


导读 本次分享从基础背景开始,介绍为什么强化学习需要大模型、多智能体决策大模型有哪些挑战、如何描述此类系统。此后根据提出的问题,提出动作语义网络、置换不变性与置换同变性、跨任务自动化课程学习三个核心设计的先验。分享包括以下四个方面内容:
1. 多智能体决策大模型面临的挑战
2. 动作语义网络
3. 置换不变性、置换同变性
4. 跨任务自动化课程学习
分享嘉宾|郝晓田博士 天津大学
编辑整理|王雨润
出品社区|DataFun
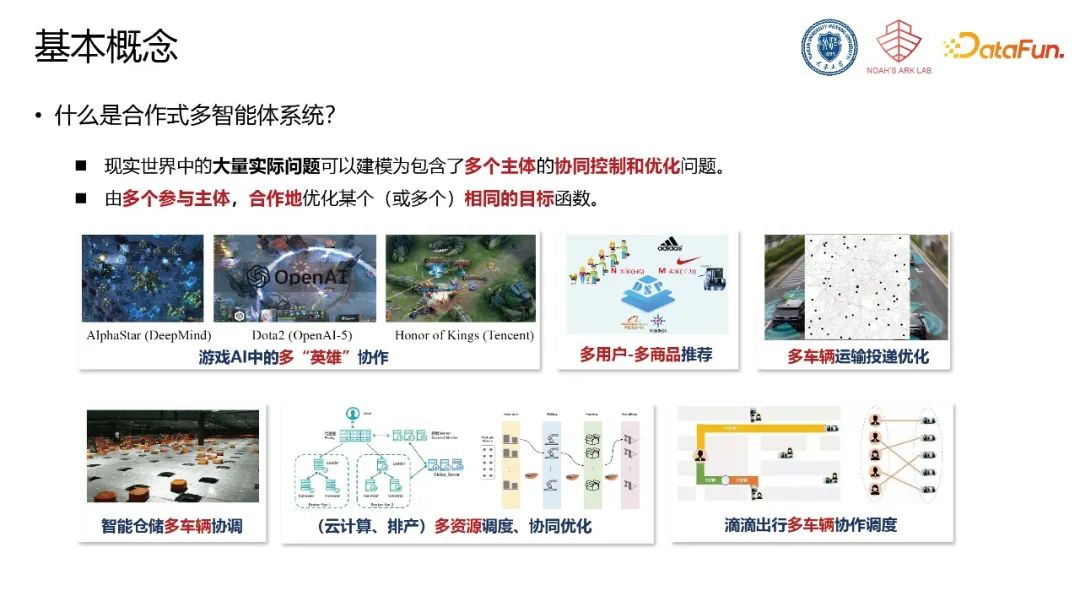
现实世界中的大量实际问题可以建模为包含了多个主体的协同控制和优化问题。合作式多智能体系统由多个参与主体,合作地优化某个(或多个)相同的目标函数,如:游戏AI中的多“英雄”协作、多用户-多商品推荐、多车辆运输投递优化、智能仓储多车辆调度、云计算多资源调度、多车辆协作调度等。
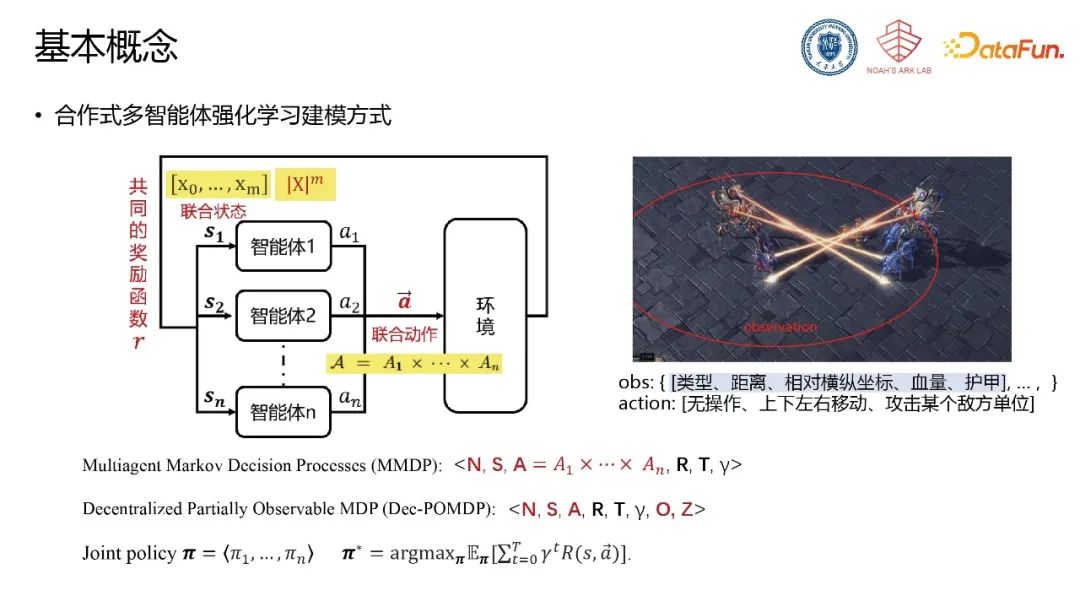
