
论文题目:Stack More Layers Differently: High-Rank Training Through Low-Rank Updates 作者:Vladislav Lialin, Namrata Shivagunde, Sherin Muckatira, Anna Rumshisky 机构:University of Massachusetts Lowell

本文探索了一种称为ReLoRA的低秩训练技术,它利用低秩更新来训练高秩网络。作者在语言模型预训练任务上评估了ReLoRA,结果表明它能够实现与常规神经网络训练相当的性能。此外,作者观察到ReLoRA的效率随着模型大小的增大而提高,这使其成为高效训练数十亿参数网络的有希望方法。作者的发现为低秩训练技术的潜力及其对缩放定律的影响提供了启示。
过去十年,机器学习领域主导趋势是训练越来越过参数化的网络或采用“堆叠更多层”的方法。但是大模型的必要性理论上仍然不清楚。
替代大模型的方法虽然提供了新的权衡,但并没有让我们更理解为什么需要过参数化模型,也很少使大模型的训练普及化。
本文关注低秩训练技术,并提出了ReLoRA,它使用低秩更新来训练高秩网络。作者证明ReLoRA实现高秩更新,达到与常规神经网络训练相当的性能。
ReLoRA的效率随模型大小增加而提高,这使它成为大规模语言模型潜在的高效训练方法。
矩阵的秩满足以下性质:
这个上界是紧的,对于矩阵A,存在矩阵B,使得的秩高于A和B。作者想利用这个性质构建一个灵活的参数高效训练方法。
LoRA是一种基于低秩更新的精调技术。它将权重更新分解为低秩产物:
其中是一个固定缩放因子,通常取。
LoRA通过添加新参数和来实现,训练结束后可以融合回原始参数。尽管公式1允许总更新的秩高于任一,但LoRA受限于最大秩。
作者提出了ReLoRA来通过重启增加有效秩。
ReLoRA合并参数并重新初始化和,从而累积秩:
重复重新初始化足够独立,则。
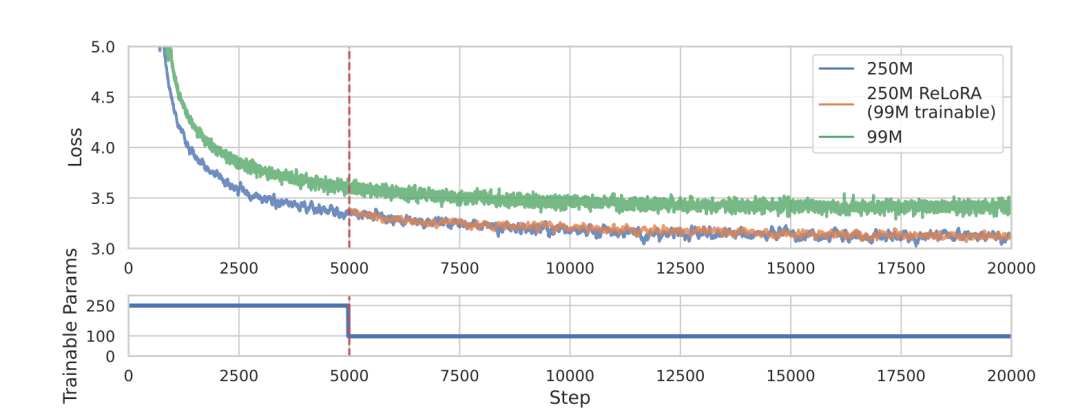
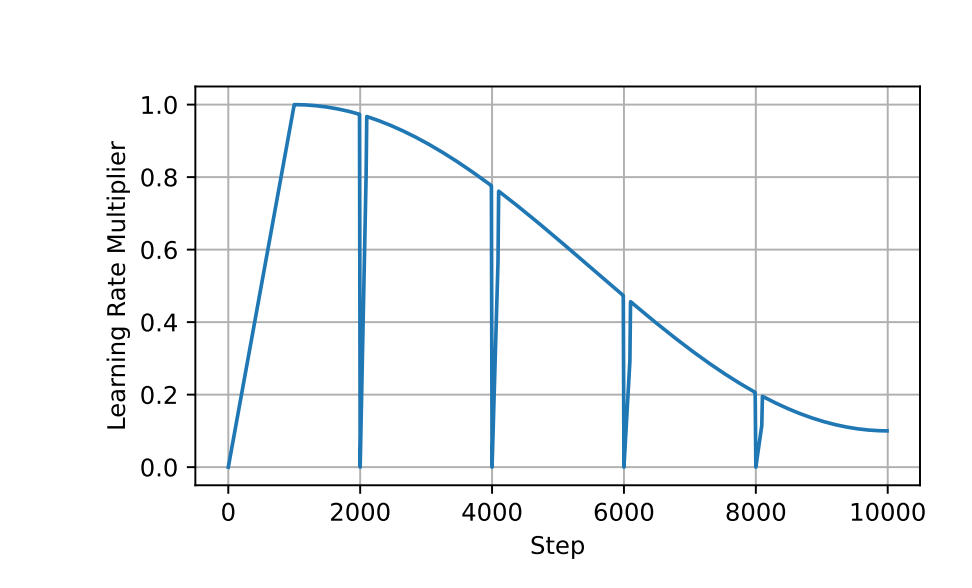
ReLoRA还使用部分优化器重置、锯齿学习率计划等技巧稳定训练。这些修改允许ReLoRA接近全秩训练,只需每次训练少量参数。
ReLoRA的困惑度显著优于LoRA,证明了作者的修改是有效的。
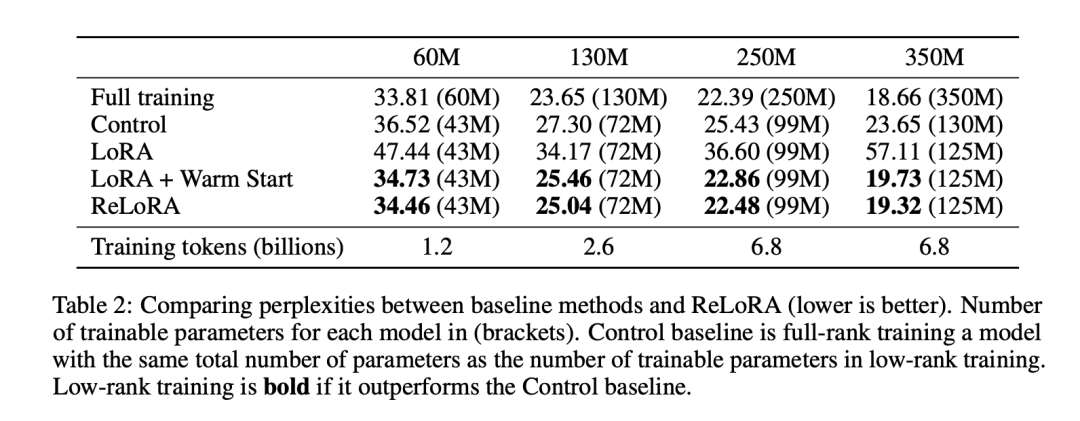
ReLoRA达到了与全秩训练相当的性能。随着模型大小的增大,性能差距缩小。
ReLoRA的奇异值谱与全秩训练更加接近,而LoRA大多数奇异值都是0。这表明ReLoRA通过低秩更新进行了高秩训练。
ReLoRA的效率随模型大小增加而提高,这使其成为大规模训练的可行选择。
低秩训练技术具有巨大的前景,可以提高大语言模型训练的效率,并可以帮助作者理解神经网络的可训练性和泛化能力。本文提出的ReLoRA利用低秩更新训练高秩网络,性能接近全秩训练,且随模型大小扩大效率提升,成为超大参数网络高效训练的候选方法。作者的发现为低秩训练技术的潜力及其对缩放定律的影响提供了启示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