
Meta开源文本生成代码模型Code Llama。
我们正在解锁大型语言模型的力量,我们最新版本的Code Llama现在可供各种规模的个人、创作者、研究人员和企业使用,以便他们能够负责任地实验、创新和扩展他们的想法。此版本包括预训练和微调的Llama语言模型的模型权重和起始代码——从7B到34B参数不等。
开源地址:https://github.com/facebookresearch/codellama
博客地址:https://ai.meta.com/blog/code-llama-large-language-model-coding/
论文地址:https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
作者:
Baptiste Rozière†, Jonas Gehring†, Fabian Gloeckle†,∗, Sten Sootla†, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve†
Code Llama是一个基于Llama 2的代码的大型语言模型系列,在开放模型中提供最先进的性能、填充功能、对大型输入上下文的支持以及编程任务的零射击指令。
我们提供多种口味来涵盖广泛的应用:基础模型(Code Llama)、Python专业化(Code Llama-Python)和指令遵循模型(Code Llama-Instruct),每个参数分别为7B、13B和34B。所有模型都对16k个令牌的序列进行了训练,并对高达10万个令牌的输入进行了改进。7B和13B Code Llama和Code Llama-指示变体支持基于周围内容的填充。Code Llama是通过使用更高的代码采样微调Llama 2开发的。与Llama 2一样,我们对模型的微调版本进行了相当大的安全缓解。
