
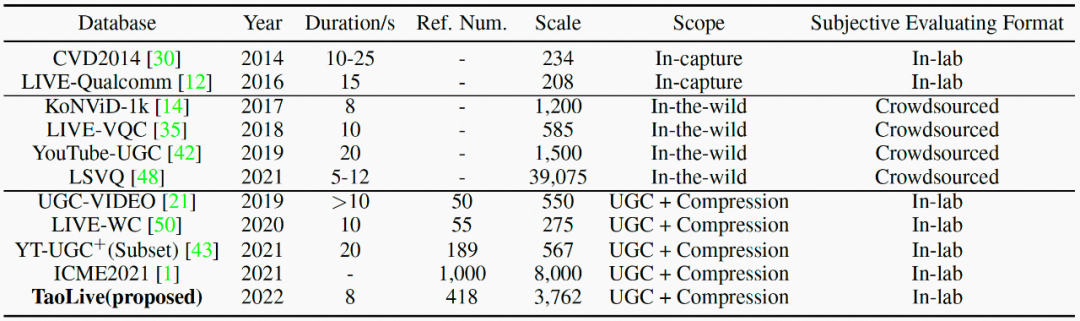
作者 |


大淘宝音视频技术团队基于淘宝直播、逛逛等内容业务,构建了大规模UGC视频质量评价数据集 —— TaoLive,包含3,762个视频,覆盖不同的内容、失真、和质量,并通过专业的主观标注,获取165,528个视频的主观质量标签。在此之上,大淘宝音视频技术团队自研了一种针对UGC视频的无参考视频质量评价模型 ——MD-VQA(Multi-Dimensional Video Quality Assessment),综合视频的语义、失真、运动等多维度信息,并进行时空域的融合,来衡量视频绝对质量的高低。在公开的视频质量评价数据集LIVE-WC和YT-UGC+,以及TaoLive上,MD-VQA在主流视频质量评价指标SRCC和PLCC上均超过了SOTA(State-Of-The-Art)方法,达到了先进性能。

针对上述问题,我们基于淘宝直播平台的视频,构建了大规模UGC视频质量评价数据集 —— TaoLive,包含3,762个直播视频,覆盖不同的内容和质量,并通过专业的主观打分,获取165,528个主观质量分数的标注数据。与此同时,我们自研了针对UGC视频的无参考视频质量评价模型 —— MD-VQA,综合视频的语义、失真、和运动等多维特征,并进行时空域的融合,来衡量视频绝对质量的高低。
▐ TaoLive数据集
我们从淘宝直播平台筛选了418条视频,覆盖美妆、服饰、珠宝、食品、生活日常等不同内容、以及720p和1080p两个主流分辨率。然后,我们对这些视频进行8种不同失真等级的编码,来模拟实际应用中不同的视频质量,最后共生成3,762条不同内容、不同质量的视频,用来验证我们提出的MD-VQA的模型性能。部分示例视频如图1。

▐ 模型设计
图2示出了所提出的 MD-VQA 模型的框架,包括特征提取模块、特征融合模块、和特征回归模块。具体来说,所提取的视频特征包括多个维度:语义、失真、和运动。特别地,我们利用相邻帧特征之间的绝对误差来反映视频质量在时域上波动。上述得到的多维特征在时空域上被融合,并通过特征回归模块映射到最终的质量分数。
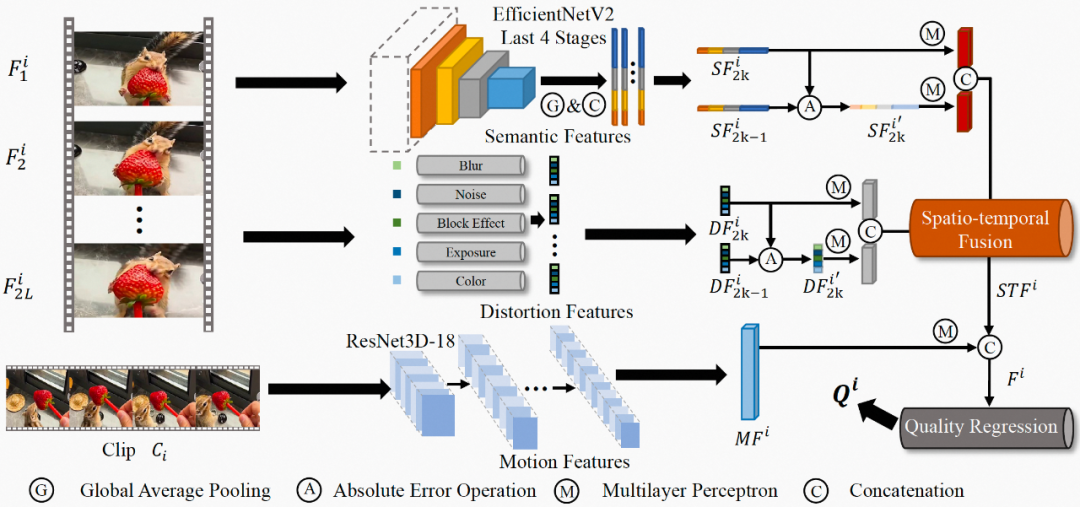
语义特征提取
视频语义特征通常描述视频中物体的物理特性、物体之间的时空关系、以及物体的内容信息等,属于视频的高维特征,且和视频的低维特征(如亮度、色彩、纹理等)存在很强的关联性。此外,对于不同的视频内容,语义特征的失真对人眼感知到的视频质量有着不同的影响:人眼通畅无法容忍纹理丰富的内容(例如草坪、地毯)的模糊,二队纹理简单的内容(例如天空、墙面)的模糊相对不敏感。综上考虑,我们利用从预训练的EfficientNetV2 [3] 网络最后4层中提取的多维度特征作为帧级的语义特征,如图3公式所示:
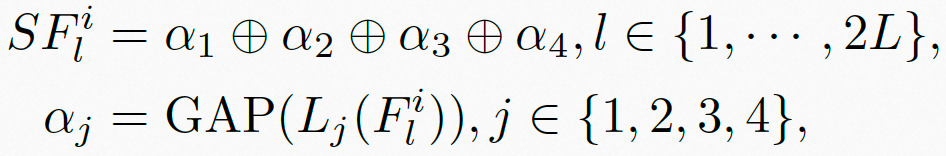
其中,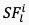 表示从第
表示从第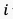 个视频片段的第帧获取的语义特征,
个视频片段的第帧获取的语义特征,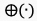 表示级联算子,
表示级联算子,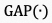 表示全局平均池化算子,
表示全局平均池化算子,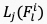 表示EfficientNetV2第
表示EfficientNetV2第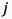 层的特征图,
层的特征图,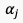 表示从
表示从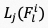 获取的平均池化特征。
获取的平均池化特征。
失真特征提取
由于UGC视频中普遍存在多种失真,仅使用语义特征来表征视频质量是不充分的。此外,对于不同的压缩质量,失真会呈现不同的状态,例如在压缩质量相对较低时,模糊会比较明显,但噪声也同时被抑制。因此,在考虑高维的语义特征的同时,我们引入了低维的手工(hand-crafted)特征,包括模糊、噪声、块效应、曝光强度、以及色彩,然后将上述特征综合为帧级的失真特征,如图4公式所示:
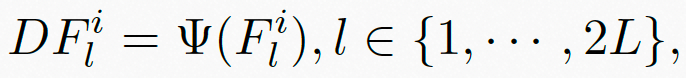
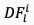 表示从第
表示从第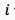 个视频片段的第帧获取的失真特征,
个视频片段的第帧获取的失真特征,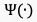 表示失真特征提取算子。
表示失真特征提取算子。运动特征提取
运动失真通常源自于拍摄时的抖动、或者低码率的视频编码,并且,其无法被视频空域特征(例如前述的语义特征)有效地描述。因此,为了提高模型的准确度,我们利用预训练的ResNet3D-18 [4] 获取帧级的运动特征,如图5公式所示:
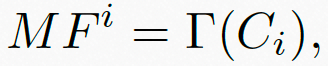
其中,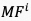 表示从第个视频片段获取的运动特征,