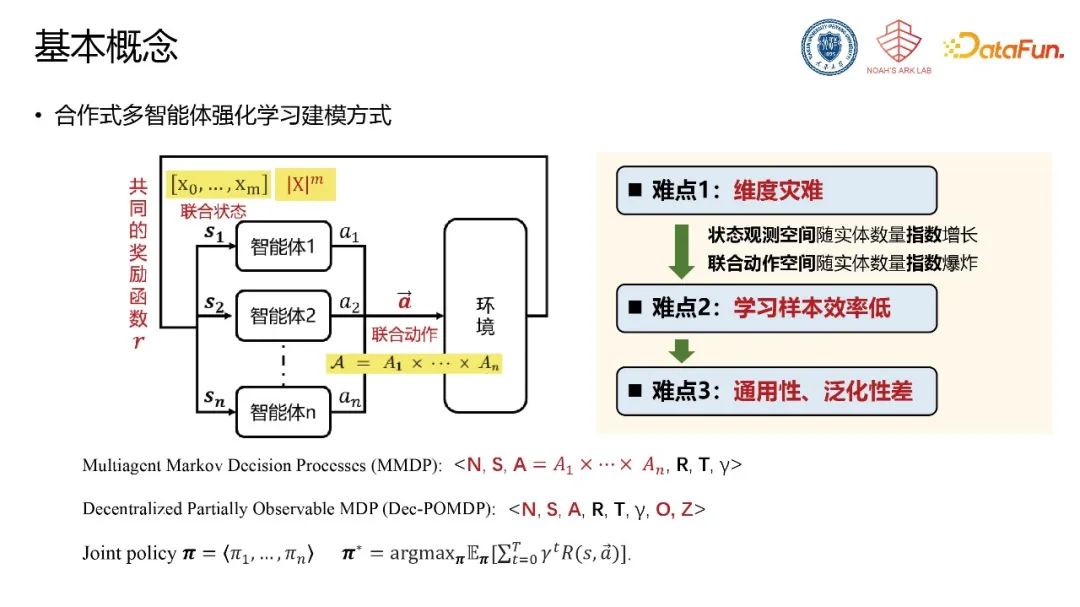

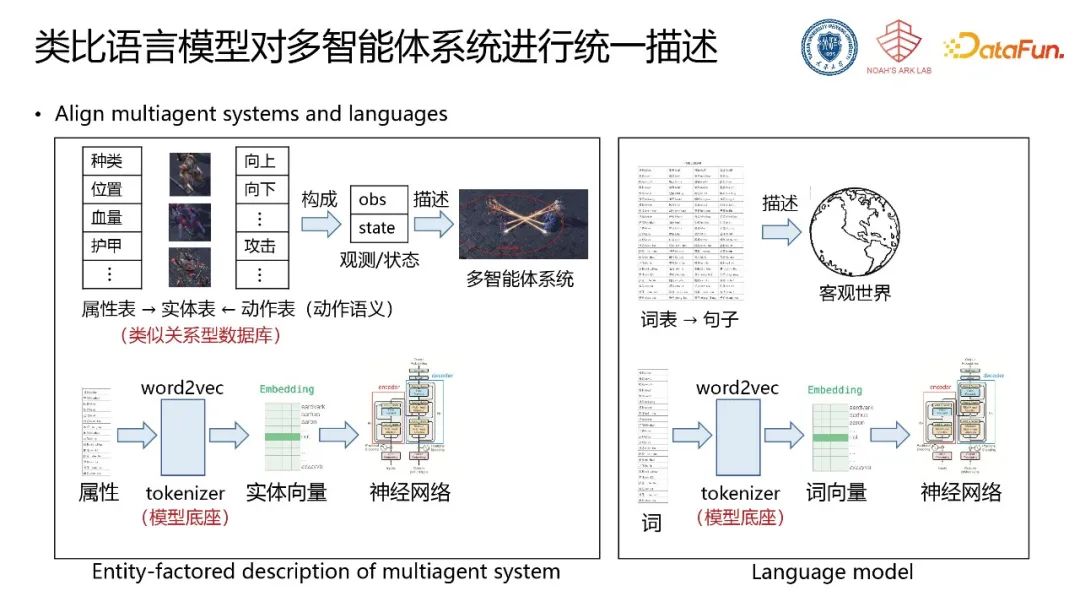
 针对以上挑战,需要对多智能体系统构建一套完备描述的方法,使得在该描述基础上设计通用的决策模型成为可能。类比语言模型,可对多智能体系统内部进行统一描述。大语言模型的底座由词表构成,词表构成句子,并形成对客观世界的底层描述。使用tokenizer将词转化为可学习的词向量,并对齐含义与维度,将词向量传递至神经网络中并针对具体任务进行训练。对应的,多智能体系统中通过全局的属性表与动作表(动作语义)形成对系统中实体的完备描述(实体表),通过tokenizer的方式将属性转化为属性向量与实体向量,将实体向量传递至后续策略网络等神经网络模型中,输出控制策略。
针对以上挑战,需要对多智能体系统构建一套完备描述的方法,使得在该描述基础上设计通用的决策模型成为可能。类比语言模型,可对多智能体系统内部进行统一描述。大语言模型的底座由词表构成,词表构成句子,并形成对客观世界的底层描述。