


年初爆火的《流浪地球2》中的机械狗笨笨这一角色,想必给大家留下了深刻的印象。这只能够在各种地形移动负重、和人直接对话、做出各种可爱表情的小狗,正是具身智能体的典型代表。但显然,我们希望它更加聪明能干,比如帮助张鹏去月球手动引爆核弹,这样就可以避免这么多航天员的牺牲了。实际上,随着近期大模型的不断涌现,具身智能的发展也被极大地加速了,这一愿景也许不再是梦。
为了理解大模型的涌现对具身智能带来了哪些影响,我们首先回顾一下具身智能体的一些重要特性。它们需要具有三种核心能力,即感知、决策、执行。正如人有眼睛、鼻子、耳朵来感知世界,有大脑来做出决策,有手和腿来执行命令,只有形成这三者的有机循环,才能够完成与物理世界的各种交互。
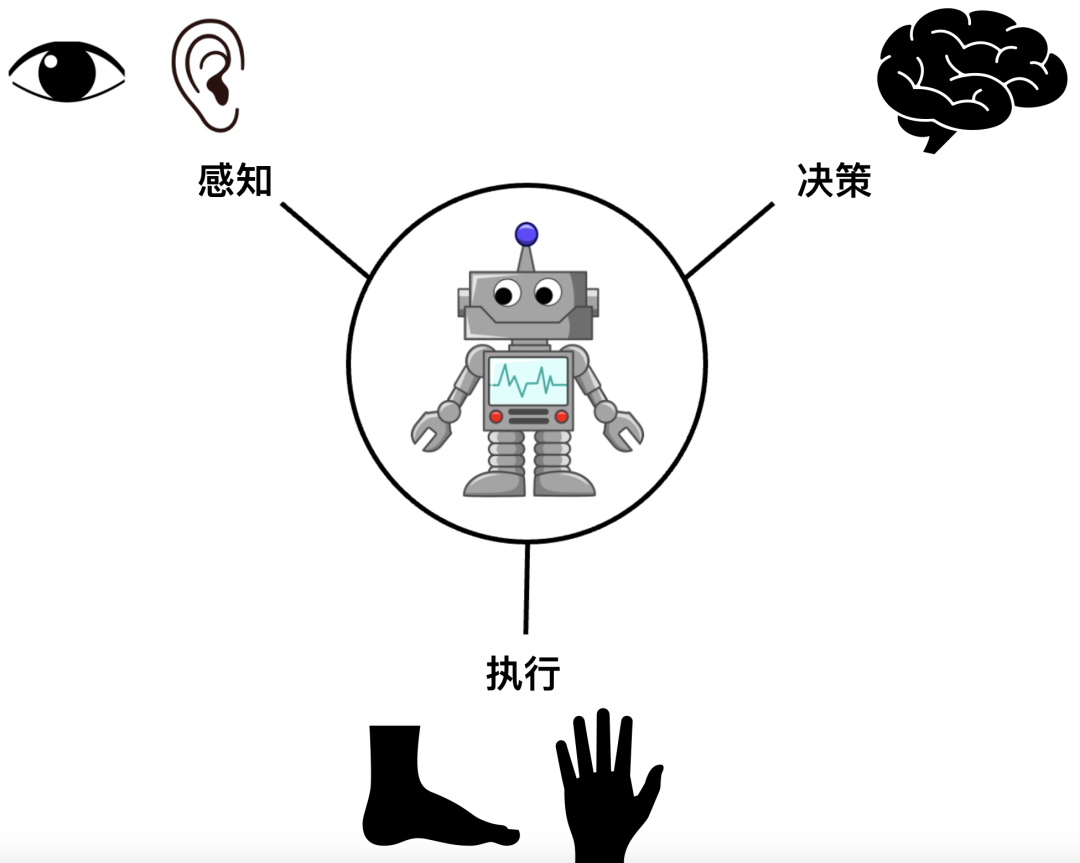
具身智能体的三种核心能力
有了这些基本的认识之后,我们回过头来看看大模型在这些核心能力中能够扮演什么样的角色。说到大模型,人们首先想到的大多是自然语言大模型,如 ChatGPT,它可以根据用户的文本输入进行理解分析,并给出文字回复。目前的研究表明,它们已经在场景级别具有足够的决策能力。利用这种决策能力,Michael Ahn 等人[1]提出了一种框架,即根据用户的简单文本命令,由语言模型进行决策,输出序列化的分步规划。如,用户输入“我打翻了可乐,请帮我清理一下”,语言模型据此输出“1. 找到可乐罐,2. 拿起它,3. 走到垃圾桶,4. 