有关模型训练、架构和参数、评估、负责任的人工智能和安全的详细信息,请参阅我们的研究论文。由Llama材料的代码生成功能(包括Code Llama)生成的输出可能受第三方许可证的约束,包括但不限于开源许可证。

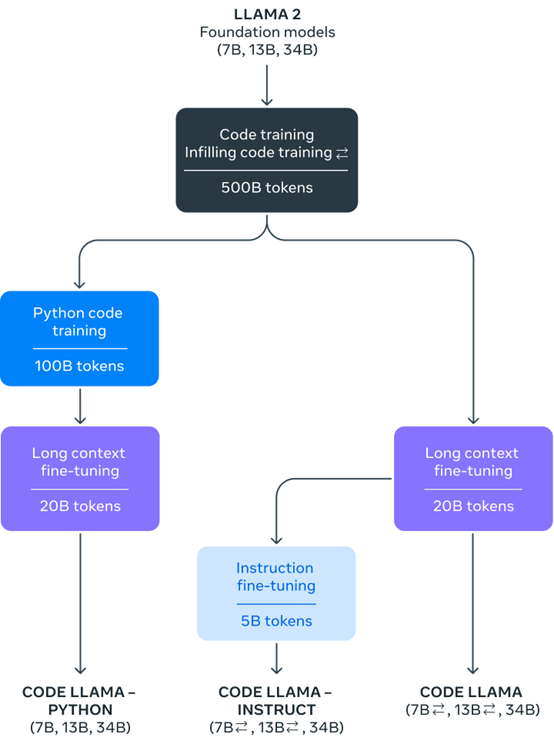
Code Llama是基于Llama 2大语言模型,再通过特定代码数据预训练、微调而成。除了支持文本或代码生成代码之外,还可用于代码的调试并支持目前所有主流开发语言。
Code Llama提供70亿、130亿和340亿三种参数模型,每个模型都使用了5000亿tokens代码数据训练而成。基础模型和指令模型经过了中间填充文本 (FIM) 功能的训练,允许将代码插入到现有代码中,这意味着它们可以支持开箱即用的代码完成任务。
