

以下文章来源于知乎:WeThinkln
作者:Rocky Ding
链接:https://mp.weixin.qq.com/s/5XVdAOrr9zp9SFPgu2QcUQ
本文仅用于学术分享,如有侵权,请联系后台作删文处理

写在前面

【目录先行】
Stable Diffusion XL资源分享 Stable Diffusion XL整体架构初识 U-Net模型(Base部分)详解(包含网络结构图) VAE模型详解(包含网络结构图) CLIP Text Encoder模型详解(包含网络结构图) Refiner模型详解(包含网络结构图) Stable Diffusion XL训练技巧
【一】Stable Diffusion XL资源分享
官方项目:https://github.com/Stability-AI/generative-models 训练代码:https://github.com/Linaqruf/kohya-trainer 模型权重:https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9(只能申请访问权限) 模型权重百度云网盘:关注Rocky的公众号WeThinkIn,后台回复:SDXL模型,即可获得资源链接,包含Stable Diffusion XL 0.9(Base模型+Refiner模型)模型权重,Stable Diffusion XL 1.0(Base模型+Refiner模型)模型权重以及Stable Diffusion XL VAE模型权重。 技术报告:SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
更多Stable Diffusion XL的资源会持续发布到Rocky的知乎原文中去:https://zhuanlan.zhihu.com/p/643420260,让大家更加方便的查找最新资讯。
【二】Stable Diffusion XL整体架构初识
与Stable DiffusionV1-v2相比,Stable Diffusion XL主要做了如下的优化:
对Stable Diffusion原先的U-Net,VAE,CLIP Text Encoder三大件都做了改进。 增加一个单独的基于Latent的Refiner模型,来提升图像的精细化程度。 设计了很多训练Tricks,包括图像尺寸条件化策略,图像裁剪参数条件化以及多尺度训练等。 先发布Stable Diffusion XL 0.9测试版本,基于用户使用体验和生成图片的情况,针对性增加数据集和使用RLHF技术优化迭代推出Stable Diffusion XL 1.0正式版。
Stable Diffusion XL是一个二阶段的级联扩散模型,包括Base模型和Refiner模型。其中Base模型的主要工作和Stable Diffusion一致,具备文生图,图生图,图像inpainting等能力。在Base模型之后,级联了Refiner模型,对Base模型生成的图像Latent特征进行精细化,其本质上是在做图生图的工作。
Base模型由U-Net,VAE,CLIP Text Encoder(两个)三个模块组成,在FP16精度下Base模型大小6.94G(FP32:13.88G),其中U-Net大小5.14G,VAE模型大小167M以及两个CLIP Text Encoder一大一小分别是1.39G和246M。
Refiner模型同样由U-Net,VAE,CLIP Text Encoder(一个)三个模块组成,在FP16精度下Refiner模型大小6.08G,其中U-Net大小4.52G,VAE模型大小167M(与Base模型共用)以及CLIP Text Encoder模型大小1.39G(与Base模型共用)。
可以看到,Stable Diffusion XL无论是对整体工作流还是对不同模块(U-Net,VAE,CLIP Text Encoder)都做了大幅的改进,能够在1024x1024分辨率上从容生成图片。同时这些改进无论是对生成式模型还是判别式模型,都有非常大的迁移应用价值。
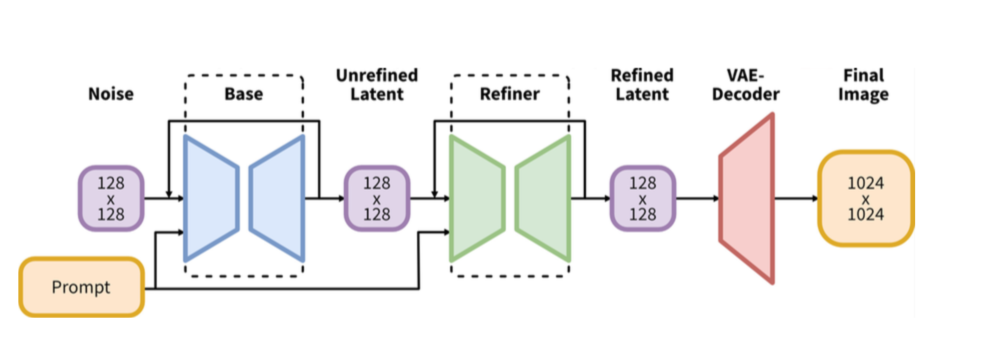
比起Stable Diffusion,Stable Diffusion XL的参数量增加到了101亿(Base模型35亿+Refiner模型66亿),并且先后发布了模型结构完全相同的0.9和1.0两个版本。Stable Diffusion XL 1.0使用更多训练集+RLHF来优化生成图像的色彩,对比度,光线以及阴影方面,使得生成图像的构图比0.9版本更加鲜明准确。
Rocky相信过不了多久,以Stable Diffusion XL 1.0版本为基础的AI绘画以及AI视频生态将会持续繁荣。
【三】U-Net模型(Base部分)详解(包含网络结构图)

