
国际人工智能联合会议(IJCAI)是 AI 领域中顶级学术会议之一,首届大会于 1969 年在加利福尼亚举办,之后每两年召开一次。从 2016 年开始 IJCAI 变为每年举行一次。今年 IJCAI-23 于 8 月 19 日至 25 日在澳门举行,所有相关奖项已经公布。

2023 IJCAI 论文接收情况如下,其中摘要提交 5120 篇、完整论文提交 4566 篇,最终接收了 643 篇,接收率约为 14%,相较去年的 15% 又有所下降。

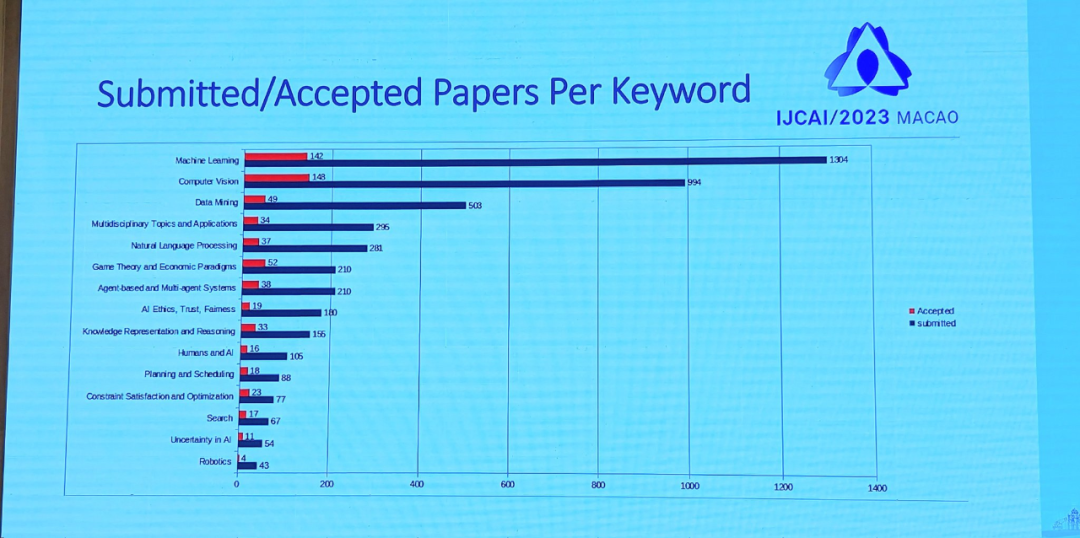
下图为基于关键词的提交和接收论文情况,可以看到,机器学习和计算机视觉领域提交和接收的论文数量最多。
杰出论文奖(Distinguished Papers)
IJCAI 今年评选出了三篇杰出论文奖,获奖机构包括 Google DeepMind 、阿尔伯塔大学、阿姆斯特丹大学 、莱比锡大学等机构。
论文 1《Levin Tree Search with Context Models》

论文地址:https://www.ijcai.org/proceedings/2023/0624.pdf
作者:Laurent Orseau 、 Marcus Hutter 、 Levi H. S. Lelis
机构:Google DeepMind 、阿尔伯塔大学
摘要:Levin 树搜索 (LTS) 是一种利用策略(动作的概率分布)的搜索算法,并提供了在达到目标节点之前进行多少扩展的理论保证(guarantee),这取决于策略的质量。这种保证可以看作损失函数,研究者将其称之为 LTS 损失,从而用来优化表示策略的神经网络(LTS+NN)。
本文展示了神经网络可以替换成从在线压缩文献中产生参数化的上下文模型(LTS+CM)。本文表明, 在这个新模型下 LTS 损失是凸的,它允许使用标准的凸优化工具,并且在给定的一组解轨迹的在线设置中获得了最优参数的收敛保证 —— 这是神经网络无法提供的保证。
新的 LTS+CM 算法在几个基准上优于 LTS+NN,包括 Sokoban (Boxoban)、The Witness、STP(the 24-Sliding Tile puzzle)基准。
在 STP 基准上的结果表明,两者的差异非常大,即 LTS+NN 无法解决大多数测试实例,而 LTS+CM 在不到一秒内就解决了每个测试实例。此外,LTS+CM 能够学习解决魔方策略,只需要几百个扩展,从而大大改善了之前的机器学习方法。
下表为带有 Budgeted LTS 的上下文模型:

论文 2《SAT-Based PAC Learning of Description Logic Concepts》

论文地址:https://www.ijcai.org/proceedings/2023/0373.pdf
作者:Balder ten Cate 、Maurice Funk、Jean Christoph Jung、Carsten Lutz
机构:阿姆斯特丹大学 、莱比锡大学等
摘要:在知识表示中,知识库 (KB) 的手动管理既耗时又昂贵,这使得基于学习的知识获取方法成为一种有吸引力的替代方案。
本文提出了 SPELL,这是一个基于 SAT 的系统,可在下实现的有界拟合。
本文在多个数据集上评估了 SPELL,结果表明 SPELL 的运行时间几乎总是显着低于 ELTL(EL tree learner)。这意味着 SPELL 可以学习比 ELTL 更大的目标查询。本文还分析了两种方法的相对优势和劣势,确定其中一种系统的性能明显优于另一种系统的输入类别。最后,本文进行了关于泛化的初步实验,表明两个系统都可以很好地泛化到看不见的数据,即使是在非常小的样本上。
下图为 SPELL、ELTL 一些比较结果: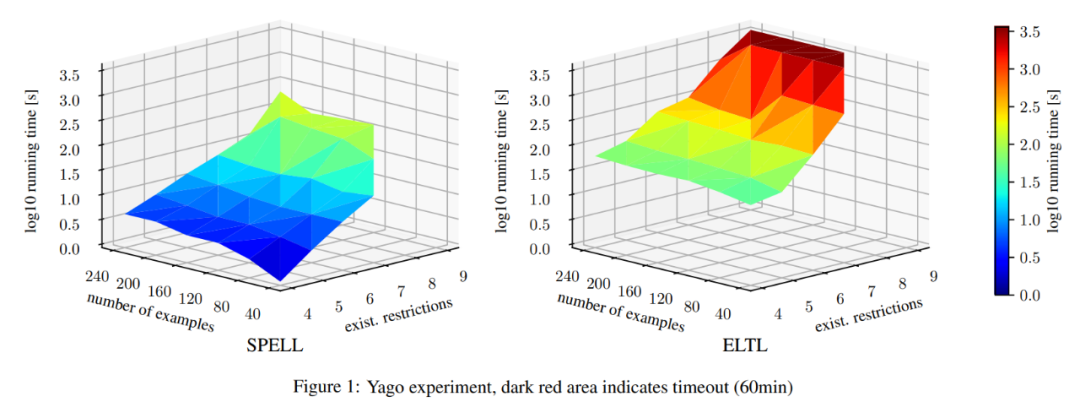
论文 3《Safe Reinforcement Learning via Probabilistic Logic Shields》

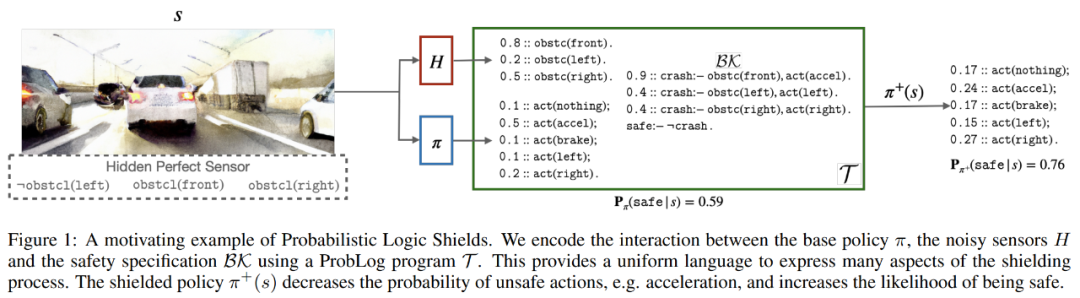
实验表明,与其他 SOTA 屏蔽技术相比,PLPG 可以学习更安全、更有价值的策略。
论文一作 Wen-Chi Yang 为鲁汶大学 DTAI 研究团队的博士,致力于通过形式化验证与机器学习的结合,来提升安全约束可满足性。她还特别对智能体利用背景知识来安全地学习和探索感兴趣。本科毕业于台湾交通大学,之后进入鲁汶大学攻读硕士和博士学位(均为计算机科学)。
个人主页:https://wenchiyang.github.io/
AIJ 奖
AIJ 的全称为 Artificial Intelligence Journal,即《人工智能期刊》,始建于 1970 年,是人工智能研究领域的顶级学术期刊,具有公认的权威性与知名性。
AIJ 突出论文奖
2023 年 AIJ 突出论文奖授予 José Camacho-Collados、Mohammad Taher Pilehvar、Roberto Navigli 合著的论文《Nasari: Integrating explicit knowledge and corpus statistics for a multilingual representation of concepts and entities》。该论文发表于 2016 年。

论文地址:https://www.sciencedirect.com/science/article/pii/S0004370216300820
摘要:语义表征被认为是 NLP 和 AI 研究中最基本的内容,其在过去几十年中一直是词汇语义学的重要研究领域。然而,由于缺乏大型的语义标注语料库,大多数现有的表征技术仅限于词汇层面,因此无法有效地应用于单个单词的语义。
本文提出了一种新的多语言向量表征,称为 Nasari,它不仅能够准确地表征不同语言的词义,而且与现有方法相比存在两个优点:
此外,Nasari 表征很灵活,可以应用于多种应用程序,并且可以在网站上免费获得。该研究在四个不同任务上进行评估,即单词相似度、语义聚类、域标记和词义消歧,结果显示,Nasari 表征在所有任务上表现 SOTA。
下表为统一向量构造方法:

AIJ 经典论文奖
今年的 AIJ 经典论文奖颁给了关于超级计算机深蓝的论文《Deep Blue》。该论文发表于 2002 年。

摘要:深蓝(Deep Blue)是由 IBM 开发的专门用以分析国际象棋的超级计算机。其在 1997 年的六场比赛中击败了当时的世界象棋冠军加里・卡斯帕罗夫。促成这一成功的因素有很多,包括:
本文描述了深蓝系统,并给出了深蓝背后设计决策的一些基本原理。如下为 dual credit 算法。

IJCAI-JAIR 最佳论文奖
自 2003 年起,IJCAI-JAIR 最佳论文奖每年从最近 5 年发表在 JAIR 的论文中评选并表彰一篇杰出论文。评审的标准基于论文的重要性和 presentation 的质量。
2023 年的 IJCAI-JAIR 最佳论文奖授予了论文《Reward Machines: Exploiting Reward Function Structure in Reinforcement Learning》,作者来自智利天主教大学、加拿大 AI 研究机构 Vector Institute、多伦多大学等。

论文地址:https://jair.org/index.php/jair/article/view/12440
此前,2023 IJCAI 的「Donald E. Walker 杰出服务奖」授予了香港科技大学讲座教授杨强,以表彰其对 IJCAI 组织和整个人工智能领域的杰出贡献。他也成为了该奖项设置以来首位获奖的华人科学家。

参考链接:https://www.ijcai.org/awards
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