Code Llama 模型提供了高达100,000 个上下文标记的稳定生成。所有模型均在 16,000 个标记的序列上进行训练,并在最多100,000 个标记的输入上显示出改进。开发人员在进行大型代码模型测试、调优时,可以将其全部输入到Code Llama中进行测试。
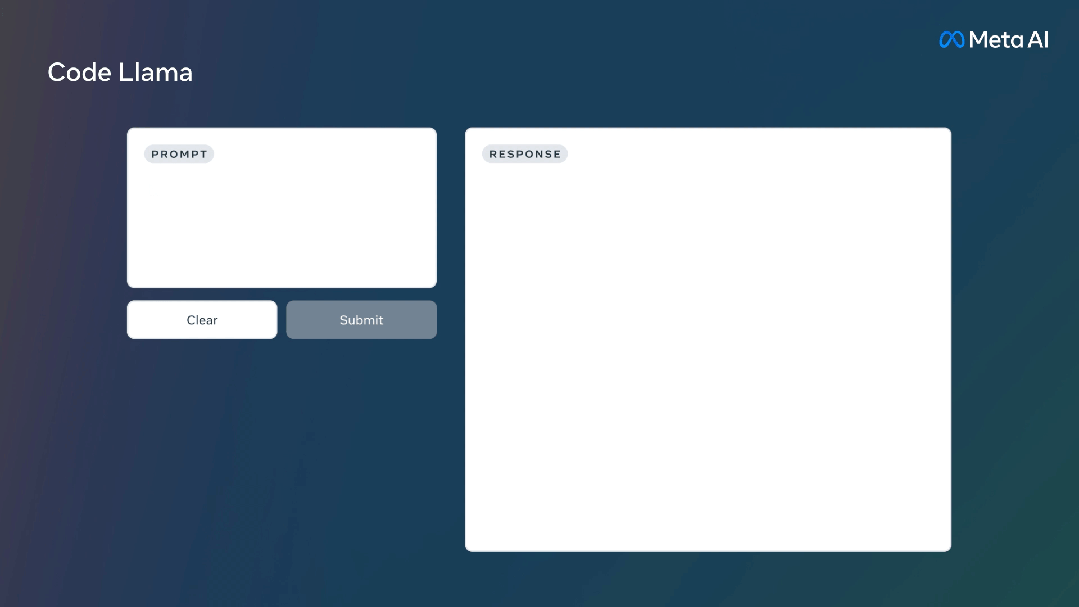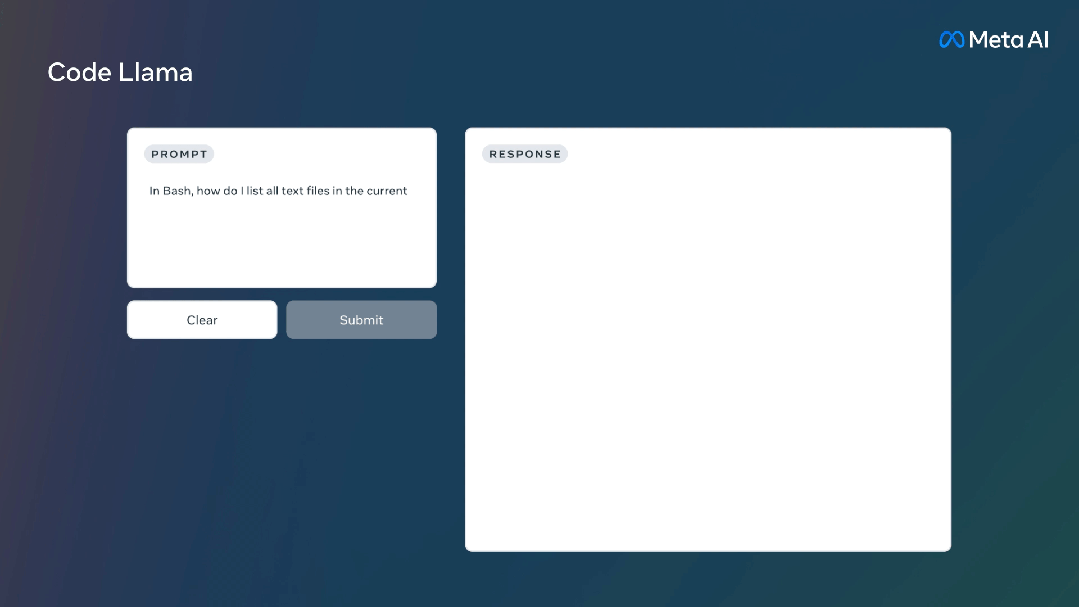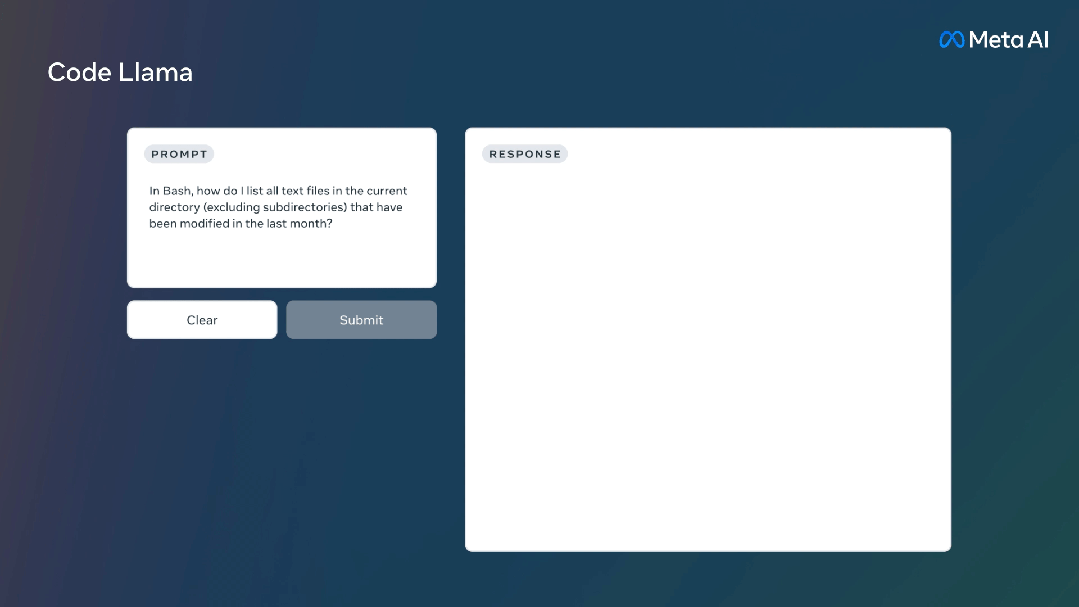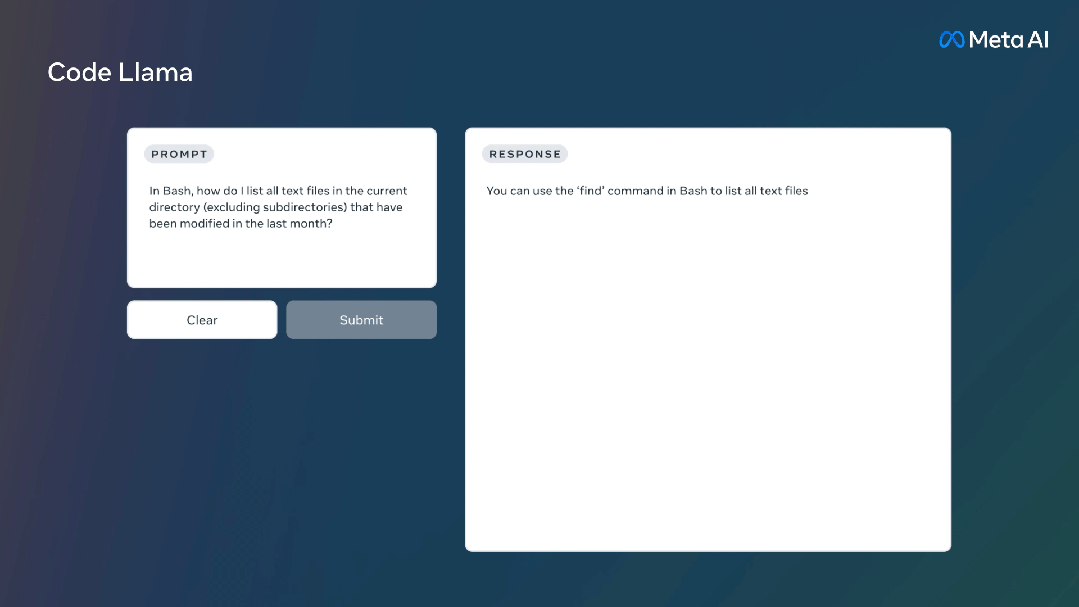
Code Llama还针对Python编程推出了Code Llama Python模型。是在 Python 代码的 1000亿标记上进行微调。
Python是代码生成方面最具基准测试的语言,并且Python 和 PyTorch 在AI 社区中发挥着重要作用,所以,推出了针对Python的代码模型。
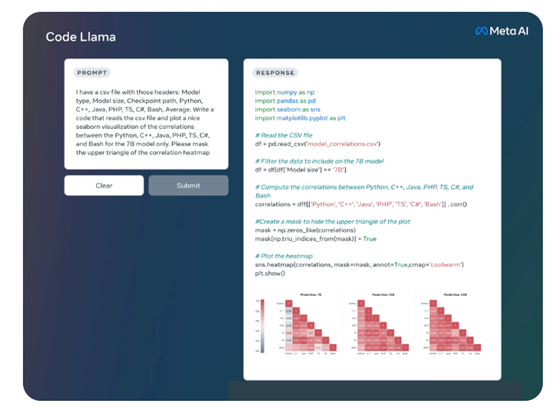