上表是Stable Diffusion XL与之前的Stable Diffusion系列的对比,从中可以看出,Stable DiffusionV1.4/1.5的U-Net参数量只有860M,就算是Stable DiffusionV2.0/2.1,其参数量也不过865M。但等到Stable Diffusion XL,U-Net模型(Base部分)参数量就增加到2.6B,参数量增加幅度达到了3倍左右。
其中增加的Spatial Transformer Blocks(Self Attention + Cross Attention)数量是新增参数量的主要部分,Rocky在上表中已经用红色框圈出。U-Net的Encoder和Decoder结构也从原来的4stage改成3stage([1,1,1,1] -> [0,2,10]),并且比起Stable DiffusionV1/2,Stable Diffusion XL在第一个stage中不再使用Spatial Transformer Blocks,而在第二和第三个stage中大量增加了Spatial Transformer Blocks(分别是2和10),大大增强了模型的学习和表达能力。
在第一个stage不使用SpatialTransformer Blocks(减少显存和计算量),并且再第二和第三个stage这两个维度较小的feature map上使用数量较多的Spatial Transformer Blocks,能在提升模型整体性能的同时,优化计算效率。在参数保持一致的情况下,Stable Diffusion XL生成图片的耗时只比Stable Diffusion多了20%-30%之间,这个拥有2.6B参数量的模型已经足够伟大。
下图是Rocky梳理的Stable Diffusion XL Base U-Net的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习Stable Diffusion XL Base U-Net部分,相信大家脑海中的思路也会更加清晰:
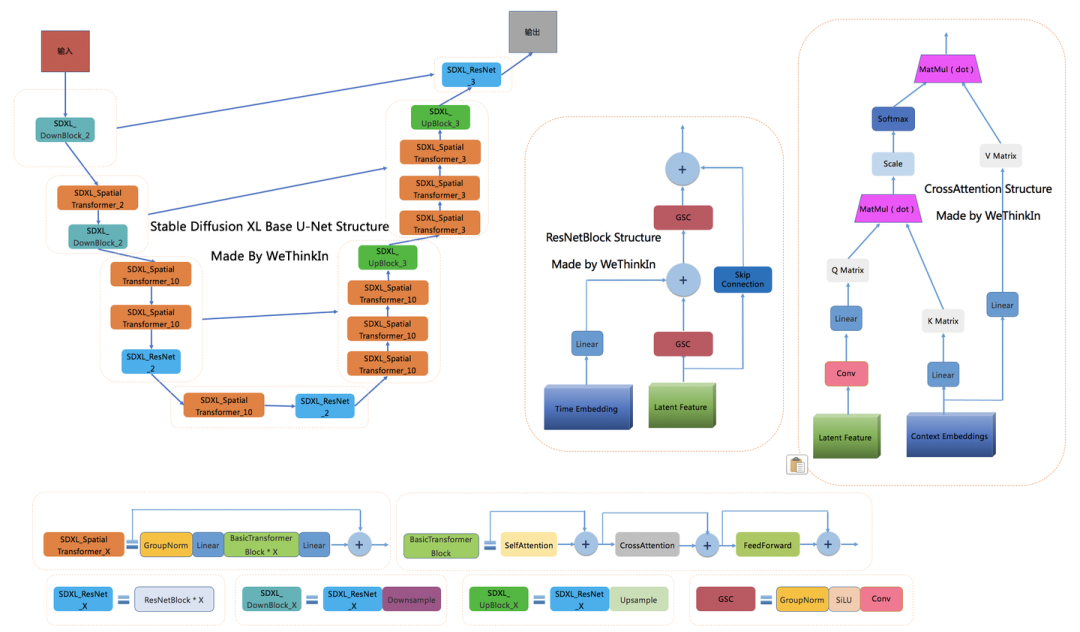
在Encoder结构中,包含了两个SDXL_DownBlock结构,三个SDXL_SpatialTransformer结构,以及一个SDXL_ResNet结构;在Decoder结构中,包含了两个SDXL_UpBlock结构,六个SDXL_SpatialTransformer结构,以及一个SDXL_ResNet结构;与此同时,Encoder和Decoder中间存在Skip Connection,进行信息的传递与融合。
可以看到BasicTransformer Blocks结构是整个框架的基石,由Self Attention,Cross Attention和FeedForward三个组件构成,并且使用了循环残差模式。
Stable Diffusion XL中的Text Condition信息由两个Text Encoder提供(OpenCLIP ViT-bigG和OpenAI CLIP ViT-L),通过Cross Attention组件嵌入,作为K Matrix和V Matrix。与此同时,图片的Latent Feature作为Q Matrix。
【四】VAE模型详解(包含网络结构图)
