

你知道的有关于代码编辑的大模型工具有哪些呢?
推特用户 @lvwerra 制作了下面这张图,为大家梳理代码大家庭的大部分成员。
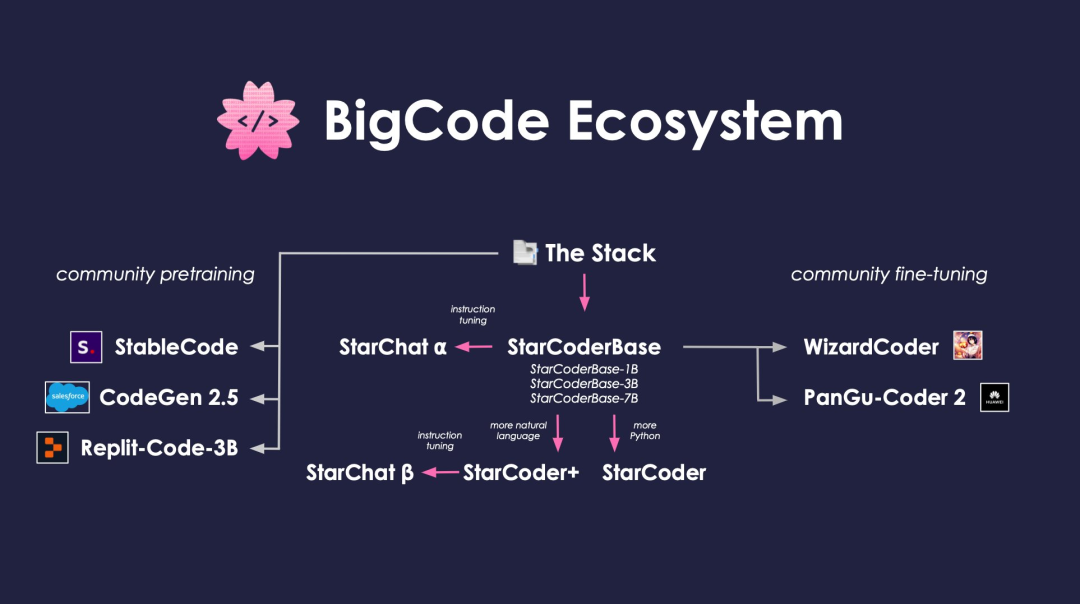
就在他发布了这张图后的两周内,又有三位新成员加入了这个大家庭,它们分别是 DeciCoder、OctoCoder 以及最新的成员 SQLCoder。
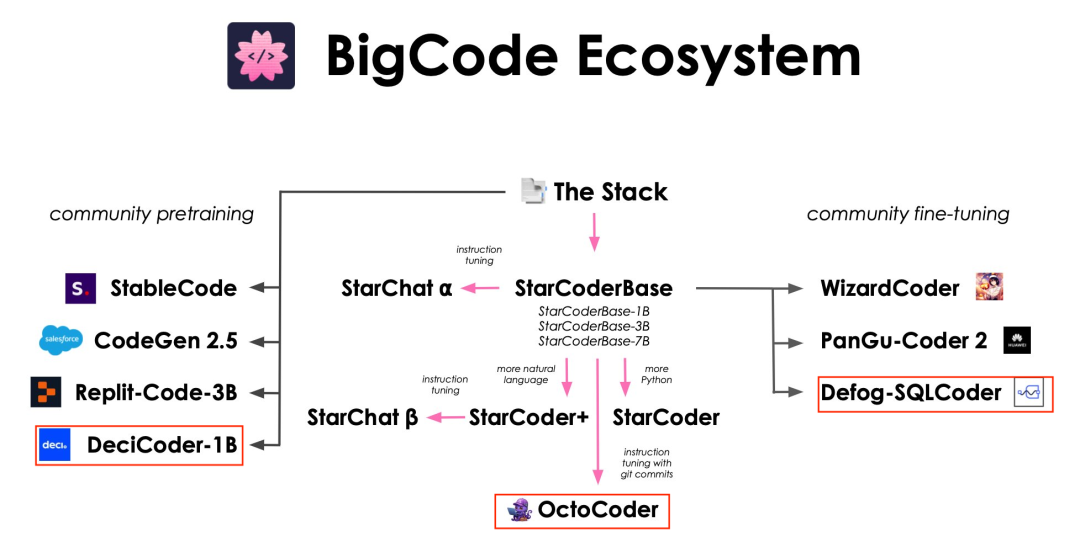
其中,这个最新成员 SQLCoder 不仅性能出色,并且已经开源了!