使用tokenizer将词转化为可学习的词向量,并对齐含义与维度,将词向量传递至神经网络中并针对具体任务进行训练。对应的,多智能体系统中通过全局的属性表与动作表(动作语义)形成对系统中实体的完备描述(实体表),通过tokenizer的方式将属性转化为属性向量与实体向量,将实体向量传递至后续策略网络等神经网络模型中,输出控制策略。

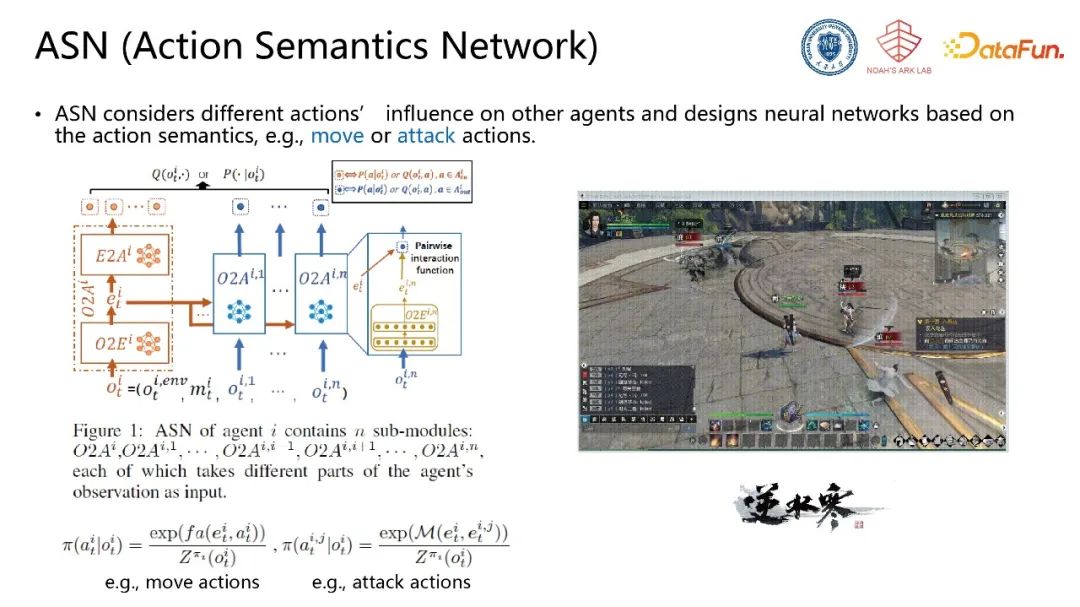
该先验知识的引入使得在星际争霸、Neural MMO等场景中模型性能有较大提升。该方案也落地到网易《逆水寒》游戏中,显著提升游戏AI的性能。



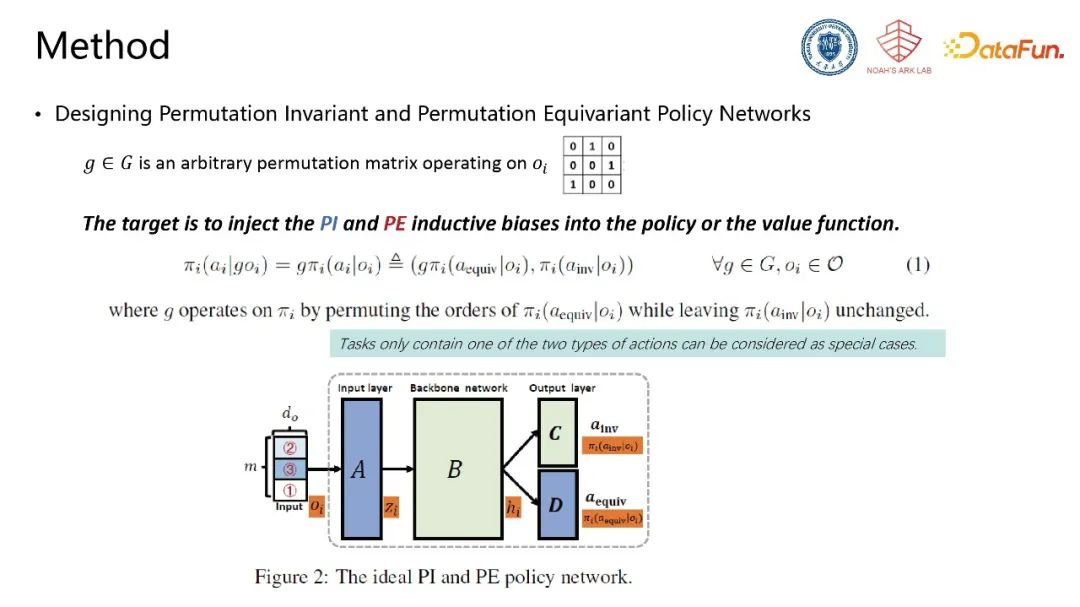
决策网络的输入是由多个实体构成的观测,经过典型的input layer、backbone layer(任意网络结构)和output layer,输出控制策略。