
当下大模型的学习和应用如火如荼,但笔者咨询了业界一线的几位技术大咖,大家的共识是:大模型真正的应用场景以及落地项目还不多,目前是一种技术趋势,大模型的应用实践才刚刚开始。大模型从成本上和落地难度上是有它的短板的。传统的实现方式也未必不好!传统的方式也是有自己的优势!笔者希望通过讲解一个完整的订餐机器人实战项目,来帮助大家更好地理解和掌握NLP技术的核心理论和实际应用,希望大家能够了解传统的方式和大模型的方式的异同,在实际工作中能够更加合理的实现业务落地的目的。
一、场景介绍
我们先来介绍一下订餐机器人项目主要应用场景,对话流程树和具体应用界面如下图:
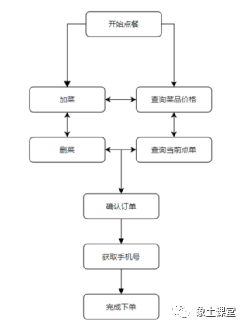
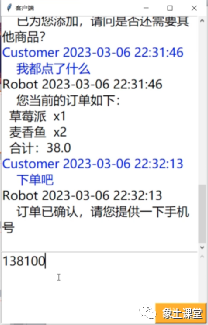
此场景基本上涵盖了对话系统的意图识别、槽位抽取和填充、状态跟踪、对话策略、数据库操作、文本生成几大核心部分。当然这个对话系统只是用于最小化的展示,用于让大家理解核心的框架实现,后续可以依据自己的实际场景进行交互上的、产品上的重新设计和复用。
有了场景上的概念以后,我们来依次给大家讲解一下各个部分的核心理论。首先要讲到的就是自然语言理解(NLU)的意图识别部分,也就是说我们首先要知道对方说了什么,我们才能有后续的操作。请先阅读以下两张PPT。
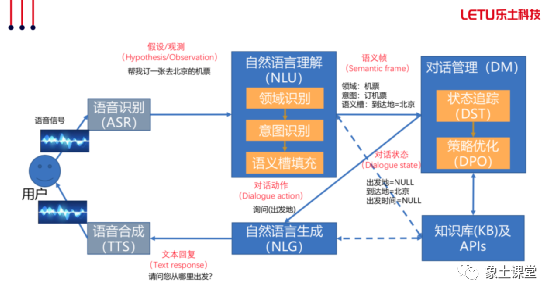
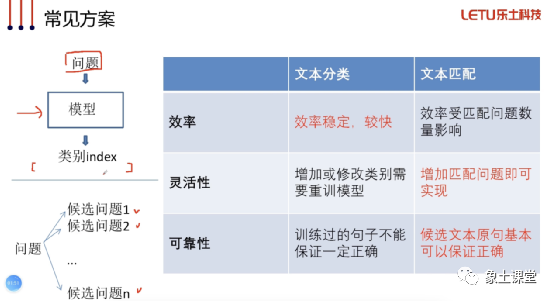
意图识别一般情况下有两种方案:一种是采用文本分类方式,另一种是采用文本匹配的方式去处理。文本分类主要采用分类模型的方式去实现,需要预先规定好类别,并且针对每一个类别去做相应的训练数据。而文本匹配主要采用预先设置一系列的候选问题,然后我们用问题通过文本匹配算法去匹配候选问题,然后打分,分值最高的则命中。
文本分类的方式优势是效率比较稳定,速度较快。文本匹配则在增加新匹配问题和回答正确性上有一定优势。文本匹配有个缺陷,就是效率受匹配问题数量的影响。一般情况下我们从成本、灵活性和正确性的角度考虑,倾向于采用文本匹配的方案。当然在意图比较固定的情况下,也有可能考虑文本分类的方案。
文本匹配的运行逻辑主要是:首先对用户问题进行预处理,比如:分词、去掉停用词,去标点、大小写转换、词性标注等。预处理完以后就要和FAQ库中的问题进行相似度计算,然后得出答案。
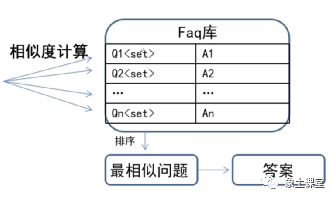
那么标准的FAQ库主要是什么呢?它主要有一系列由序号、问题、答案、相似问题组成的记录集合。

编辑距离
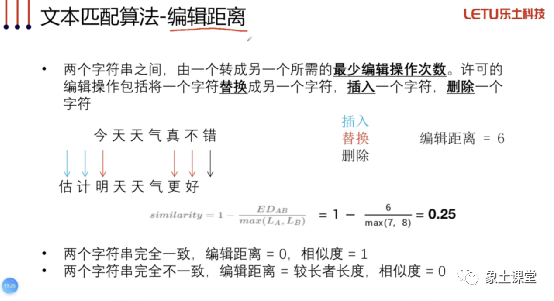
优点:可解释性强、跨语种有效、不需要训练模型。
缺点:字符之间没有语义相似度、受无关词/停用词影响大、受语序影响大、文本长度对速度影响大。
Jaccard距离

优点:语序不影响分数(词袋模型)、实现简单、速度快。可跨语种,无需训练等。
缺点:语序不影响分数(双刃剑)、字词之间没有相似度衡量、受无关词影响、非一致文本可能出现满分。
word2vec
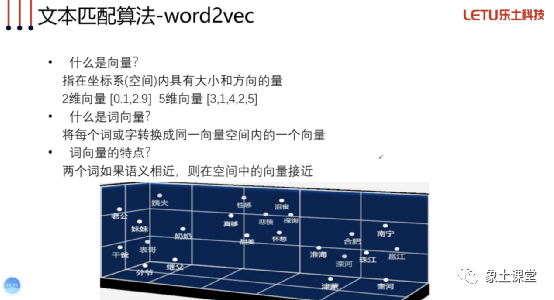
两个文本包含语义相似的词,会提高相似度;
训练需要的数据简单(纯文本预料即可);
计算速度快,可以对知识库问题预先计算向量;
将文本转化为数字,使后续复杂模型成为可能。
词向量的效果决定句向量效果;
一词多义的情况难以处理; 受停用词和文本长度影响很大(也是词袋模型);
更换语种,甚至更换领域,都需要重新训练。
三、完整实现
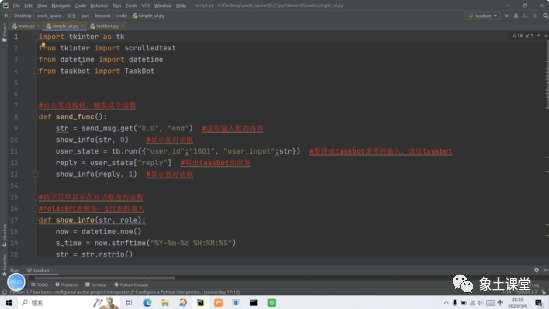
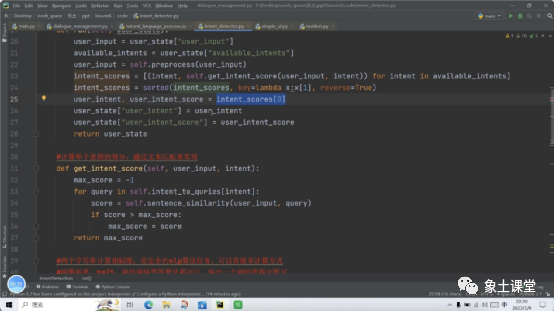
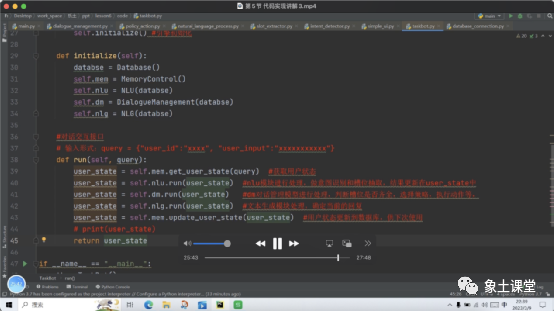
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