表示从第个视频片段获取的运动特征,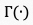 表示运动特征提取算子。
表示运动特征提取算子。
特征融合
根据 [5] 中所述,高质量视频通常具有更小的帧间质量波动,反之亦然。为了量化上述波动,我们使用帧间语义特征和失真特征的绝对误差来衡量帧间质量波动,如图6公式所示:
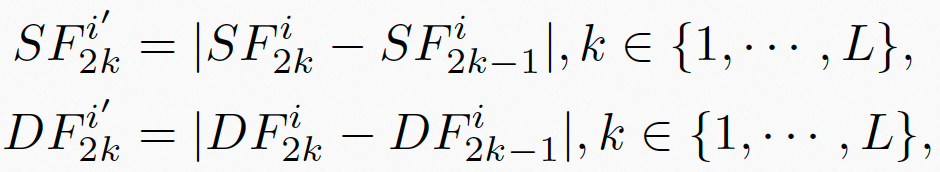
图6. 相邻帧的语义特征的绝对误差和失真特征的绝对误差
其中,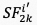 和
和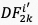 分别表示相邻帧的语义特征的绝对误差,以及失真特征的绝对误差。
分别表示相邻帧的语义特征的绝对误差,以及失真特征的绝对误差。
基于此,时空域特征可以利用图7中的公式进行融合:
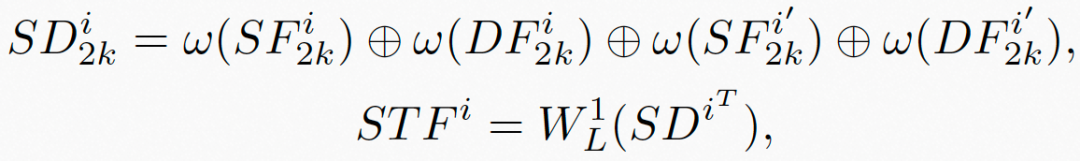
其中,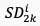 表示帧级的时空域特征,
表示帧级的时空域特征,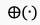 表示级联算子,
表示级联算子,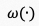 表示可学习多层感知机,
表示可学习多层感知机,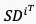 表示
表示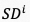 的转置,
的转置,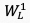 表示可学习的线性映射算子,将
表示可学习的线性映射算子,将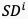 映射到最终的时空域融合特征
映射到最终的时空域融合特征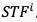 。
。
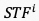 与运动特征
与运动特征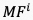 进一步融合,形成最终的时空域融合特征
进一步融合,形成最终的时空域融合特征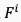 ,如图8公式所示:
,如图8公式所示: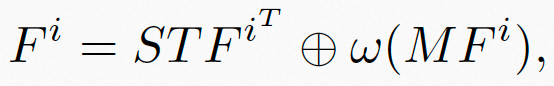
特征回归
基于上述时空域融合特征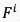 ,我们利用三层全连接层来回归视频质量,如图9公式所示:
,我们利用三层全连接层来回归视频质量,如图9公式所示:
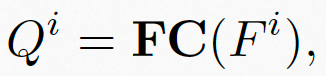
其中,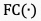 表示全连接层,
表示全连接层,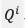 表示视频片段的质量。
表示视频片段的质量。
此外,我们使用均方误差MSE(Mean Squared Error)作为损失函数,如图10公式所示:
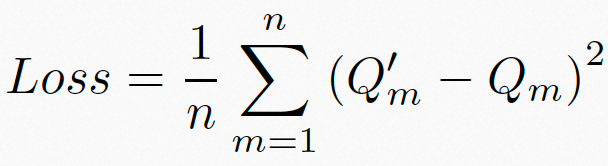
其中,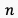 表示mini-batch的视频数量,
表示mini-batch的视频数量,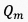 和
和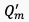 分别表示预测的视频质量和实际的视频质量。完整视频的质量可通过对视频片段进行平均池化操作获得。
分别表示预测的视频质量和实际的视频质量。完整视频的质量可通过对视频片段进行平均池化操作获得。

实验
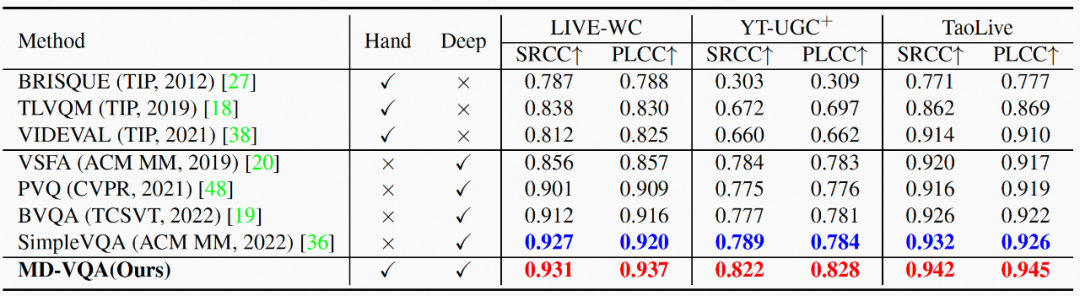
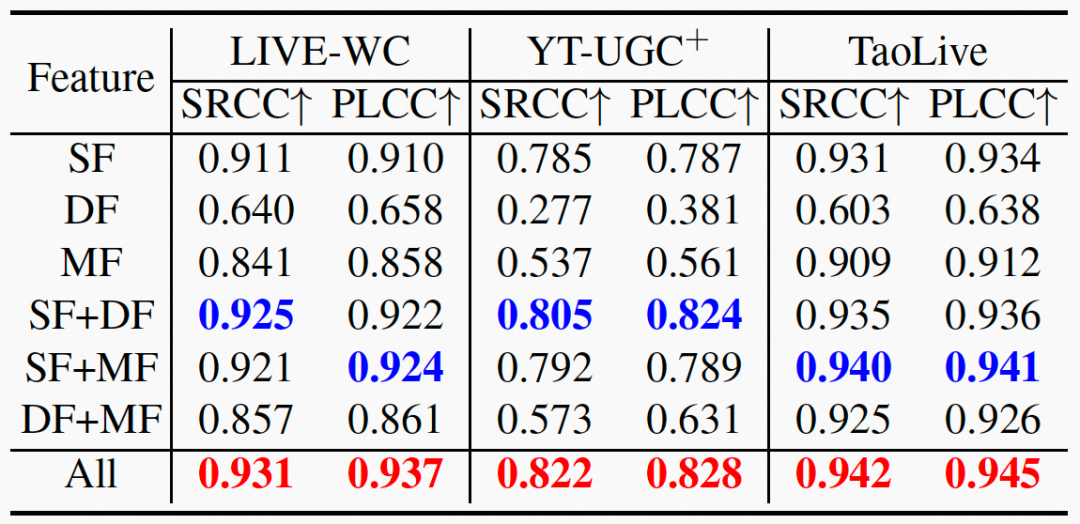
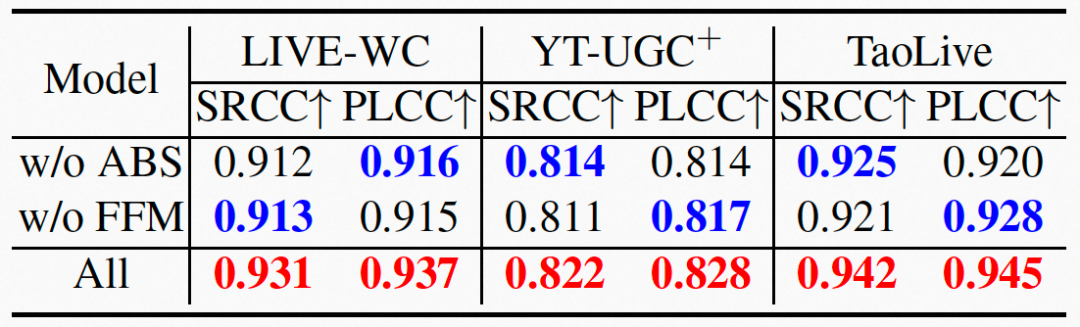
我们在两个公开的视频质量评价数据集LIVE-WC和YouTube-UGC,以及我们自建的TaoLive数据集上,与现有SOTA方法进行了对比。我们使用Spearman Rank Order Correlation Coefficient(SRCC)和Pearson Linear Correlation Coefficient(PLCC)作为指标进行对比。更高的SRCC表示样本间更好的保序性,更高的PLCC表示与标注分数更好地拟合程度。结果如表2所示。

总结
为了准确、高效地衡量UGC视频的绝对质量,我们构建了大规模UGC视频质量评价数据集 —— TaoLive。不同于常见的视频质量评价数据集使用高质量视频作为源视频,TaoLive 数据集收集了3,762个UGC源视频,覆盖不同的内容和质量,并通过专业的主观打分,获取165,528个主观质量分数的标注数据。此外,我们提出一个无参考视频质量评价模型 —— MD-VQA,综合视频的语义、失真、和运动等多维特征,并进行时空域的融合,来衡量视频绝对质量的高低。实验结果表明,MD-VQA在主流视频质量评价数据集和评价指标上,均超过了现有方法,达到了先进性能。