SQLCoder
作为一个 SOTA 大型语言模型, SQLCoder 将自然语言问题转换为 SQL 查询。在开发者的开源评估框架 SQLEval 中,SQLCoder 的性能明显优于所有主要的开源模型,并且优于 OpenAI 的 GPT-3.5。
SQLCoder 是一个 15B 参数的 LLM,也是 StarCoder 的微调实现。SQLCoder 在手工制作的 SQL 查询上进行了微调,难度依次递增。在针对单个数据库模式进行微调时,它的性能可与 GPT-4 媲美,甚至更胜一筹。
在过去的三个月里,SQLCoder 已经部署在了医疗、金融等企业中。这些企业通常拥有敏感数据,他们不希望这些数据从自有服务器中流出,因此利用自托管模型是他们使用 LLM 的唯一途径。
方法
创建数据集
作者创建了一个手工编辑的 prompt - 补全对数据集,重点是文本到 SQL 任务。该数据集由 10 个不同的模式创建,问题难度各不相同。此外,他们还从 7 个新模式中创建了一个包含 175 个问题的评估数据集。
他们确保在训练数据集和评估数据集中都选择了有 4-20 张表的复杂模式,这是因为只有 1 或 2 个表的模式由于关系有限,往往只能进行简单直接的查询。
问题分类
数据集创建后,作者将数据集中的每个问题分为易、中、难、特难四类。这种分类通过调整 Spider 数据集使用的标准来完成,以衡量 SQL 难度。最后,他们将数据集分为两个不同的子部分,分别是简单问题和中等问题,以及难题和超难题。
微调
作者分以下两个阶段对模型进行了微调。
首先,仅在简单和中等难度的问题上对 StarCoder 基础模型进行了微调。
其次,在难题和超难题上对得到的模型(代码为 defog-easy)进行微调,从而得到 SQLcoder。
评估
作者在自己创建的自定义数据集上对模型进行了评估。评估 SQL 查询的正确性非常困难,他们曾考虑使用 GPT-4 作为 评估标准,但遇到了很多问题。过程中他们还意识到,两个不同的 SQL 查询可能都正确。
对于 「谁是最近 10 个来自多伦多的用户 」这个问题,以下两种查询方式都是正确的。