VAE模型(变分自编码器,Variational Auto-Encoder)是一个经典的生成式模型,其基本原理就不过多介绍了。在传统深度学习时代,GAN的风头完全盖过了VAE,但VAE简洁稳定的Encoder-Decoder架构,以及能够高效提取数据Latent特征的关键能力,让其跨过了周期,在AIGC时代重新繁荣。
Stable Diffusion XL依旧是基于Latent的扩散模型,所以VAE的Encoder和Decoder结构依旧是Stable Diffusion XL提取图像Latent特征和图像像素级重建的关键一招。
当输入是图片时,Stable Diffusion XL和Stable Diffusion一样,首先会使用VAE的Encoder结构将输入图像转换为Latent特征,然后U-Net不断对Latent特征进行优化,最后使用VAE的Decoder结构将Latent特征重建出像素级图像。除了提取Latent特征和图像的像素级重建外,VAE还可以改进生成图像中的高频细节,小物体特征和整体图像色彩。
当Stable Diffusion XL的输入是文字时,这时我们不需要VAE的Encoder结构,只需要Decoder进行图像重建。VAE的灵活运用,让Stable Diffusion系列增添了几分优雅。
Stable Diffusion XL使用了和之前Stable Diffusion系列一样的VAE结构,但在训练中选择了更大的Batch-Size(256 vs 9),并且对模型进行指数滑动平均操作(EMA,exponential moving average),EMA对模型的参数做平均,从而提高性能并增加模型鲁棒性。
下面是Rocky梳理的Stable Diffusion XL的VAE完整结构图,希望能让大家对这个在Stable DIffusion系列中未曾改变架构的模型有一个更直观的认识,在学习时也更加的得心应手:
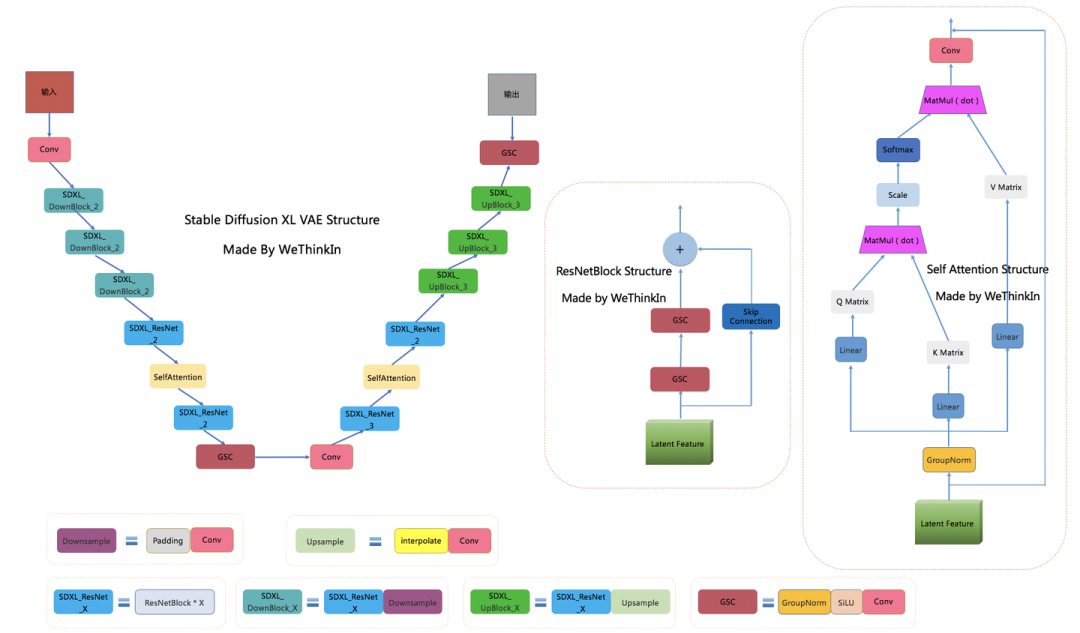
在损失函数方面,使用了久经考验的生成领域“交叉熵”—感知损失(perceptual loss)以及回归损失来约束VAE的训练过程。
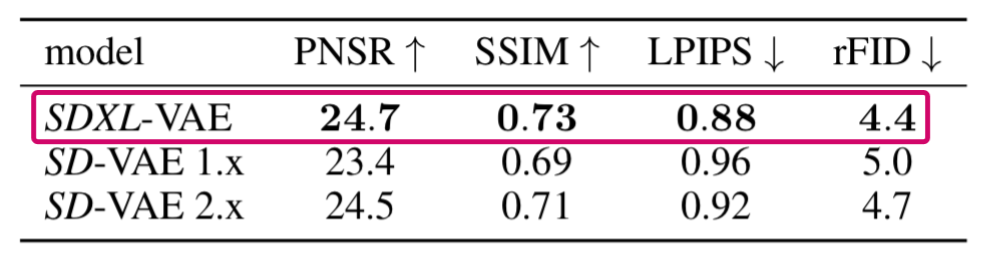
下表是Stable Diffusion XL的VAE在COCO2017 验证集上,图像大小为256×256像素的情况下的性能。
(注:Stable Diffusion XL的VAE是从头开始训练的)
与此同时,VAE的缩放系数也产生了变化。VAE在将Latent特征送入U-Net之前,需要对Latent特征进行缩放让其标准差尽量为1,之前的Stable Diffusion系列采用的缩放系数为0.18215,由于Stable Diffusion XL的VAE进行了全面的重训练,所以缩放系数重新设置为0.13025。
注意:由于缩放系数的改变,Stable Diffusion XL VAE模型与之前的Stable Diffusion系列并不兼容。官方的Stable Diffusion XL VAE的权重已经开源:https://huggingface.co/stabilityai/sdxl-vae
在官网如果遇到网络问题或者下载速度很慢的问题,可以关注Rocky的公众号WeThinkIn,后台回复:SDXL模型,即可获得Stable Diffusion XL VAE模型权重资源链接。
【五】CLIP Text Encoder模型详解(包含网络结构图)