MD-VQA已经全面应用于包括淘宝直播、逛逛在内的大淘宝内容业务,监控视频业务的大盘画质的变化,快速、精准地筛选出不同画质水位的直播间和短视频,配合淘宝自研S265编码器、视频增强算子集STaoVideo以及《电商直播高画质开播指南》[1] 等,帮助提升平台内容画质。

【1】 “服贸会在京举行|淘宝直播携手佳能佳直播联合发布《电商直播高画质开播指南》让品质直播触手可及”,https://mp.weixin.qq.com/s/2-pC1Z9wH60DHpUkCU-_ng.
【2】 RECOMMENDATION ITU-R BT. Methodology for the subjective assessment of the quality of television pictures. International Telecommunication Union, 2002.
【3】 Mingxing Tan and Quoc Le. Efficientnetv2: Smaller models and faster training. In International Conference on Machine Learning, pages 10096–10106. PMLR, 2021.
【4】 Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. Can spatio-temporal 3d cnns retrace the history of 2d cnns and imagenet? In IEEE/CVF CVPR, pages 6546–6555, 2018.
【5】Manish Narwaria, Weisi Lin, and Anmin Liu. Low-complexity video quality assessment using temporal quality variations. IEEE TMM, 14(3):525–535, 2012.

该工作主要在大淘宝技术的音视频技术团队的带领下完成,该团队依托淘宝直播、逛逛、手淘首页信息流等内容业务,致力于打造行业领先的音视频技术。团队成员来自海内外知名高校,先后在MSU世界编码器大赛,NTIRE视频增强超分竞赛这样的领域强相关权威赛事上夺魁,并重视与学界的合作与交流。
这项工作的合作方为上海交通大学张文军教授领衔的图像所团队,是数字电视广播及数字媒体处理与传输领域的主要研究力量之一。面向国家战略性新兴产业,顺应网络化、融合化的发展趋势,近年来开展的重点研究领域包括智能媒体融合网络、视频智能分析处理与传输等。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