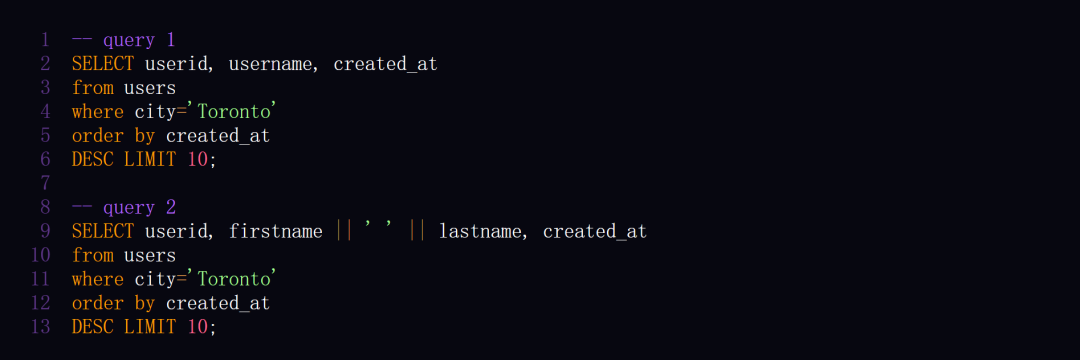
鉴于此,作者建立了一个自定义框架来评估查询的正确性。他们不仅开源了模型权重,同样开源了评估框架与评估数据集。
发布数据集的目的是丰富可用基准,帮助研究人员和工程师更好地了解文本到 SQL 生成模型的性能,特别是该模型对返回结果中的无害变化(如列重命名、附加列和重新排序)的稳健性。

更多关于评估的细节请参见博客内容:https://defog.ai/blog/open-sourcing-sqleval/
性能
在评估框架中,Defog SQLCoder 的表现优于除 GPT-4 之外的所有主要模型。特别地,它的性能超过了 gpt-3.5-turbo 和 text-davinci-003,而这两个模型的大小是它的 10 倍以上。
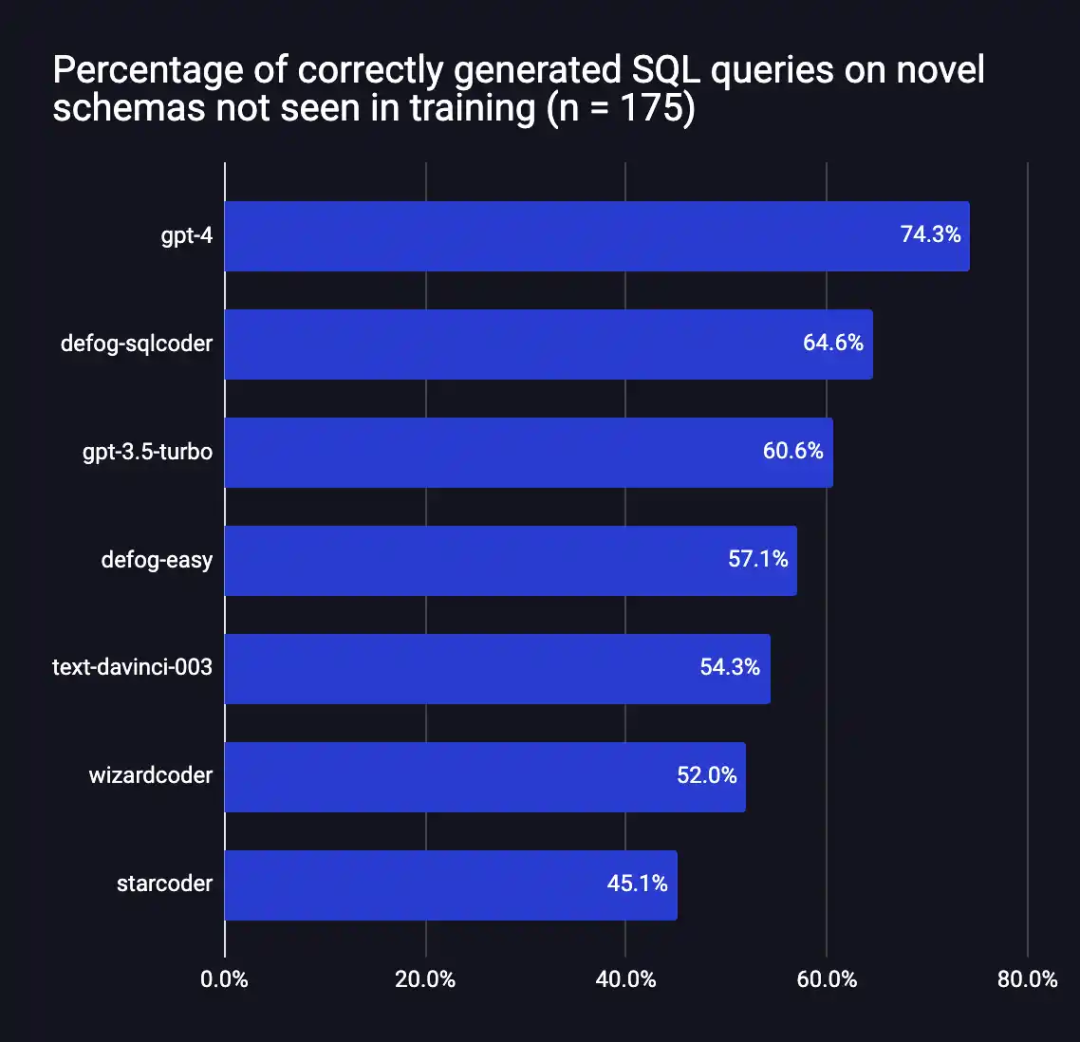
这些结果针对的是通用 SQL 数据库,并不反映 SQLCoder 在单个数据库模式上的性能。在对单个数据库模式进行微调时,SQLCoder 的性能与 OpenAI 的 GPT-4 相同或更好,延迟更低(在 A100 80GB 上)。
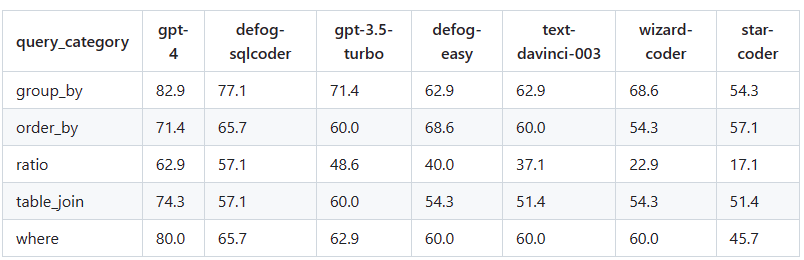
将每个生成的问题分为 5 类,按类别显示了每个模型正确回答问题的百分比。
SQLCoder 的硬件要求
SQLCoder 已在带权重的 A100 40GB GPU 上进行了测试。你还可以在 20GB 或更大内存的消费级 GPU(如 RTX 4090、RTX 3090 以及 20GB 或更大内存的苹果 M2 Pro、M2 Max 或 M2 Ultra 芯片)上加载该模型的 8 位和 4 位量化版本。
接下来的工作
未来几周,作者将对 SQLCoder 进行以下更新:
-
利用更多人工收集的数据和更广泛的问题对模型进行训练;
-
利用奖励建模和 RLHF 进一步调整模型;
-
从头开始预训练一个专门从事数据分析的模型(SQL + Python)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