我们期望输出中,仅与自身状态相关的动作不受输入顺序的影响(具备置换不变性),与输入实体有一一对应关系的动作与输入顺序的改变发生相同的变化(具备置换同变性)。为了设计更通用的模型架构,我们重点遵循“最小改动原理”,在尽量少地去改变已有网络结构的条件下达到期望性质,最终我们仅改动input layer A使其具备置换不变性,并将输入顺序信息告知并修改output layer D使其具备置换同变性。

传统不具备置换不变性的MLP网络输入可以视作每个实体信息乘上独立、对应的子模块参数并对输出进行加和。我们首先提出Dynamic Permutation Network (DPN),通过增加一个分类选择函数,实现为每个输入实体信息一一绑定确定的子模块参数,进而实现输入层的置换不变性。输出层要求与输入具有一一对应关系,构造类似的分类网络,为每一个实体的输出特征选择确定性的矩阵,使输出的顺序随输入顺序的变化发生协同的变化,从而实现置换同变性。

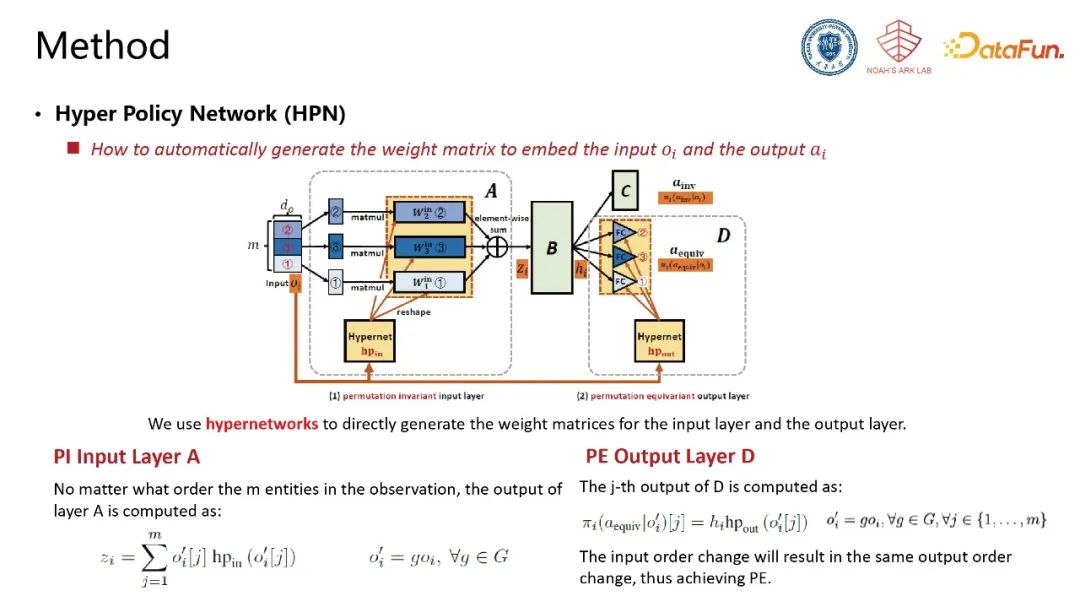