CLIP模型主要包含Text Encoder和Image Encoder两个模块,在Stable Diffusion XL中,和之前的Stable Diffusion系列一样,只使用Text Encoder模块从文本信息中提取Text Embeddings。
不过Stable Diffusion XL与之前的系列相比,使用了两个CLIP Text Encoder,分别是OpenCLIP ViT-bigG(1.39G)和OpenAI CLIP ViT-L(246M),从而大大增强了Stable Diffusion XL对文本的提取和理解能力。
其中OpenCLIP ViT-bigG是一个只由Transformer模块组成的模型,一共有32个CLIPEncoder模块,是一个强力的特征提取模型。其单个CLIPEncoder模块结构如下所示:
# OpenCLIP ViT-bigG中CLIPEncoder模块结构
CLIPEncoderLayer(
(self_attention): CLIPAttention(
(k_Matric): Linear(in_features=1280, out_features=1280, bias=True)
(v_Matric): Linear(in_features=1280, out_features=1280, bias=True)
(q_Matric): Linear(in_features=1280, out_features=1280, bias=True)
(out_proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(layer_norm1): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): GELUActivation()
(fc1): Linear(in_features=1280, out_features=5120, bias=True)
(fc2): Linear(in_features=5120, out_features=1280, bias=True)
)
(layer_norm2): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)
)
# OpenAI CLIP ViT-L中CLIPEncoder模块结构
CLIPEncoderLayer(
(self_attention): CLIPAttention(
(k_Matric): Linear(in_features=768, out_features=768, bias=True)
(v_Matric): Linear(in_features=768, out_features=768, bias=True)
(q_Matric): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(layer_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): QuickGELUActivation()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
)
(layer_norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)

