
前言 现有可控视频生成工作主要存在两个问题:首先,大多数现有工作基于文本、图像或轨迹来控制视频的生成,无法实现视频的细粒度控制;其次,轨迹控制研究仍处于早期阶段,大多数实验都是在 Human3.6M 等简单数据集上进行的,这种约束限制了模型有效处理开放域图像和复杂弯曲轨迹的能力。
基于此,来自中国科学技术大学、微软亚研和北京大学的研究者提出了一种基于开放域扩散的新型视频生成模型 ——DragNUWA。DragNUWA 从语义、空间和时间三个角度实现了对视频内容的细粒度控制。
本文共一作殷晟明、吴晨飞,通讯作者段楠。






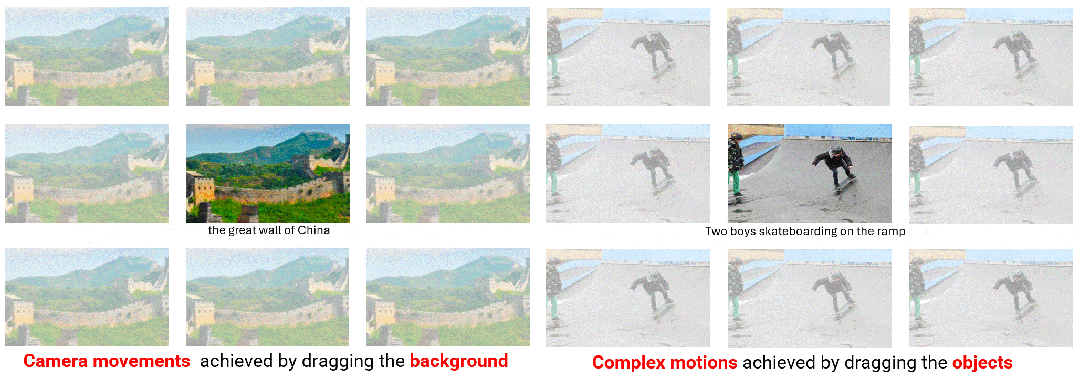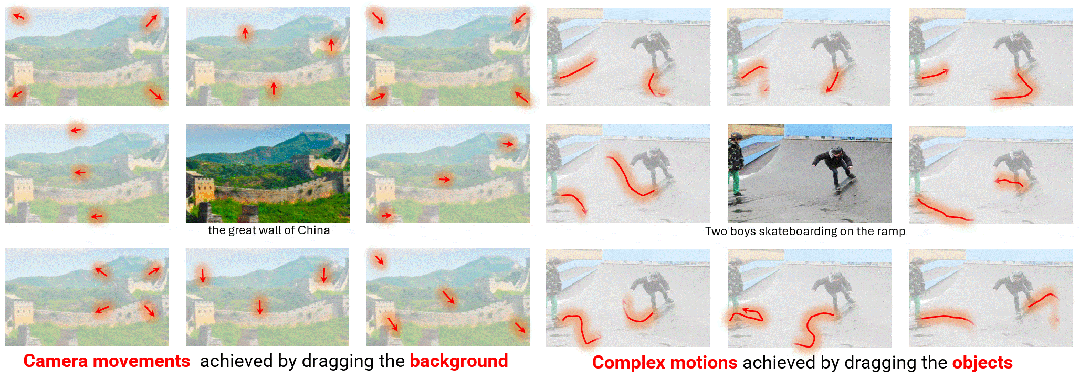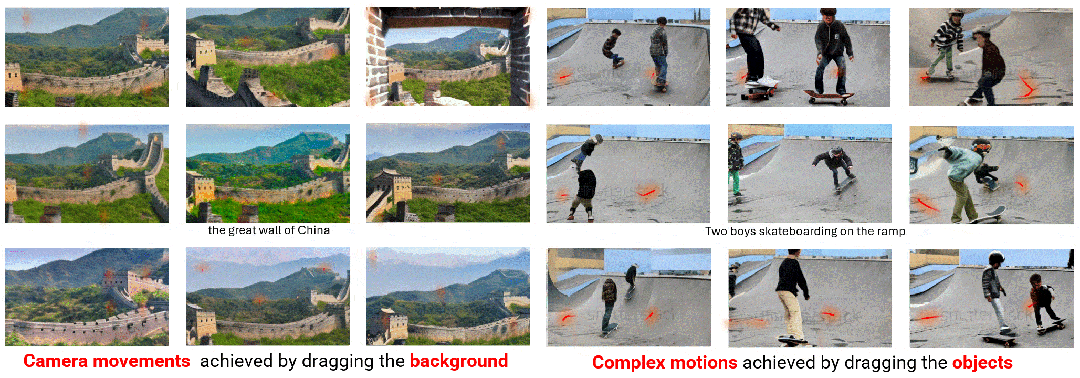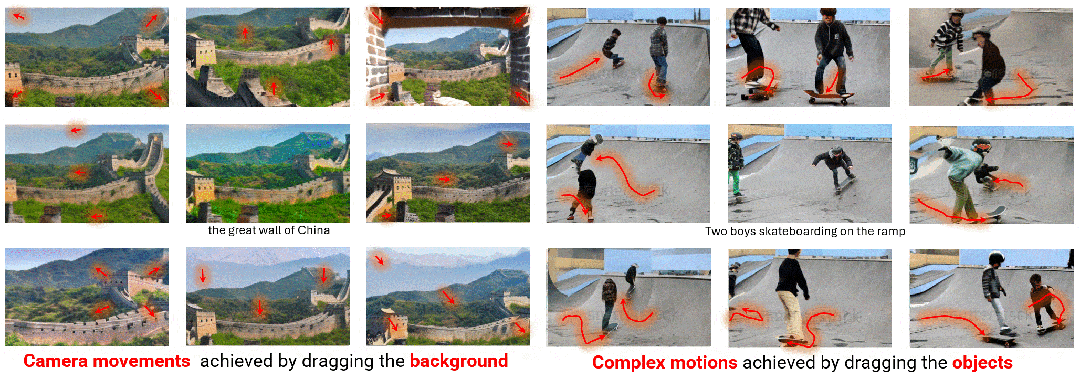

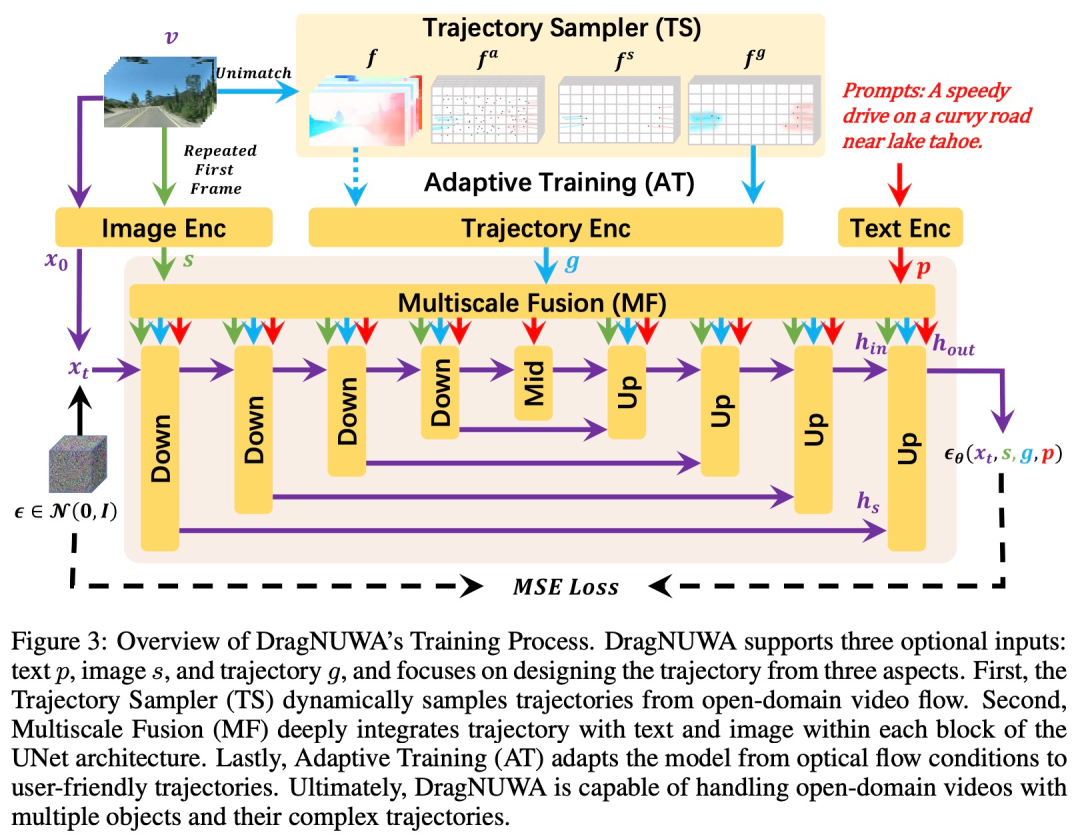