丢进垃圾桶,5. 找到海绵,6. 拿起海绵”。尽管语言模型输出的规划是合理的,但如何将这段文字直接作为控制机器人的指令,这其中依旧需要程序员对输出的文字进行代码处理。进一步的,我们能否把这一部分的定制化代码处理也交给语言模型呢?近期来自 Google、Microsoft、Stanford 的一系列工作[2,3,4]验证了这一可能性。结合语言模型对第三方库文档的理解能力,这些工作充分展示了这一方案的可扩展性,从控制桌面吸盘,到移动机器人、无人机等等。
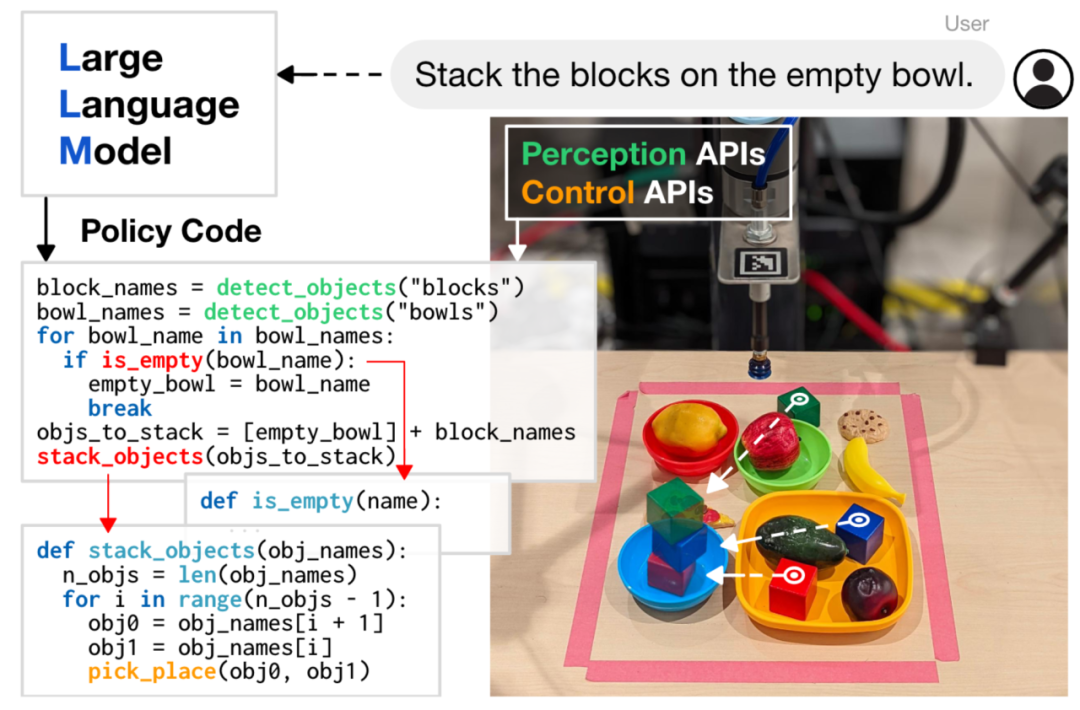
大模型驱动的具身智能体典型框架
说到这里,似乎只要使用语言模型作为决策工具,就能够让一个完全不会写代码的用户控制一个具有强大能力的智能体。但事实上,正如上文所言,具身智能体必须具备感知能力,才能因地制宜地做出决策。比如还是打翻可乐再清理的这个例子,如果所在的环境中并没有海绵,那么语言模型给出的方案就是无效的。因此,如何有效地感知环境,并将信息传递给语言模型,这依旧是一个重要且困难的问题。为了提升感知能力,研究者们又借助了第二种大模型,即视觉大模型。它们能够在特定的单一任务(如物体检测)上具有开放世界、强泛化性的能力。一个经典的做法[5]是这些视觉大模型将检测结果汇总为文字(如:当前场景中有 [“微波炉”“冰箱”“红苹果”“青苹果”……]),并结合用户命令一起输入语言模块,从而让决策模块具有对场景的粗粒度感知。

