本文介绍一篇被ICML2023录用的旨在解决持续学习中灾难性遗忘(CF)的工作。目前关于持续学习中的研究主要集中在防止灾难性遗忘方面。虽然有几种技术已经实现了没有CF的学习,但它们是通过让每个任务垄断共享网络中的一个子网来实现的,这严重限制了知识转移 (KT) 并导致网络容量的过度消耗,即学习的任务越多,性能就越差。该文提出了一种基于旧任务训练参数的更新进行软掩码(部分掩码)的新技术(SPG)以解决网络容量和灾难性遗忘问题。其中,每个任务仍然使用整个网络,即没有任何任务垄断网络的任何部分,从而实现最大的KT并减少容量使用。并且,该文是第一个在参数级别为持续学习进行软掩模模型的工作。此外,该文通过大量的实验证明了该方法的有效性。灾难性遗忘(CF)和知识转移(KT)是持续学习(CL)的两个关键挑战,它是增量学习一系列任务。CF指的是一种现象,即一个模型一旦学习了一个新任务,就会在之前的任务中失去一些性能。KT的意思是,任务可以通过分享知识来帮助彼此学习。而该文进一步研究了任务式持续学习(TCL)。尽管已经提出了几种有效的TCL方法,可以在很少或没有CF的情况下实现学习。然而,参数隔离可能是最成功的方法,其中系统学习为共享网络中的每个任务掩码子网络。HAT[1]为每个任务重要的神经元(不是参数)设置二进制或者硬掩码。在学习新任务的过程中,这些掩模阻断了反向传播中通过被掩模神经元的梯度流。只有那些自由的(暴露的)神经元和它们的参数是可训练的。因此,随着更多的任务被学习,剩余的空闲神经元数量变得越来越少,使得以后的任务更难学习,这导致性能逐渐下降。此外,如果一个神经元被掩码,那么输入到它的所有参数也会被掩码,这会消耗大量的网络容量(这也称为“容量问题”)。由于旧任务的子网络不能更新,知识转移有限。CAT[2]试图通过检测任务相似性来提高HAT的KT。如果发现新任务与以前的一些任务相似,则删除这些任务的掩码,以便新任务训练可以更新这些任务的参数以进行向后传递。然而,这是有风险的,因为如果一个不相似的任务被检测为相似,就会发生严重的CF,如果相似的任务被检测为不相似,它的知识转移将受到限制。为了解决以上这些问题,该文提出了一种非常不同的方法,称为“参数级梯度流的软掩蔽”(SPG),并在以下方面有所贡献:(1)SPG既不是为每个任务在神经元上学习硬/二进制掩码,也不是在训练新任务和像HAT这样的测试中阻塞这些神经元,而是使用梯度计算每个网络参数(不是神经元)对旧任务的重要性分数。梯度之所以可以作为重要性,是因为梯度可以直接告诉了一个特定参数的改变会如何影响输出的分类,并可能导致CF。SPG使用每个参数的重要性分数作为软掩码来约束梯度流在逆向传递中可以确保旧任务的重要参数在学习新任务时变化最小,以防止以前的知识CF。(2)SPG与流行的基于正则化的方法有一些相似之处,例如EWC [3],两者都使用参数的重要性来约束对旧任务重要参数的更改。