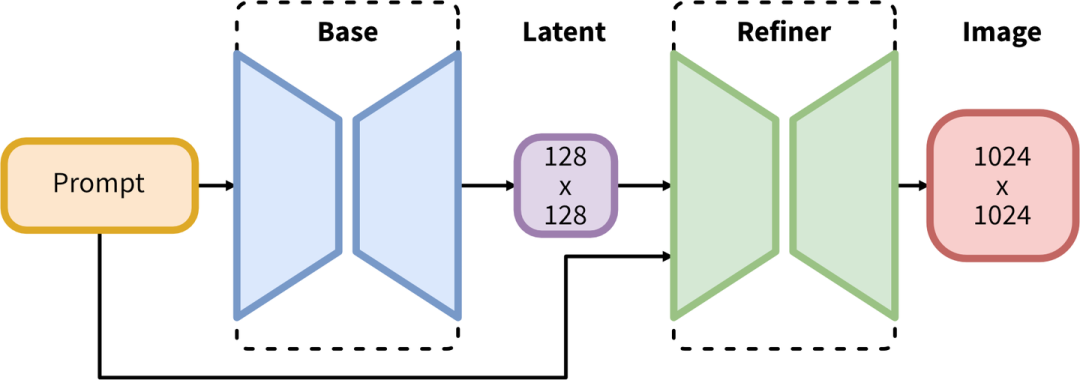
【六】Refiner模型详解(包含网络结构图)
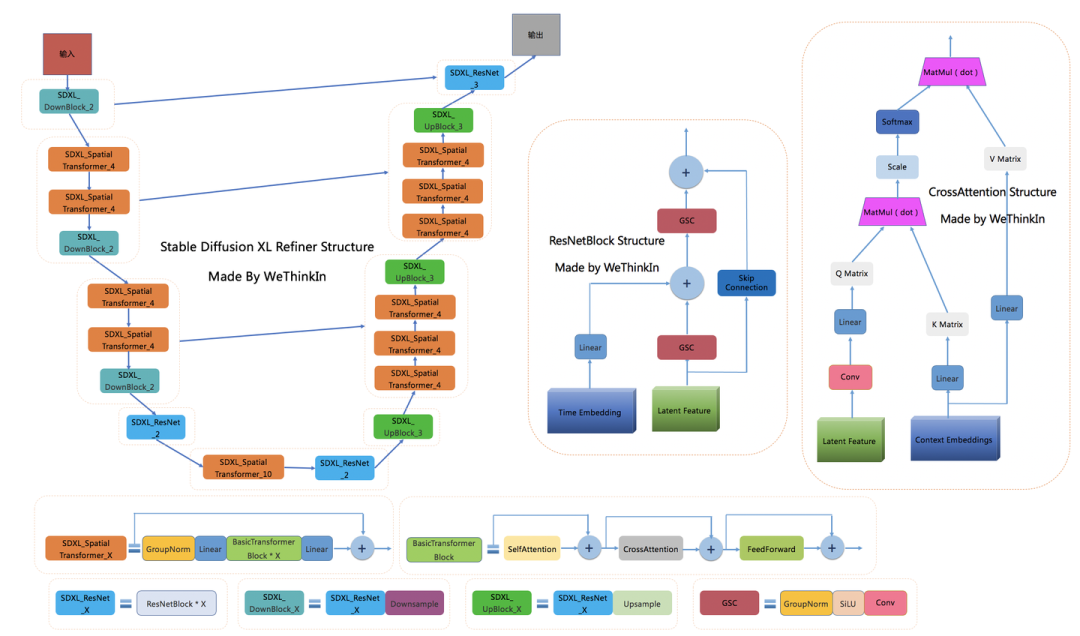

