
点击下方卡片,关注“OpenCV与AI深度学习”
视觉/图像重磅干货,第一时间送达!
导 读
本文主要介绍基于DeepSORT和TorchVision检测器实现实时目标跟踪实例。
背景介绍
在实际应用中,跟踪是对象检测中最重要的组成部分之一。如果没有跟踪,实时监控和自动驾驶系统等应用就无法充分发挥其潜力。无论是人还是车辆,物体跟踪都起着重要作用。然而,测试大量的检测模型和重识别模型是很麻烦的。为此,我们将使用DeepSORT和Torchvision检测器来简化实时跟踪的过程。
什么是Re-ID模型
在我们深入编码部分之前,我们先讨论一下重识别模型(简称Re-ID)。
Re-ID 模型帮助我们跟踪具有相同ID的不同帧中的同一对象。在大多数情况下,Re-ID 模型基于深度学习,非常擅长从图像和帧中提取特征。Re-ID 模型是在重识别数据集上进行预训练的。在训练过程中,他们学习同一个人在不同角度和不同照明条件下的样子。训练后,我们可以使用权重对视频帧中的人进行实时重新识别。
但是如果我们想要跟踪人以外的其他东西怎么办?
尽管建议在跟踪人员时使用人员重新识别模型,但我们可以使用任何大型预训练模型,例如,如果我们想在视频帧中跟踪和重新识别汽车。对于这种情况,我们没有针对汽车训练的 Re-ID 模型。但是,我们可以为此使用 ImageNet 预训练模型。由于该模型已经接受了数百万张图像的训练,因此它将能够轻松提取汽车的特征。
同样,我们也可以使用基础图像模型(例如 CLIP ResNet50)进行 Re-ID。我们将在本文中使用此类模型。
当将 Re-ID 模型与对象检测模型结合使用时,该过程分为两个阶段。尽管进行检测、跟踪和重新识别的单级跟踪器变得越来越普遍,但我们仍然有单独的 Re-ID 模型的用例。
为什么需要Re-ID模型
Re-ID 模型有很多优势,特别是在安全性和准确性是首要任务的多摄像头设置中。
多摄像头设置:当使用多摄像头设置来跟踪人员时,单独的 Re-ID 模型会变得非常有用。它可以跨摄像头识别同一个人的动作和特征。最终,我们可以将相同的 ID 分配给同一个人,即使他出现在不同的摄像机上。
实时Deep SORT配置
要使用 Torchvision 和 Deep SORT 中的不同检测模型,我们需要安装一些库。
其中最重要的是deep-sort-realtime图书馆。它使我们能够通过 API 调用访问深度排序算法。除此之外,它还可以从多个 Re-ID 模型中进行选择,这些模型已经在 ImageNet 等大型基础数据集上进行了预训练。这些模型还包括很多 OpenAI CLIP 图像模型和模型。torchreid
在执行以下步骤之前,请确保您已安装PyTorch 和 CUDA。
要安装该 deep-sort-realtime库,请在选择的环境中执行以下命令:
pip install deep-sort-realtime这使我们能够访问深度排序算法和一个内置的 mobilenet Re-ID 嵌入器。
但如果我们想要访问 OpenAI CLIP Re-ID 和torchreid嵌入器,那么我们需要执行额外的步骤。
要使用 CLIP 嵌入器,我们将使用以下命令安装 OpenAI CLIP 库:
pip install git+https://github.com/openai/CLIP.git这允许我们使用多个CLIP ResNet和Vision Transformer模型作为嵌入器。
最后的步骤包括安装torchreid 库,以防我们想使用它们的嵌入器作为 Re-ID 模型。但是,请注意,该库提供了专门为人员重新识别而训练的 Re-ID 模型。如果您不打算执行此步骤,请跳过此步骤。
首先,我们需要克隆存储库并将其设为当前工作目录。您可以将其克隆到项目目录以外的目录中。
git clone https://github.com/KaiyangZhou/deep-person-reid.gitcd deep-person-reid/
接下来,检查requirements.txt文件并根据需要安装依赖项。完成后,在开发模式下安装库。
python setup.py develop完成所有安装步骤后,我们可以继续进行编码部分。完成所有安装步骤后,我们可以继续进行编码部分。
使用Torchvision的实时Deep SORT代码
深度排序实时库将在内部处理跟踪详细信息。我们的目标是创建一个模块化代码库,用于多种检测和 Re-ID 模型的快速原型设计。
我们需要的两个主要Python文件是deep_sort_tracking.py和utils.py。包含所有COCO数据集类列表的文件内容coco_classes.py如下:
COCO_91_CLASSES = ['__background__','person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus','train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign','parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow','elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A','handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball','kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket','bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl','banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza','donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table','N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone','microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book','clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
这将用于映射类索引和类名称。
深度排序跟踪代码
这deep_sort_tracking.py是我们将从命令行运行的可执行脚本。
它处理检测模型、Re-ID 模型和我们想要跟踪的类。
代码将进一步阐明这一点。让我们从导入语句和参数解析器开始。
import torchimport torchvisionimport cv2import osimport timeimport argparseimport numpy as npfrom torchvision.transforms import ToTensorfrom deep_sort_realtime.deepsort_tracker import DeepSortfrom utils import convert_detections, annotatefrom coco_classes import COCO_91_CLASSESparser = argparse.ArgumentParser()parser.add_argument('--input',default='input/mvmhat_1_1.mp4',help='path to input video',)parser.add_argument('--imgsz',default=None,help='image resize, 640 will resize images to 640x640',type=int)parser.add_argument('--model',default='fasterrcnn_resnet50_fpn_v2',help='model name',choices=['fasterrcnn_resnet50_fpn_v2','fasterrcnn_resnet50_fpn','fasterrcnn_mobilenet_v3_large_fpn','fasterrcnn_mobilenet_v3_large_320_fpn','fcos_resnet50_fpn','ssd300_vgg16','ssdlite320_mobilenet_v3_large','retinanet_resnet50_fpn','retinanet_resnet50_fpn_v2'])parser.add_argument('--threshold',default=0.8,help='score threshold to filter out detections',type=float)parser.add_argument('--embedder',default='mobilenet',help='type of feature extractor to use',choices=["mobilenet","torchreid","clip_RN50","clip_RN101","clip_RN50x4","clip_RN50x16","clip_ViT-B/32","clip_ViT-B/16"])parser.add_argument('--show',action='store_true',help='visualize results in real-time on screen')parser.add_argument('--cls',nargs='+',default=[1],help='which classes to track',type=int)args = parser.parse_args()
我们从包中导入 DeepSort 跟踪器类deep_sort_realtime,稍后我们将使用该类来初始化跟踪器。我们还从 utils 包中导入convert_detections和函数。annotate现在,我们不需要详细讨论上述两个函数。让我们在编写文件代码时讨论它们utils.py。
我们上面创建的所有参数解析器的描述:
--input:输入视频文件的路径。
--imgsz:这接受一个整数,指示图像大小应调整为的正方形。
--model:这是 Torchvision 模型枚举。我们可以从 Torchvision 的任何对象检测模型中进行选择。
--threshold:分数阈值,低于该阈值的所有检测都将被丢弃。
--embedder:我们要使用的 Re-ID 嵌入器模型。
--show:一个布尔参数,指示我们是否要实时可视化输出。
--cls:这接受我们想要跟踪的类索引。默认情况下,它仅跟踪人员。如果我们想跟踪人和自行车,我们应该提供--cls 1 2.