但是它有一个主要的区别,SPG直接控制每个参数(细粒度),但EWC使用损失中的正则化项来惩罚网络中所有参数的更改之和(相当粗粒度),从而控制所有参数。(3)SPG在正向传递中,没有使用掩码,这鼓励了任务之间的知识传递。这比CA - T更好,因为SPG不需要额外的任务相似性比较机制。(4)由于SPG对参数进行了软掩码,所以SPG不会像HAT那样对每个任务独占任何参数或子网,并且SPG的前向传递不使用任何掩码。这减少了容量问题。目前的参数隔离方法(如HAT),对于克服CF非常有效,但它们阻碍了知识转移以及消耗了太多的网络学习能力。对于这样一个模型,为了提高知识转移,它需要决定哪些参数可以共享和更新为一个新的任务。这就是CAT所采用的方法。CAT发现相似的任务,并删除它们的掩码进行更新,但可能会发现错误的相似任务,从而导致CF。如果一个神经元被掩码,那么输入到它的所有参数都会被掩码,这会消耗大量的学习能力。SPG根据参数对前一个任务的重要性直接对参数进行软掩码,这是一种更灵活的方法,使用的学习空间也更少。软掩码显然支持自动知识转移。图1和算法1说明了SPG的工作原理。在SPG中,参数对任务的重要性是根据其梯度计算的。该文这样做是因为参数的梯度直接和定量地反映了参数变化对最终损失的影响程度。此外,该文还对每层内参数的梯度进行归一化,使相对重要性作为不同层的梯度更加可靠。该文还进一步通过累积归一化的重要性分数,在优化步骤中减小相应的梯度,避免忘记从以前的任务中学习到的知识。该文的此过程对应于图1(b)。在完成任务t的训练后,按照这些步骤计算每个参数对任务t的重要性。将任务t的训练数据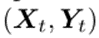 再次赋给任务t的训练模型,然后计算第i层中每个参数的梯度(即每层的每个权重或偏差),并用于计算参数的重要性。注意,该文使用
再次赋给任务t的训练模型,然后计算第i层中每个参数的梯度(即每层的每个权重或偏差),并用于计算参数的重要性。注意,该文使用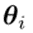 (一个向量)来表示第i层的所有参数,并且此过程不更新模型参数。在当前任务的训练已经收敛后计算重要性的原因如下:即使在模型收敛之后,一些参数也会有更大的梯度,这表明改变这些参数可能会使模型脱离(局部)最小值,从而导致遗忘。相反,如果所有参数梯度相似(即梯度方向均衡),则变化的参数不太可能改变模型,导致遗忘。基于这个假设,该文利用训练后的归一化梯度作为信号来指示这些危险的参数更新。SPG中提出的机制的优点是它保持了模型的灵活性,因为它没有使用重要阈值或二进制掩码完全阻塞参数。虽然HAT完全阻断重要的神经元,这导致随着时间的推移可训练参数的丧失,但SPG允许大多数参数保持“灵活”,即使它们中的大多数变化不大。此外,仅基于当前任务t的模型(