基于相同的思想,我们进一步提出Hyper Policy Network (HPN),利用“超网络”(用一个网络为另一个网络生成权重参数)自动化地为每个实体生成相应的参数矩阵。以每个实体的特征作为超网络的输入,超网络输出每个实体对应的参数,此结构下实体特征与参数矩阵天然具有一一对应关系,求和后的输出具备置换不变性。输出层利用超网络结构为每一个输入实体特征一一绑定地生成对应参数,使输出与输入实体存在一一对应关系,具备置换同变性。
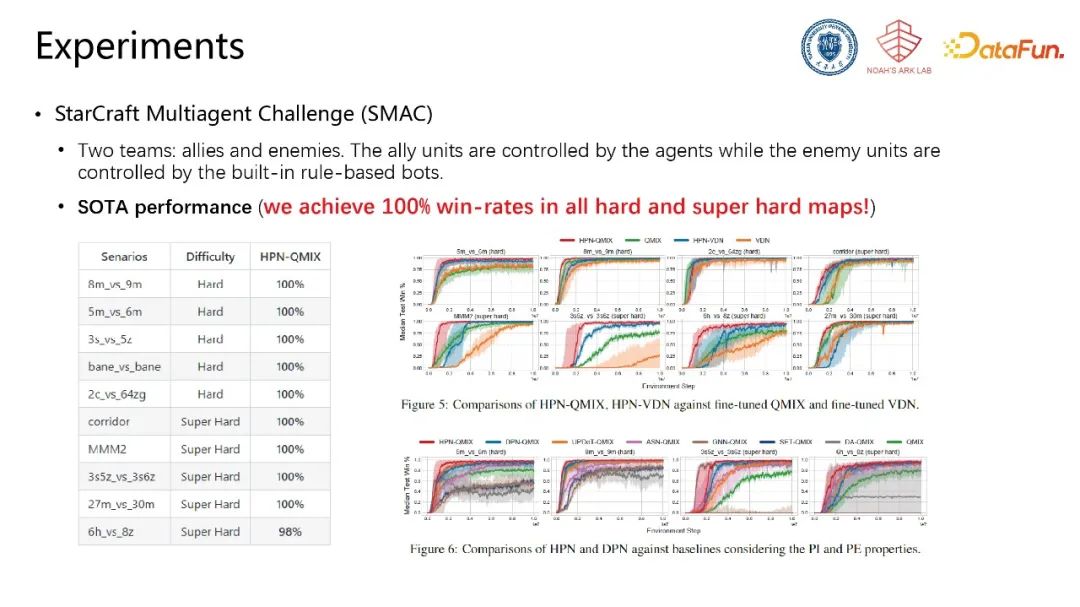
在典型的星际争霸测试环境中,将HPN的网络结构集成到QMIX算法,在所有困难场景均取得100%胜率。
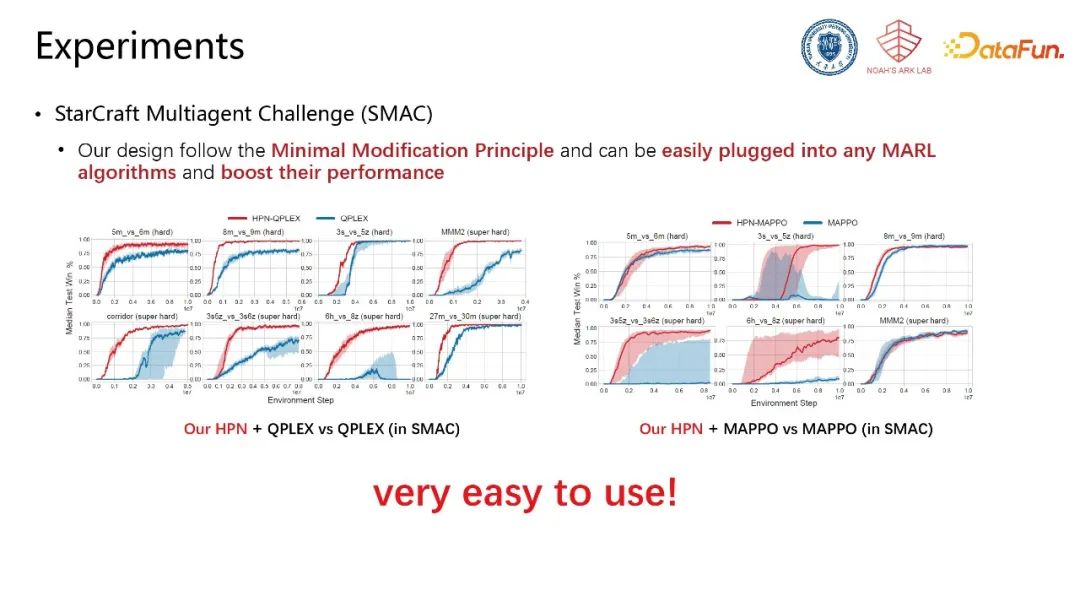
由于设计遵循最小改动原理,该网络结构可非常容易地集成至不同算法(如QPLEX、MAPPO)中,并使算法性能得到较大提升。
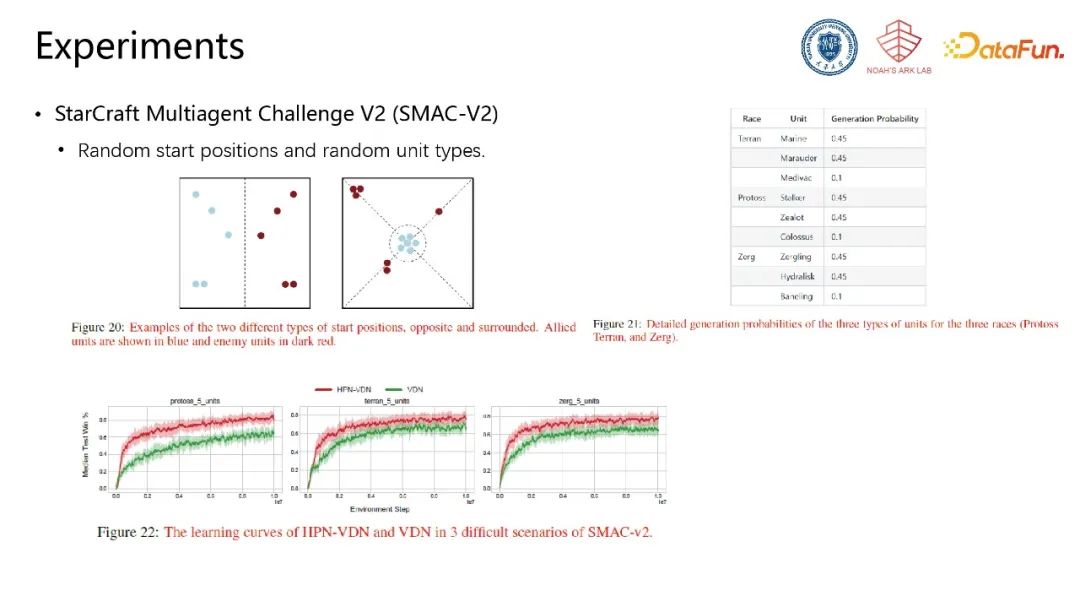