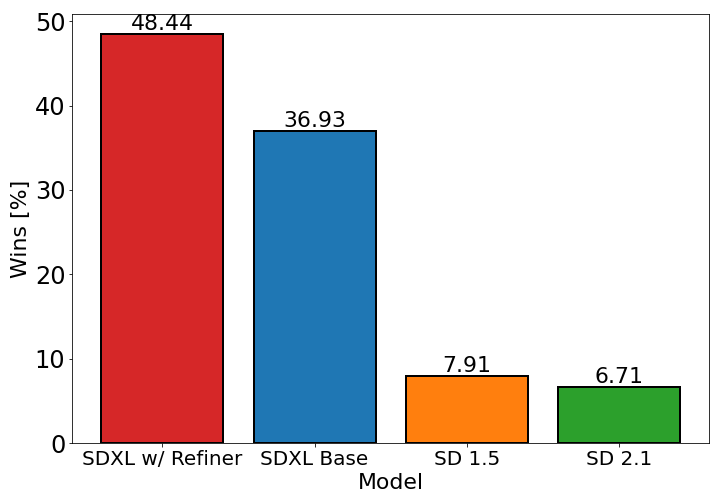
【七】Stable Diffusion XL训练技巧
图像尺寸条件化
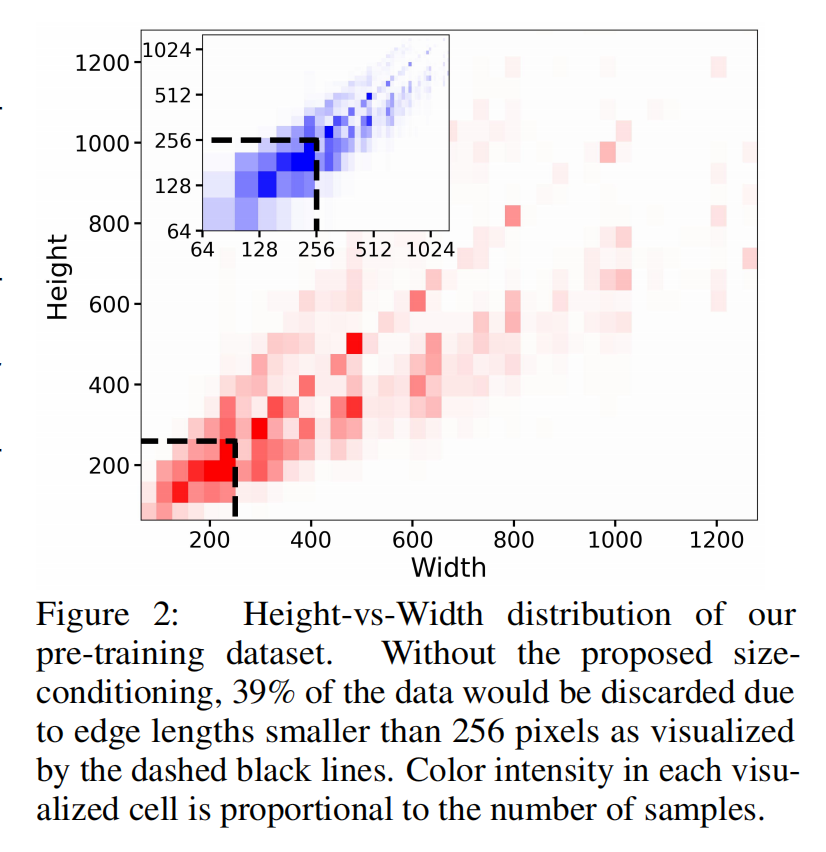