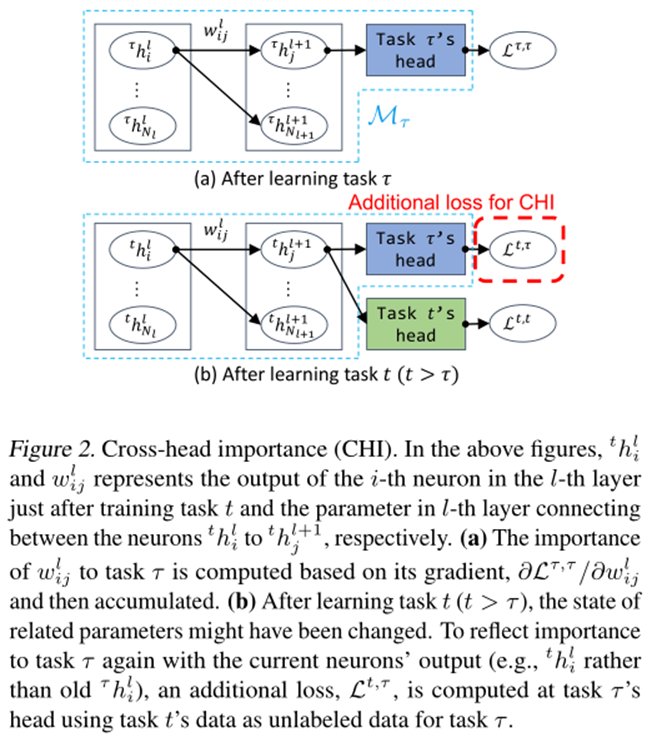
(一个向量)来表示第i层的所有参数,并且此过程不更新模型参数。在当前任务的训练已经收敛后计算重要性的原因如下:即使在模型收敛之后,一些参数也会有更大的梯度,这表明改变这些参数可能会使模型脱离(局部)最小值,从而导致遗忘。相反,如果所有参数梯度相似(即梯度方向均衡),则变化的参数不太可能改变模型,导致遗忘。基于这个假设,该文利用训练后的归一化梯度作为信号来指示这些危险的参数更新。SPG中提出的机制的优点是它保持了模型的灵活性,因为它没有使用重要阈值或二进制掩码完全阻塞参数。虽然HAT完全阻断重要的神经元,这导致随着时间的推移可训练参数的丧失,但SPG允许大多数参数保持“灵活”,即使它们中的大多数变化不大。此外,仅基于当前任务t的模型(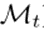 )计算梯度并不能处理另一个问题。如使用图2所示的示例(例如,在学习任务τ之后,计算一个参数的梯度,并在待积累的同一层参数之间进行归一化。尽管在学习任务t
(t > τ)期间,考虑到参数的累积重要性,参数的变化并不大,但在学习任务t结束时,相关参数的状态可能已经发生了变化,从而使归一化的重要性变得不那么有用)。为了在当前网络状态下再次反映参数对任务τ的重要性,该文引入了交叉头重要性(CHI)机制。最后,对于当前任务头部计算的归一化重要性和CHI中先前任务头部计算的归一化重要性都通过取逐元素最大值来考虑,如式(4)所示。综上所述,该方法利用每个任务τ的模型(1≤τ≤t)
)计算梯度并不能处理另一个问题。如使用图2所示的示例(例如,在学习任务τ之后,计算一个参数的梯度,并在待积累的同一层参数之间进行归一化。尽管在学习任务t
(t > τ)期间,考虑到参数的累积重要性,参数的变化并不大,但在学习任务t结束时,相关参数的状态可能已经发生了变化,从而使归一化的重要性变得不那么有用)。为了在当前网络状态下再次反映参数对任务τ的重要性,该文引入了交叉头重要性(CHI)机制。最后,对于当前任务头部计算的归一化重要性和CHI中先前任务头部计算的归一化重要性都通过取逐元素最大值来考虑,如式(4)所示。综上所述,该方法利用每个任务τ的模型(1≤τ≤t)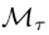 计算第i层参数θ_i的归一化重要性
计算第i层参数θ_i的归一化重要性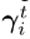 ,如公式(1)~(4)所示:其中max(·)和
,如公式(1)~(4)所示:其中max(·)和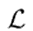 分别表示元素最大值和损失函数。式(1)对同一层的梯度进行归一化处理,以避免不同层间梯度幅度差异大造成的差异。对于当前任务的头部(即τ = t),在式(2)中使用正态损失函数(例如交叉熵)作为