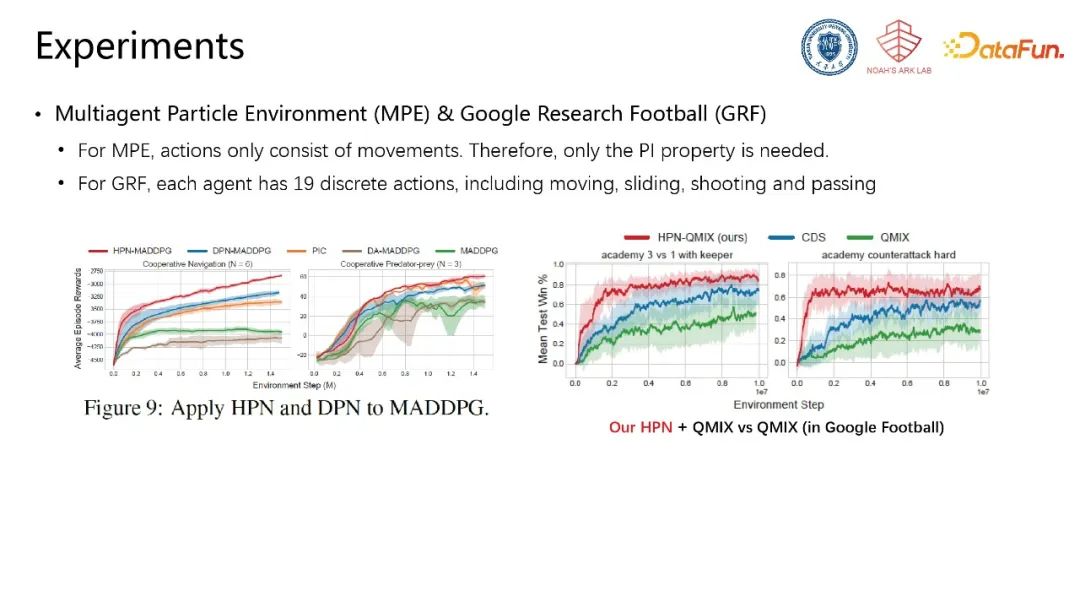
此外,在星际争霸V2、MPE、谷歌足球等更复杂、随机性更强的环境中,该模型架构同样能够取得明显的性能优势。
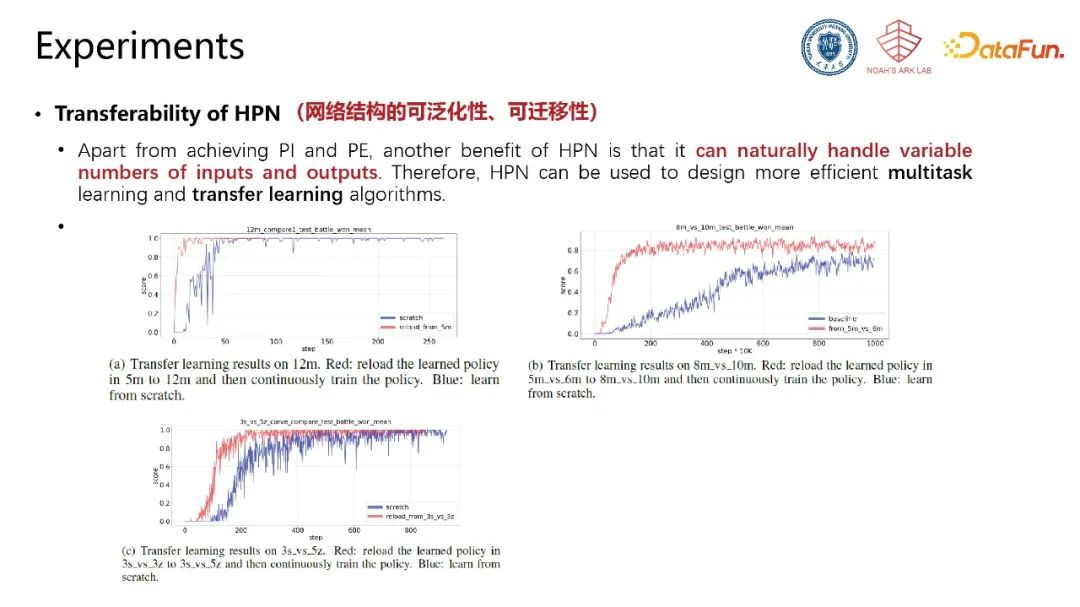
 同时,由于该网络结构能自动适应由不同实体带来的输入维度不同与输出维度不同的问题,因此具有较好的可泛化性与可迁移性,能够实现不同数量不同规模任务中控制策略的高效复用。
同时,由于该网络结构能自动适应由不同实体带来的输入维度不同与输出维度不同的问题,因此具有较好的可泛化性与可迁移性,能够实现不同数量不同规模任务中控制策略的高效复用。
在跨任务的课程学习过程中,系统中存在多个待学习的任务,包括难度较大的目标任务、较简单的起始任务与其他候选的任务集合,课程学习算法每一步需要从候选任务集合中选出最合适的任务从而最终输出一条“最优学习序列(路径)”。解决该问题需要回答两个核心问题:
①选哪个课程作为下一个学习目标合适?
②前面学到的知识在新的课程中如何复用?