Code Llama - Instruct 是 Code Llama 针对自然文本指令微调的模型,该模型支持自然文本输入和输出。
如果你想使用文本生成代码,Meta建议你使用该模型,因为Code Llama - Instruct已经过数据微调理解自然文本更好并且生成的代码更符合开发人员要求。
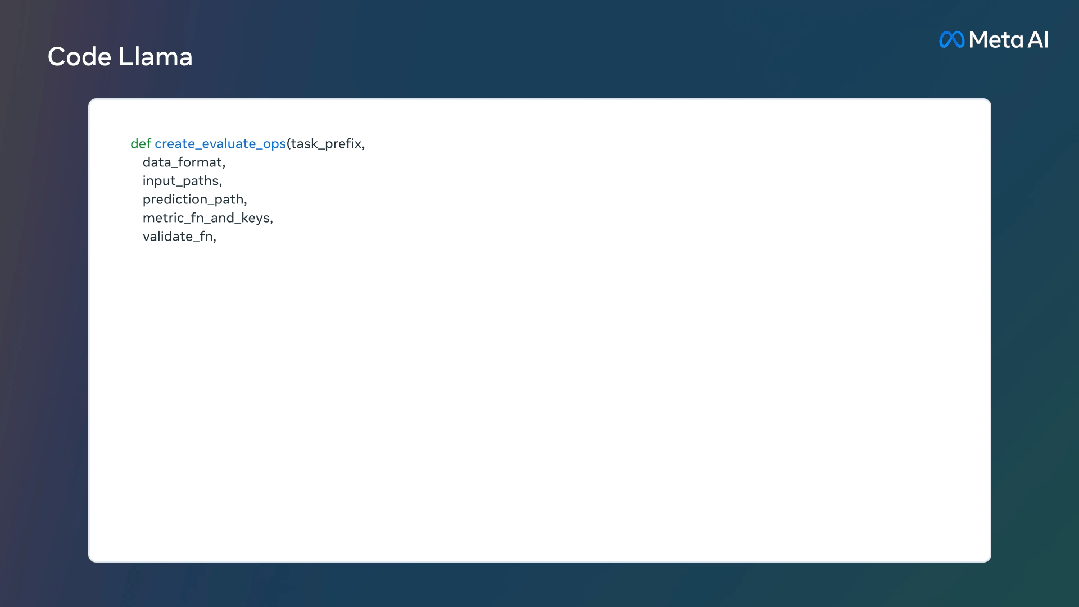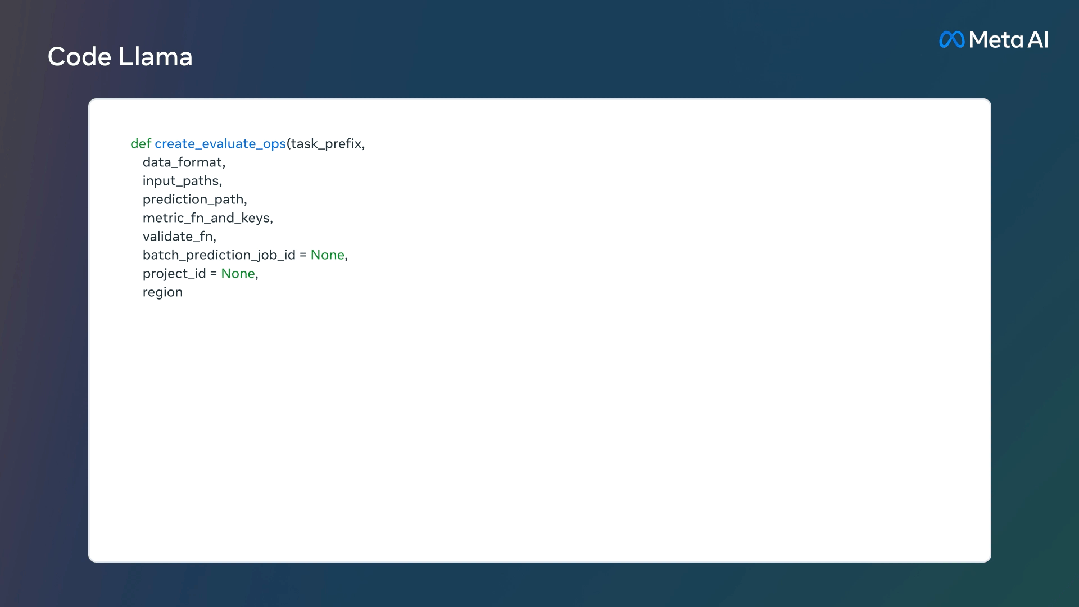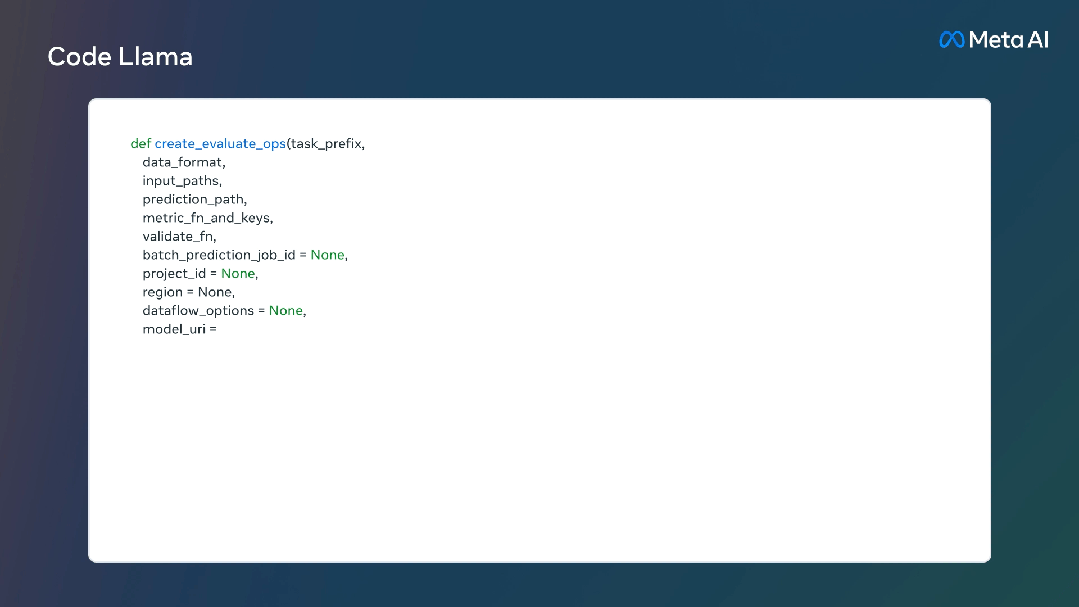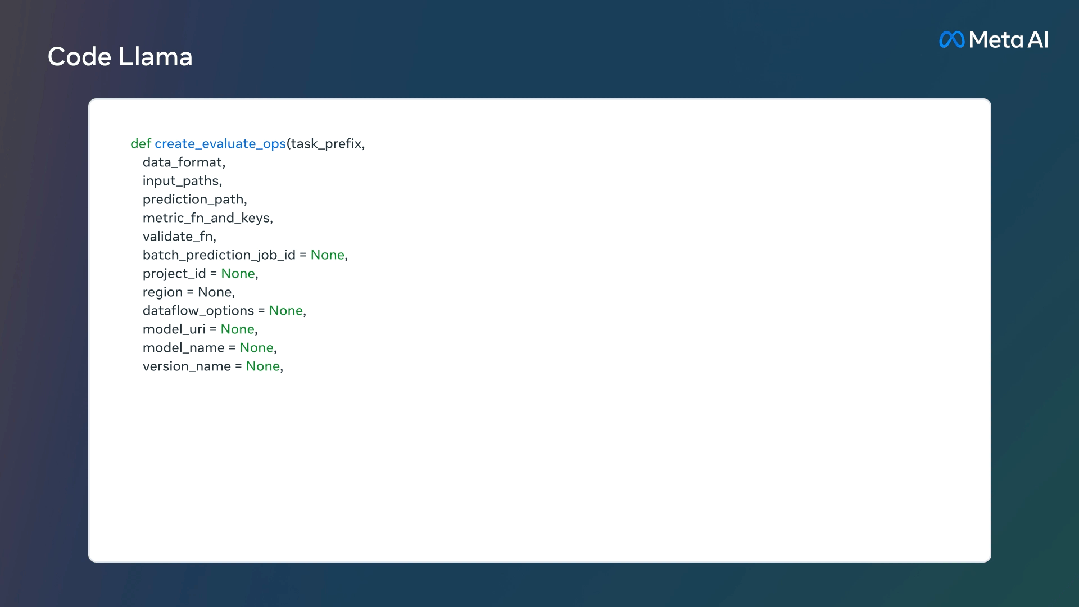
资源消耗方面,70亿参数模型可在单个GPU上运行。340亿参数模型可返回最佳结果并提供更好的编程辅助,但资源消耗更大。