分别表示元素最大值和损失函数。式(1)对同一层的梯度进行归一化处理,以避免不同层间梯度幅度差异大造成的差异。对于当前任务的头部(即τ = t),在式(2)中使用正态损失函数(例如交叉熵)作为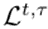 。为了尽可能避免遗忘,该文取累积的重要性
。为了尽可能避免遗忘,该文取累积的重要性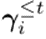 为:其中,全零向量被用作
为:其中,全零向量被用作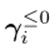 。这个
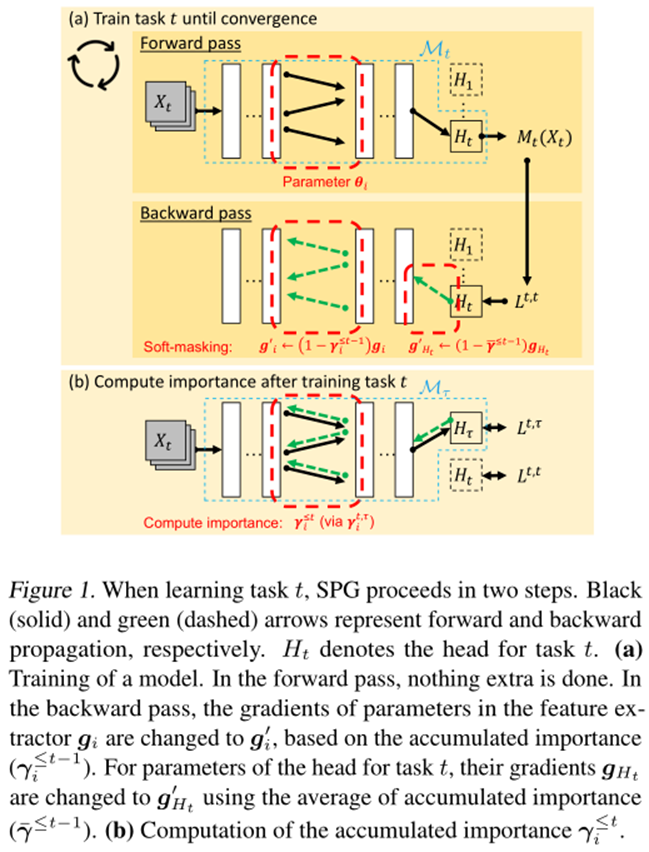
。这个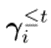 描述了每个参数对所有学习任务的重要性。这个过程如图1(a)所示。为了抑制学习任务t中向后传递重要参数的更新,根据累积重要度对共享特征提取器中所有参数的梯度进行如下修改(即软掩码),即每个参数根据其累积重要度进行不同量的软掩码:其中,
描述了每个参数对所有学习任务的重要性。这个过程如图1(a)所示。为了抑制学习任务t中向后传递重要参数的更新,根据累积重要度对共享特征提取器中所有参数的梯度进行如下修改(即软掩码),即每个参数根据其累积重要度进行不同量的软掩码:其中,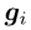 和
和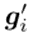 分别表示第i层参数的原始梯度和修改后的参数梯度,这两个参数将分别用于实际优化。
分别表示第i层参数的原始梯度和修改后的参数梯度,这两个参数将分别用于实际优化。2.3. 分类头的软掩码
该文发现上述软掩码可能会引起另一个问题。如果只对特征提取器的参数进行了软请求,则模型将主要通过更新分类头来寻找最优解,因为分类头的参数没有被掩码,因此比特征提取器更容易更新。然而,这阻碍了特征提取器的学习,从而阻碍了知识的转移。为了实现特征提取器和分类头部的平衡训练,该文需要根据特征提取器的参数被软掩码的程度,通过减小头部参数的梯度来减缓头部的学习速度。该文仍然使用软掩码的想法,但将头部的所有参数都设为平等软掩码。具体来说,任务t头部中所有参数的梯度被特征提取器中所有参数的累积重要度的平均值(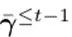 )软掩码。修正后的梯度
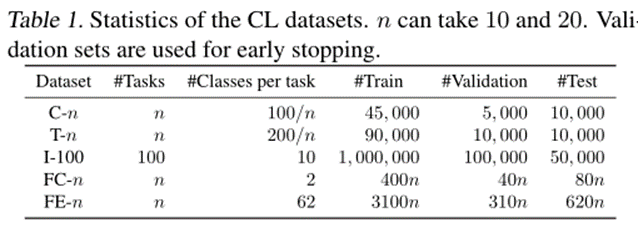