接下来,我们将设置种子,定义输出目录并打印有关实验的信息。
np.random.seed(42)OUT_DIR = 'outputs'os.makedirs(OUT_DIR, exist_ok=True)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")COLORS = np.random.randint(0, 255, size=(len(COCO_91_CLASSES), 3))print(f"Tracking: {[COCO_91_CLASSES[idx] for idx in args.cls]}")print(f"Detector: {args.model}")print(f"Re-ID embedder: {args.embedder}")
更进一步,我们需要加载检测模型、Re-ID 模型和视频文件。
# Load model.model = getattr(torchvision.models.detection, args.model)(weights='DEFAULT')# Set model to evaluation mode.model.eval().to(device)# Initialize a SORT tracker object.tracker = DeepSort(max_age=30, embedder=args.embedder)VIDEO_PATH = args.inputcap = cv2.VideoCapture(VIDEO_PATH)frame_width = int(cap.get(3))frame_height = int(cap.get(4))frame_fps = int(cap.get(5))frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))save_name = VIDEO_PATH.split(os.path.sep)[-1].split('.')[0]# Define codec and create VideoWriter object.out = cv2.VideoWriter(f"{OUT_DIR}/{save_name}_{args.model}_{args.embedder}.mp4",cv2.VideoWriter_fourcc(*'mp4v'), frame_fps,(frame_width, frame_height))frame_count = 0 # To count total frames.total_fps = 0 # To get the final frames per second.
正如您所看到的,我们还定义了用于定义输出文件名称的视频信息。和将帮助我们跟踪迭代frame_count的total_fps帧数以及发生推理的 FPS。
该代码文件的最后部分包括一个while用于迭代视频帧并执行检测和跟踪推理的大块。
while cap.isOpened():# Read a frameret, frame = cap.read()if ret:if args.imgsz != None:resized_frame = cv2.resize(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB),(args.imgsz, args.imgsz))else:resized_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# Convert frame to tensor and send it to device (cpu or cuda).frame_tensor = ToTensor()(resized_frame).to(device)start_time = time.time()# Feed frame to model and get detections.det_start_time = time.time()with torch.no_grad():detections = model([frame_tensor])[0]det_end_time = time.time()det_fps = 1 / (det_end_time - det_start_time)# Convert detections to Deep SORT format.detections = convert_detections(detections, args.threshold, args.cls)# Update tracker with detections.track_start_time = time.time()tracks = tracker.update_tracks(detections, frame=frame)track_end_time = time.time()track_fps = 1 / (track_end_time - track_start_time)end_time = time.time()fps = 1 / (end_time - start_time)# Add `fps` to `total_fps`.total_fps += fps# Increment frame count.frame_count += 1print(f"Frame {frame_count}/{frames}",f"Detection FPS: {det_fps:.1f},",f"Tracking FPS: {track_fps:.1f}, Total FPS: {fps:.1f}")# Draw bounding boxes and labels on frame.if len(tracks) > 0:frame = annotate(tracks,frame,resized_frame,frame_width,frame_height,COLORS)cv2.putText(frame,f"FPS: {fps:.1f}",(int(20), int(40)),fontFace=cv2.FONT_HERSHEY_SIMPLEX,fontScale=1,color=(0, 0, 255),thickness=2,lineType=cv2.LINE_AA)out.write(frame)if args.show:# Display or save output frame.cv2.imshow("Output", frame)# Press q to quit.if cv2.waitKey(1) & 0xFF == ord("q"):breakelse:break# Release resources.cap.release()cv2.destroyAllWindows()
处理每一帧后,我们将张量通过检测模型以获得检测结果。在将其传递给跟踪器之前需要detections采用检测格式。我们convert_detections()为此调用该函数。除了检测之外,检测阈值和类别索引也传递给它。
在以正确的格式获得检测结果后,我们调用update_tracks()该对象的方法tracker。
最后,我们用边界框、检测 ID 和 FPS 注释帧,并在屏幕上显示输出。除此之外,我们还显示了检测、跟踪的 FPS 以及终端上的最终 FPS。
这就是我们主脚本所需要的全部内容。但是 utils.py 文件中发生了一些重要的事情,我们接下来将对其进行分析。
用于检测和注释的实用脚本
文件中有两个函数utils.py。让我们从导入和convert_detections()函数开始。
import cv2import numpy as np# Define a function to convert detections to SORT format.def convert_detections(detections, threshold, classes):# Get the bounding boxes, labels and scores from the detections dictionary.boxes = detections["boxes"].cpu().numpy()labels = detections["labels"].cpu().numpy()scores = detections["scores"].cpu().numpy()lbl_mask = np.isin(labels, classes)scores = scores[lbl_mask]# Filter out low confidence scores and non-person classes.mask = scores > thresholdboxes = boxes[lbl_mask][mask]scores = scores[mask]labels = labels[lbl_mask][mask]# Convert boxes to [x1, y1, w, h, score] format.final_boxes = []for i, box in enumerate(boxes):# Append ([x, y, w, h], score, label_string).final_boxes.append(([box[0], box[1], box[2] - box[0], box[3] - box[1]],scores[i],str(labels[i])))return final_boxes
该convert_detections()函数接受模型的输出,并仅返回我们想要跟踪的那些类框和标签。对于每个对象,跟踪器库需要一个包含格式边界框 x, y, w, h、分数和标签索引的元组。我们将其存储在final_boxes列表中并在最后返回。
该annotate()函数接受跟踪器输出和帧信息。
# Function for bounding box and ID annotation.def annotate(tracks, frame, resized_frame, frame_width, frame_height, colors):for track in tracks:if not track.is_confirmed():continuetrack_id = track.track_idtrack_class = track.det_classx1, y1, x2, y2 = track.to_ltrb()p1 = (int(x1/resized_frame.shape[1]*frame_width), int(y1/resized_frame.shape[0]*frame_height))p2 = (int(x2/resized_frame.shape[1]*frame_width), int(y2/resized_frame.shape[0]*frame_height))# Annotate