使用视觉模型进行场景感知的典型框架
但这其中依旧存在问题,这种单一任务的视觉大模型会丢失很多重要信息,比如物体的空间位置关系、物体的状态等等。举例而言,如果一个任务是泡咖啡,而场景中有一个脏的杯子,单一任务的视觉模型只会告诉语言模型场景中有一个杯子,而无法提取出“脏”这一信息,这就会导致糟糕的事故发生。形象地来说,语言大模型是知识渊博的盲人,而视觉模型则是刚认识生活中各种物品的孩子。目前的框架中,两者的全部信息交换都依靠文本来完成,但是在图像转为文本描述的过程中,必然会丢失很多信息,导致决策失误,因此这显然不是一条可行之路。
如何将感知和决策有机融合,这是一个开放、困难的问题。一种可能是,借助近期涌现的视觉语言大模型,如 BLIP-2[6],Emu[7]。它们能够根据用户文本输入的命令,结合给出的图片进行分析并输出文本。尽管这个框架可以起到人类的眼睛与大脑的作用,但目前来看,受限于它们的训练数据量,它们在文本方面的推理能力还远不如 ChatGPT。
目前为止,我们主要探讨了感知和决策这两个方面,接下来,我们再来谈谈执行。可以说,这三大能力中,执行是能力最为薄弱的环节。一方面,它不像前两者有着海量的互联网数据支持;另一方面,它不仅是一个软件算法问题,还涉及到硬件设计。从执行的角度来说,具身智能体主要分为移动和操作两大能力。移动方面,无论是最近爆火的二足机器人、已经取得极大突破的四足机器狗,还是已经商业落地的轮式机器人,它们能否在各种地形下实现鲁棒的移动,依旧是前沿的学术问题。操作方面,现阶段能够落地的只有吸盘和二指的简单抓取。也正是因此,目前所有大模型驱动的具身智能体能够完成的任务清一色是拿起放下类的任务。可以说,执行能力是三大核心能力中最短的那块木板。

大模型驱动的智能体能够完成的典型任务
当然,受篇幅所限,其实还有很多重要的问题本文并未涉及,比如如何基于视觉反馈形成闭环控制[5],如何利用大模型实现自动化的自我评价与进一步学习,如何解决语言模型决策的失误等,这些都是困难但迷人的问题。
大模型的涌现,将具身智能的发展推上了新的台阶。过去完全无法想象的通用理解、决策能力,现在已经初步实现。尽管依旧存在着诸多难题,但随着越来越多的人关注并投身具身智能,这一领域也必然迎来新的发展高峰期。笔者相信,在不远的未来,我们将看到更多聪明、可靠的机器人出现在日常生活中,将人类从危险、重复的劳动中解放出来,有更多的时间来享受生活。
Reference:
[1] Brohan, Anthony, et al. "Do as i can, not as i say: Grounding language in robotic affordances." Conference on Robot Learning. PMLR, 2023.
[2] Liang, Jacky, et al. "Code as policies: Language model programs for embodied control." 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023.
[3] Vemprala, Sai, et al. "Chatgpt for robotics: Design principles and model abilities." Microsoft Auton. Syst. Robot. Res 2 (2023): 20.
[4] Huang, Wenlong, et al. "VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models." arXiv preprint arXiv:2307.05973 (2023).
[5] Huang, Wenlong, et al. "Inner Monologue: Embodied Reasoning through Planning with Language Models." Conference on Robot Learning. PMLR, 2023.
[6] Li, Junnan, et al. "Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models." International Conference on Machine Learning. PMLR, 2023.
[7] Sun, Quan, et al. "Generative pretraining in multimodality." arXiv preprint arXiv:2307.05222 (2023).

文 | 严汨
图 | 除标注外,源自网络
PKU EPIC Lab

— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