)软掩码。修正后的梯度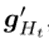 用于优化。该文使用5个CL数据集对提出的SPG进行了评估。其统计数据如表1所示。该文使用“-n”来描述从每个数据集创建n个任务(n需要10或20个)。前三个数据集中的类按任务划分,因此每个任务都有一组不相交的类。另一方面,最后两个数据集中的所有任务都具有相同的类集。该文将前一种数据集中的任务称为“异类任务”,其中CF是需要解决的关键问题,而将后一种数据集中的任务称为“相似任务”,其中知识转移能力更为重要。(1)准确率:学习最终任务后,数据集所有任务的准确率的平均值。它由
用于优化。该文使用5个CL数据集对提出的SPG进行了评估。其统计数据如表1所示。该文使用“-n”来描述从每个数据集创建n个任务(n需要10或20个)。前三个数据集中的类按任务划分,因此每个任务都有一组不相交的类。另一方面,最后两个数据集中的所有任务都具有相同的类集。该文将前一种数据集中的任务称为“异类任务”,其中CF是需要解决的关键问题,而将后一种数据集中的任务称为“相似任务”,其中知识转移能力更为重要。(1)准确率:学习最终任务后,数据集所有任务的准确率的平均值。它由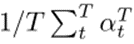 计算,其中T是任务总数。(2)前向迁移:这衡量的是对以前任务的学习对当前任务的学习有多大贡献,由
计算,其中T是任务总数。(2)前向迁移:这衡量的是对以前任务的学习对当前任务的学习有多大贡献,由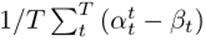 计算。(3)向后迁移:衡量当前任务的学习如何影响前一个任务的表现,它是由
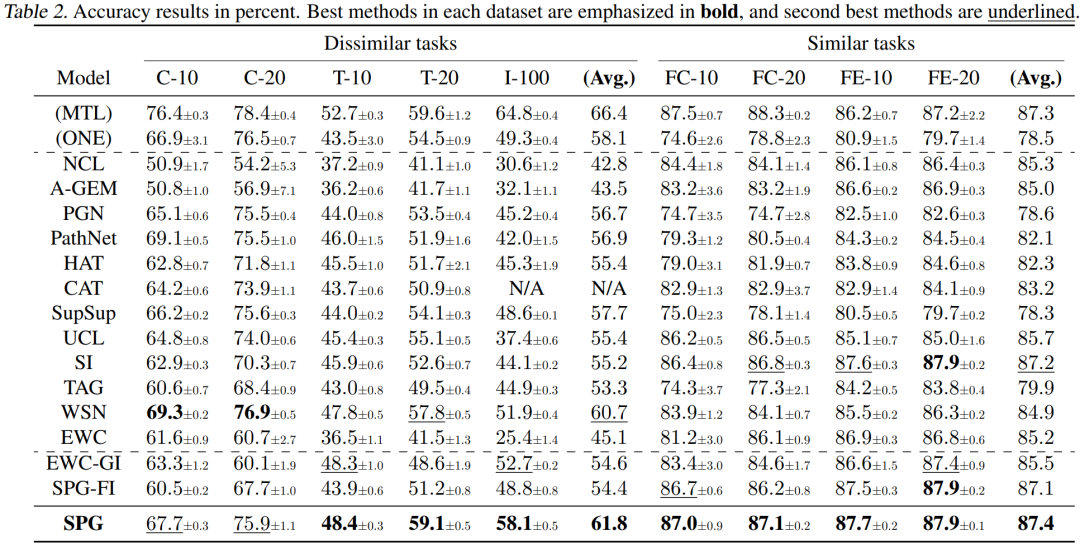
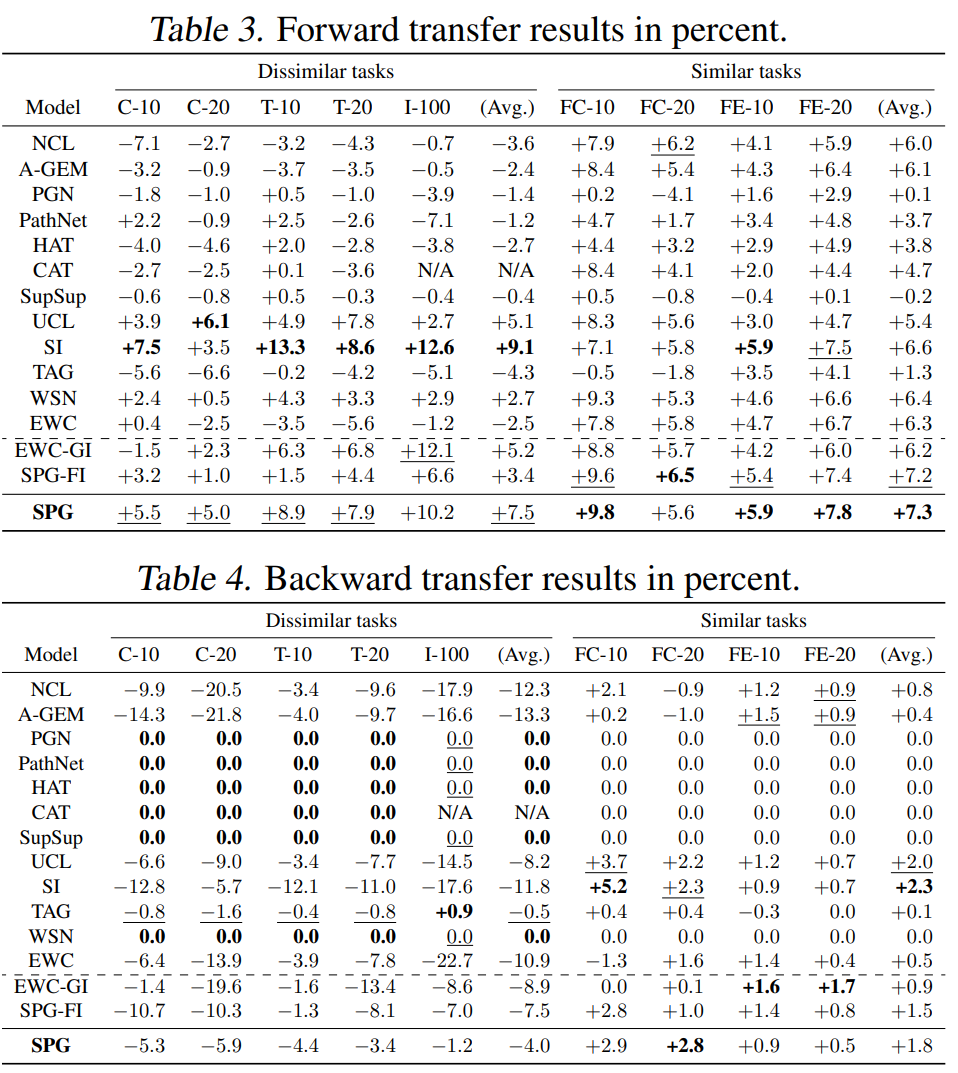
计算。(3)向后迁移:衡量当前任务的学习如何影响前一个任务的表现,它是由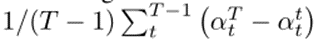 计算。实验结果如表2,3,4所示,从表2,3,4中可以看出SPG的表现大多优于所有基线。尽管SPG在C-10中的表现不如PathNet,但由于PathNet的容量问题,它在其他设置中的准确性明显较低。基于正则化的方法与该文所做的工作密切相关。但EWC、SI和UCL等代表性方法由于CF严重,且正向迁移无法补偿CF,因此性能较差。TAG虽然几乎没有CF,但正向迁移有限,最终精度较差。虽然SPG在C-10和C-20上的表现略低于WSN,但在其他不同任务数据集上,SPG的表现优于所有基线;特别是,在更现实和更困难的数据集I-100中,SPG明显更好,比WSN高出6.2%