boxes.color = colors[int(track_class)]cv2.rectangle(frame,p1,p2,color=(int(color[0]), int(color[1]), int(color[2])),thickness=2)# Annotate ID.cv2.putText(frame, f"ID: {track_id}",(p1[0], p1[1] - 10),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0, 255, 0),2,lineType=cv2.LINE_AA)return frame
它使用属性提取对象跟踪 ID track_id,并使用属性提取类标签det_class。然后我们用边界框和 ID 注释框架并返回它。
这就是我们编码部分所需的全部内容。在下一节中,我们将使用 Torchvision 模型进行几次深度排序跟踪实验并分析结果。
使用 Torchvision 检测模型进行深度排序跟踪 - 实验
注意:所有推理实验均在配备 GTX 1060 GPU、第 8 代 i7 CPU 和 16 GB RAM 的笔记本电脑上运行。
让我们使用默认的 Torchvision 检测模型和 Re-ID 嵌入器运行第一个深度排序推理。
python deep_sort_tracking.py --input input/video_traffic_1.mp4 --show 上述命令将使用 Faster RCNN ResNet50 FPN V2 模型以及 MobileNet Re-ID 嵌入模型运行脚本。此外,它默认只会跟踪人员。
下面是视频结果:
即使平均帧率为 2.5 FPS,结果也不错。该模型可以正确跟踪人员。值得注意的是,Faster RCNN 模型的鲁棒性甚至可以在最后几帧中检测到车内的人。
但我们能否让推理速度更快呢?是的,我们可以使用 Faster RCNN MobileNetV3 模型,它是一个轻量级检测器。我们可以将其与 MobileNet Re-ID 模型结合起来以获得出色的结果。
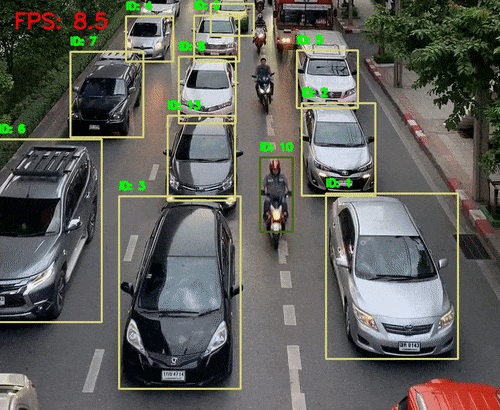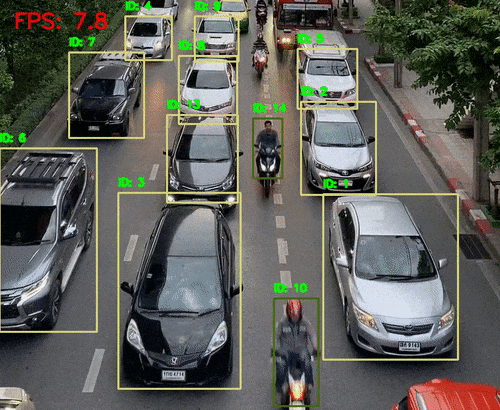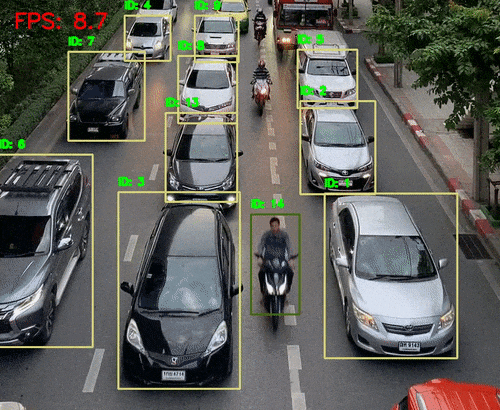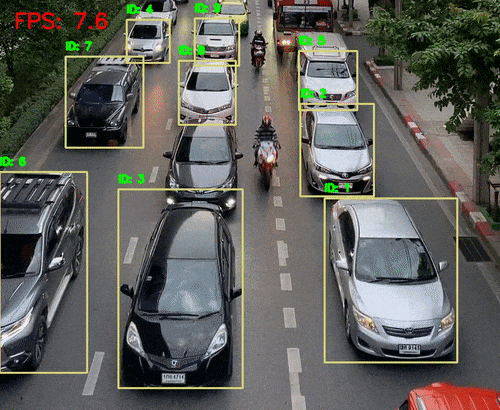
python deep_sort_tracking.py --input input/video_traffic_1.mp4 --model fasterrcnn_mobilenet_v3_large_fpn --embedder mobilenet --cls 1 3 --show这次我们提供了--cls 1 3对应于 COCO 数据集中的人和汽车的类索引。
Deep SORT 跟踪几乎以 8 FPS 运行。这主要是因为 Faster RCNN MobileNetV3 模型。结果也不错。所有汽车都会被检测到,ID 之间的切换也减少了。
接下来,我们将使用 OpenAI CLIP ResNet50 嵌入器作为 Re-ID 模型和 Torchvision RetinaNet 检测器。在这里,我们使用更加密集的交通场景,我们将在其中跟踪汽车和卡车。
python deep_sort_tracking.py --input input/video_traffic_2.mp4 --model retinanet_resnet50_fpn_v2 --embedder clip_RN50 --cls 3 8 --show --threshold 0.7结果还不错。该检测器能够检测到几乎所有的汽车和卡车,并且 Deep SORT 跟踪器正在跟踪几乎所有的汽车和卡车。然而,还有一些 ID 开关。值得注意的一件有趣的事情是,检测器有时会将远处的卡车检测为汽车。当卡车接近时,它会得到纠正。但ID不会切换。这显示了使用 Re-ID 模型的另一个用处。
对于最终实验,我们将torchreid在非常具有挑战性的环境中使用该库。默认情况下,该torchreid模型使用osnet_ain_x1_0预训练的人员 Re-ID 模型。除此之外,我们将使用 RetinaNet 检测模型。
python deep_sort_tracking.py --input input/mvmhat_1_1.mp4 --model retinanet_resnet50_fpn_v2--embedder torchreid --cls 1 --show --threshold 0.7
虽然因为RetinaNet模型的原因FPS有点低,但结果非常好。尽管多人交叉,但我们只看到两个ID开关。
结论
在本文中,我们创建了一个简单的代码库,将不同的 Torchvision 检测模型与 Re-ID 模型结合起来,以执行深度排序跟踪。结果并不完美,但尝试 Re-ID 嵌入器和对象检测器的不同组合可能会很有用。可以进一步采用这种解决方案,使用仅在车辆上进行训练的轻量级检测器来实时跟踪交通。
—THE END—
下载1:Pytorch常用函数手册
欢迎加入CV学习交流微信群!
觉得有用,记得点个赞和在看 
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