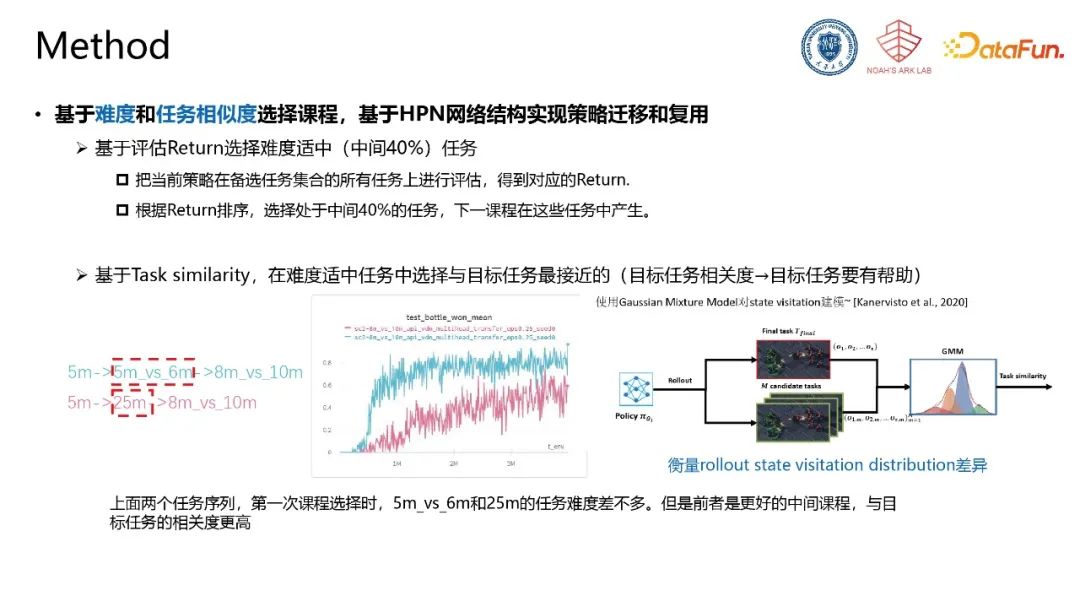
我们提出基于难度和任务相似度选择课程。把当前策略在备选任务集合的所有任务上进行评估,得到相应的奖励值。根据奖励值排序,选择处在中间40%的任务,下一课程在这些任务中产生。同时基于任务相似度,在难度适中的候选任务中选择与目标任务最接近的任务作为最终选定的课程。为了评估与目标任务的相似度,基于当前策略在目标任务和候选任务中进行rollout获得状态访问分布,利用混合高斯模型对该分布进行建模,利用分布相似性衡量任务相似性。
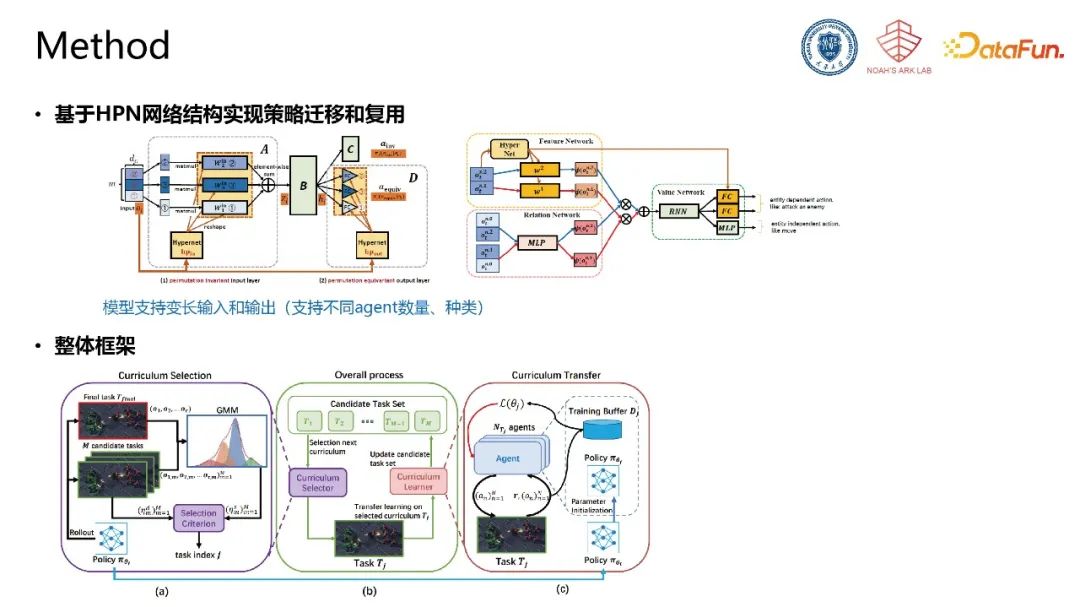
基于HPN网络结构实现策略迁移和复用。采用前述具有置换不变性和置换同变性,同时支持变长输入和输出的HPN网络结构实现策略的迁移和复用。自动化课程学习的整体框架为,利用难度和相似度选定下一个学习任务,该任务学习过程中利用HPN的结构重载上一个任务学得的策略,依次循环,最终在目标任务上取得更好的性能。
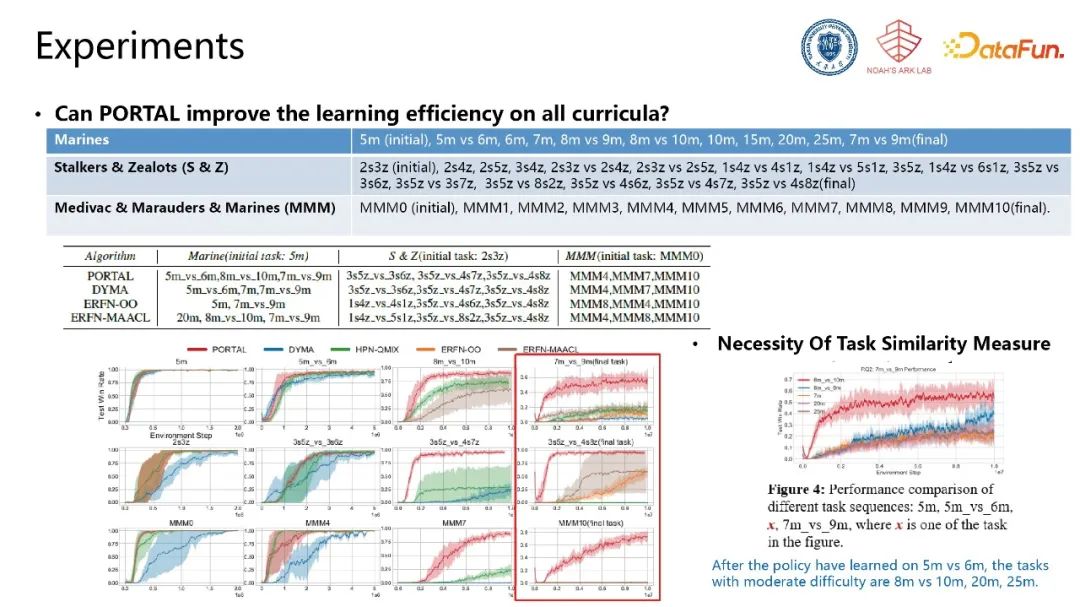
我们在星际争霸场景中进行算法验证,根据种族类型,将星际争霸中的游戏场景分成不同的任务集合(Marines,Stalkers & Zealots,以及Medivac & Marauders & Marines),每个任务集合均给定起始任务与难度极大的最终任务。对比经典迁移学习算法,不同算法在任务选择序列上具有较大差异,我们算法能够基于任务难度和对最终任务的帮助程度选择出更适合的任务序列,在最终的任务中能够取得非常大的性能提升。