计算。实验结果如表2,3,4所示,从表2,3,4中可以看出SPG的表现大多优于所有基线。尽管SPG在C-10中的表现不如PathNet,但由于PathNet的容量问题,它在其他设置中的准确性明显较低。基于正则化的方法与该文所做的工作密切相关。但EWC、SI和UCL等代表性方法由于CF严重,且正向迁移无法补偿CF,因此性能较差。TAG虽然几乎没有CF,但正向迁移有限,最终精度较差。虽然SPG在C-10和C-20上的表现略低于WSN,但在其他不同任务数据集上,SPG的表现优于所有基线;特别是,在更现实和更困难的数据集I-100中,SPG明显更好,比WSN高出6.2%
为了克服在持续学习中平衡灾难性遗忘和知识转移的困难,该文提出了一种新颖而简单的方法,称为SPG,它不是完全地而是部分地阻止/掩盖参数,从而使模型具有更大的灵活性和学习能力。所提出的软掩码机制不仅克服了CF,而且实现了知识的自动迁移。尽管它在概念上与正则化方法相关,但正如该文所讨论和评估的那样,它明显优于正则化方法。并且通过大量的实验表明,SPG明显优于所有强基线。[1] Serra J, Suris D, Miron M, et al. Overcoming
catastrophic forgetting with hard attention to the task[C]//International
conference on machine learning. PMLR, 2018: 4548-4557.[2]
Ke Z, Liu B, Huang X. Continual learning of a mixed sequence of similar and
dissimilar tasks[J]. Advances in Neural Information Processing Systems, 2020,
33: 18493-18504.[3]
Kirkpatrick J, Pascanu R, Rabinowitz N, et al. Overcoming catastrophic
forgetting in neural networks[J]. Proceedings of the national academy of
sciences, 2017, 114(13): 3521-3526.论文链接:https://arxiv.org/pdf/2306.14775.pdf代码链接:https://github.com/UIC-Liu-Lab/spg转载与合作,请加助手微信/131 8805 0268
内容中包含的图片若涉及版权问题,请及时与我们联系删除




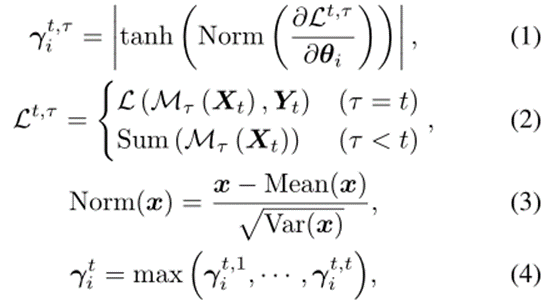
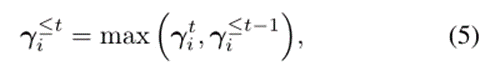
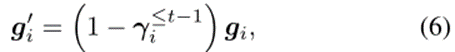
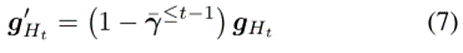


评论
沙发等你来抢