图像裁剪参数条件化




多尺度训练
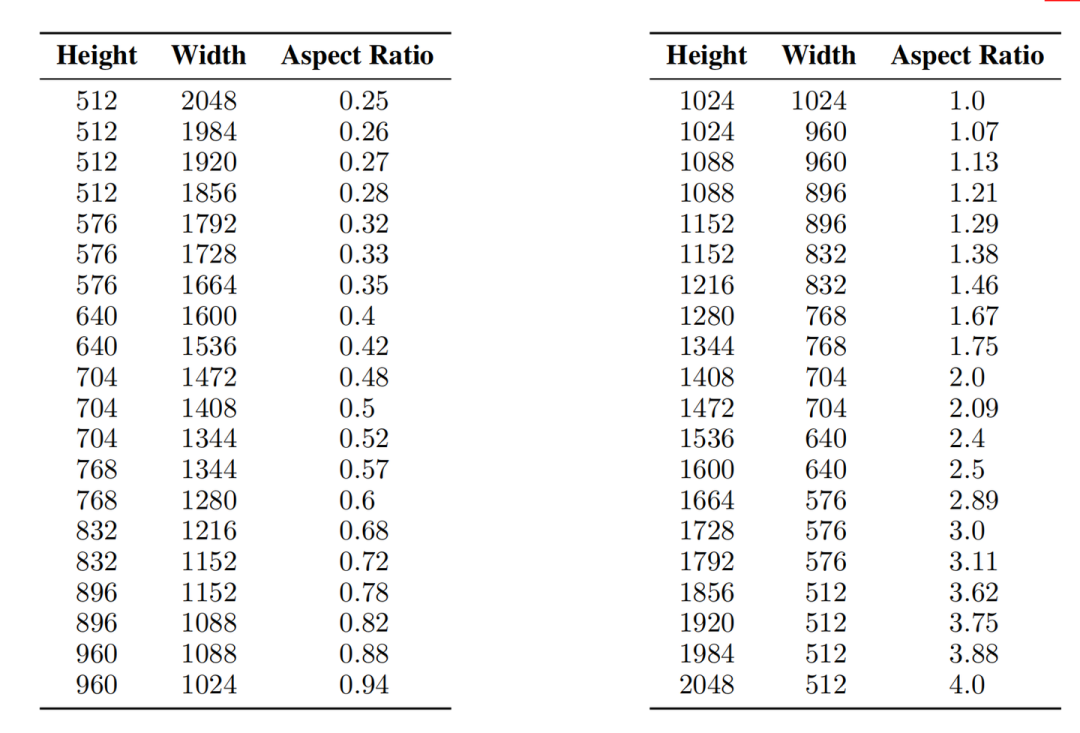
Stable Diffusion XL采用了多尺度训练策略,这个在传统深度学习时代头牌模型YOLO系列中常用的增强模型鲁棒性与泛化性策略,终于在AIGC领域应用并固化了,并且Stable Diffusion XL在多尺度的技术上,增加了分桶策略。
Stable Diffusion XL首先在256x256和512x512的图像尺寸上分别预训练600000步和200000步(batch size = 2048),总的数据量 600000 x 2000000 x 2048 约等于16亿。
接着Stable Diffusion XL在1024x1024的图像尺寸上采用多尺度方案来进行微调,并将数据分成不同纵横比的桶(bucket),并且尽可能保持每个桶的像素数接近1024×1024,同时相邻的bucket之间height或者width一般相差64像素左右,Stable Diffusion XL的具体分桶情况如下图所示:
精致的结尾
【八】推荐阅读

AIHIA | AI人才创新发展联盟2023年盟友招募
AIHIA | AI人才创新发展联盟2023年盟友招募

AI融资 | 智能物联网公司阿加犀获得高通5000W融资
AI融资 | 智能物联网公司阿加犀获得高通5000W融资

Yolov5应用 | 家庭安防告警系统全流程及代码讲解

江大白 | 这些年从0转行AI行业的一些感悟
Yolov5应用 | 家庭安防告警系统全流程及代码讲解
江大白 | 这些年从0转行AI行业的一些感悟

《AI未来星球》陪伴你在AI行业成长的社群,各项福利重磅开放:
(1)198元《31节课入门人工智能》视频课程;
(2)大白花费近万元购买的各类数据集;
(3)每月自习活动,每月17日星球会员日,各类奖品送不停;
(4)加入《AI未来星球》内部微信群;
还有各类直播时分享的文件、研究报告,一起扫码加入吧!


大家一起加油! 
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