使用轨迹采样器(Trajectory Sampler,TS)在训练期间直接从开放域视频流中采样轨迹,用于实现任意轨迹的开放域控制; 使用多尺度融合(Multiscale Fusion,MF)将轨迹下采样到各种尺度,并将其与 UNet 架构每个块内的文本和图像深度集成,用于控制不同粒度的轨迹; 采用自适应训练(Adaptive Training,AT)策略,以密集流为初始条件来稳定视频生成,然后在稀疏轨迹上进行训练以适应模型,最终生成稳定且连贯的视频。



若觉得还不错的话,请点个 “赞” 或 “在看” 吧
论文指导班
论文指导班面向那些没有导师指导、需要升学申博的朋友,指导学员从零开始调研相关方向研究、尝试idea、做实验、写论文,指导老师会提供一些idea、代码实现部分的指导、论文写作指导和修改,但整体仍然是由学员自主完成。需要说明的是,论文指导班并非帮你写论文,或者直接给一篇论文让你挂名,我们不会做任何灰色产业,因此,想直接买论文或挂名的朋友请勿联系。
指导老师:
海外QS Top-60某高校人工智能科学博士在读, 师从IEEE Fellow,曾在多家AI企业担任研究实习生和全职算法研究员,具备极强的学术届和工业界综合背景。研究领域主要包括通用计算机视觉模型的高效设计,训练,部署压缩以及在目标检测,语义分割等下游任务应用,具体包括模型压缩 (知识蒸馏,模型搜索量化剪枝), 通用视觉模型与应用(VIT, 目标检测,语义分割), AI基础理论(AutoML, 数据增广,无监督/半监督/长尾/噪声/联邦学习)等;共发表和审稿中的15余篇SCI国际期刊和顶级会议论文,包括NeurIPS,CVPR, ECCV,ICLR,AAAI, ICASSP等CCF-A/B类会议。发明专利授权2项。
长期担任计算机视觉、人工智能、多媒体领域顶级会议CVPR, ECCV, NeurIPS, AAAI, ACM MM等审稿人。指导研究生本科生发表SCI, EI,CCF-C类会议和毕业论文累计30余篇,有丰富的保研,申博等方面经验,成功辅导学员赴南洋理工,北大,浙大等深造。
涉及范围:CCF会议A类/SCI一区、CCF会议B类/SCI二区、CCF会议C类/SCI三区、SCI四区、EI期刊、EI会议、核心期刊、研究生毕业设计
报名请扫描下方二维码了解详细情况,备注:“论文班报名”。

如果有其他想要当论文指导老师的朋友,请发简历给我,同样扫描上方二维码,备注:“论文指导老师”。基本条件:已发表两篇以上一作顶会,或3-5篇其他级别的一作论文,学历在985博士及以上。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