最后,我们将系列工作的源代码开源,将MARL社区常用的pymarl2 (https://github.com/hijkzzz/pymarl2 )代码库升级为pymarl3(https://github.com/tjuHaoXiaotian/pymarl3),其特性如下:
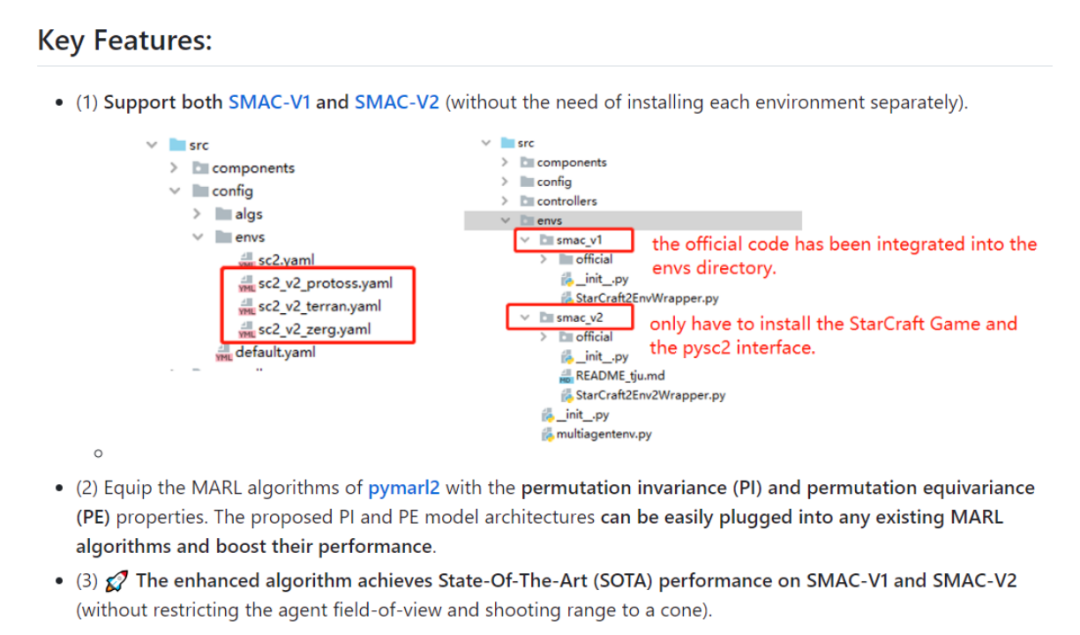
(1)增加对SMAC-V2(https://github.com/oxwhirl/smacv2)的支持,同时支持SMAC-V1和SMAC-V2,已集成在内,无需独立安装各个环境。
(2)升级pymarl2中的算法,使其具备置换不变性和置换同变性,设计的网络结构可非常容易地集成到任意MARL算法中,并提升其性能。
(3)增强版算法,在SMAC-V1和SMAC-V2上均取得SOTA的性能。


今天的分享就到这里,谢谢大家。


分享嘉宾
INTRODUCTION

郝晓田 博士
天津大学
郝晓田,天津大学智能与计算学部3年级博士生,导师为郝建业副教授,研究方向为强化学习与组合优化。在ICML、NeurlPS、ICLR、IJCAI等国际顶级会议发表一作论文6篇,并担任多个会议审稿人,曾在阿里妈妈核心广告算法团队、华为决策推理实验室企业智慧、决策推理研究等团队实习,有丰富的落地实践经验。曾提出基于二叉树的单纯形算法,针对华为核心排产问题(千万变量),线性规划求解时间提速一倍以上。曾获华为诺亚方舟实验室优秀实习生、研究生国家奖学金。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