所以,对于个人开发者、中小型企业来说,70亿、130亿参数的模型效率更高、资源消耗更少,适合低延迟的任务,例如,进行实时代码开发。
Code Llama性能评测
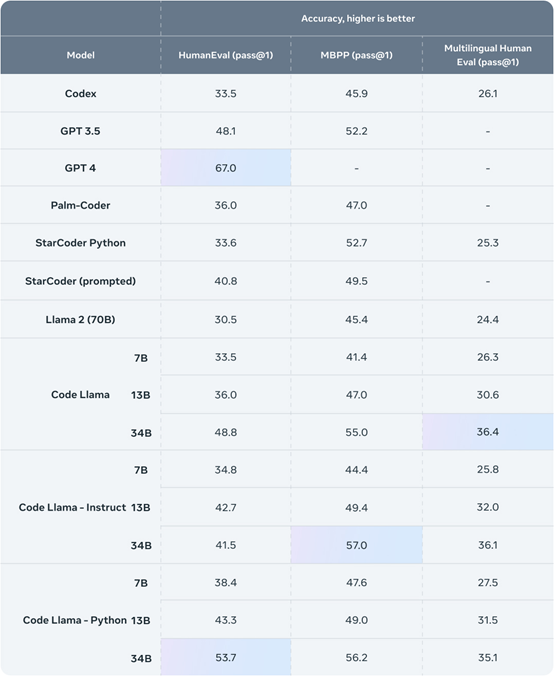
为了针对现有解决方案测试 Code Llama 的性能,Meta使用了两个流行的编码基准:HumanEval 和 Mostly Basic Python 编程 (MBPP)。
HumanEval 测试模型根据文档字符串完成代码的能力,MBPP测试模型根据描述编写代码的能力。
测试结果显示,Code Llama的表现优于开源、特定代码的Llama,并且优于 Llama 2。例如,Code Llama 340亿参数模型在 HumanEval上得分为 53.7%,在 MBPP 上得分为 56.2%,与ChatGPT性能相当。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