数量和计算复杂度。
生成文本
为了生成文本,我们使用了一个Transformer解码器,它由多个自注意力层和交叉注意力(cross-attention)层组成,可以分别捕捉目标文本中的内部结构和与源文本或语音的对齐关系。我们使用了一种称为适应性软最大值(adaptive softmax) 的技术,它可以根据子词单元的频率动态地调整输出层的结构,从而加速训练和推理过程。我们还使用了一种称为多头注意力网络(multi-head attention network,MHAN) 的技术,它可以让解码器同时从多个源编码器中获取信息,并根据任务类型自动地加权融合。
生成语音
为了生成语音,我们使用了一个基于Tacotron 2 的神经声学模型的神经声学模型,它可以根据目标文本生成语音的梅尔频谱(mel-spectrogram)。我们使用了一种称为区域注意力(zoneout attention)的技术,它可以在训练和推理过程中保持注意力状态的一致性,从而提高语音的自然度和流畅度。我们还使用了一种称为知识蒸馏(knowledge distillation)的技术,它可以利用一个大型的教师模型来指导一个小型的学生模型,从而减少模型的大小和延迟。为了将梅尔频谱转换为原始的语音信号,我们使用了一个基于WaveRNN的神经声码器(neural vocoder),它可以生成高质量的语音波形。
数据扩充
像SeamlessM4T这样的数据驱动模型通常需要大量高质量的端到端数据,即语音到文本和语音到语音数据。仅依靠人工转录和翻译的语音无法满足100种语言语音翻译的挑战性任务需求。我们在文本挖掘方面的开创性工作基础上,开发了语音挖掘技术来创建额外资源用于训练SeamlessM4T模型。
首先,我们为200种语言构建了全新的大规模多语言多模态文本嵌入空间SONAR,其性能明显优于现有方法如LASER3或LaBSE的多语言相似度搜索。然后,我们采用老师-学生方法将此嵌入空间扩展到语音模态,目前覆盖36种语言。我们从公开可用的数十亿句子的网络数据仓库和400万小时的语音中进行挖掘。总体上,我们能够自动对齐超过44.3万小时的语音和文本,并创建约2.9万小时的语音到语音对齐。这个语料库名为SeamlessAlign,是迄今为止在语言覆盖量和总量上最大的开放语音语音和语音文本平行语料。
结果
在这些任务和语言上,SeamlessM4T在近100种语言上都取得了目前最好的结果,并在一个模型中支持语音识别、语音转文本、语音转语音、文本转语音和文本翻文本等多任务。与以往方法相比,我们显著提高了对支持语言中资源较少和中等的语言的性能,同时在资源丰富的语言如英语、西班牙语、德语等上保持了强大的性能。
如何负责任地构建SeamlessM4T
翻译系统的准确性非常重要。与所有AI系统一样,此模型存在将人们想说的内容错误转换或生成有毒或不准确输出的固有风险。
Meta的AI研发遵循负责任AI的框架,其指导原则是我们的五大责任AI支柱。为了负责任地AI,我们进行了关于毒性和偏见的研究,以帮助我们了解模型中可能敏感的领域。在毒性方面,我们将高度多语言的毒性分类器扩展到语音,以帮助识别语音输入和输出中的毒性词汇。如果输入和输出的毒性存在不平衡,我们会删除该训练对。
今天发布的演示展示了SeamlessM4T的功能,是研究的重要组成部分。我们在输入和输出中都检测了毒性。如果只在输出中检测到毒性,这意味着毒性是被添加的。在这种情况下,我们会发出警告并不显示输出。与目前的状态相比,我们在语音转语音和语音转文本翻译中显着减少了添加的毒性。
性别偏见是另一个需要大规模评估的领域,其中结果可能不公正地偏向某个性别,有时会默认为性别刻板印象。通过扩展之前设计的多语言整体偏差数据集到语音,我们现在能够量化数十种语音翻译方向中的性别偏见。
我们在安全性和保密性方面的工作是一项持续的努力。我们将继续在这方面进行研究并采取行动,不断改进SeamlessM4T,减少模型中出现的任何毒性情况。
获取SeamlessM4T相关技术
凭借最先进的结果,我们认为SeamlessM4T是AI社区追求通用多任务系统的重要突破。为贯彻开放科学的理念,我们很高兴与研究人员和开发人员分享我们的模型,以推动相关技术的发展。
这只是我们持续努力构建能帮助人们跨语言交流的AI驱动技术的最新步骤。未来,我们希望探索这个基础模型如何支持新的沟通能力,最终让我们更接近一个人人都能理解彼此的世界。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