
点击下方卡片,关注「集智书童」公众号

近年来,视觉Transformer在解决各种视觉感知任务方面表现出了前所未有的性能。然而,这些网络架构的结构和计算复杂性使它们在需要高吞吐量和低内存要求的实际应用中难以部署。
因此,最近在设计高效的视觉Transformer架构方面进行了重要研究。在本研究中,作者通过生成式架构搜索(GAS)探索了快速视觉Transformer架构设计的生成,以实现精确性与架构和计算效率之间的强大平衡。通过这个生成式架构搜索过程,作者创建了TurboViT,这是一个高效的分层视觉Transformer架构设计,它是围绕Mask单元注意力和Q-pooling设计模式生成的。
结果显示,TurboViT架构设计在架构计算复杂性方面显著更低(与FasterViT-0相比,大小缩小了2.47倍以上,同时达到了相同的准确性),在计算复杂性方面也更低(与MobileViT2-2.0相比,FLOP减少了3.4倍以上,准确性提高了0.9%以上),与ImageNet-1K数据集上的其他10种最先进的高效视觉Transformer网络架构设计相比,它们都在相似准确性范围内。
此外,TurboViT在低延迟和批处理处理场景中都表现出强大的推理延迟和吞吐量(与FasterViT-0相比,低延迟场景中的延迟降低了3.21倍以上,吞吐量提高了3.18倍以上)。这些结果表明,利用生成式架构搜索来生成高吞吐量场景下高效的Transformer架构设计的有效性。
近年来,视觉Transformer在应对各种视觉感知任务方面表现出了前所未有的性能水平。然而,这些网络架构的结构和计算复杂性使它们在需要高吞吐量和低内存要求的实际应用中难以部署。因此,最近在设计高效的视觉Transformer架构方面进行了重要研究。
例如,Cai等人引入了一个轻量级的多尺度注意机制,仅包括轻量级和硬件高效的操作。Vasu等人引入了一种混合卷积-Transformer架构设计,利用结构性重参数化来降低内存访问成本。Hatamizadeh等人引入了一种分层注意方法,将全局自注意力分解为多层次的注意力,以降低计算复杂性。另一种有趣的方法是由Wu等人提出的,他们不仅在视觉Transformer中引入了卷积,还采用了适应数据的神经架构搜索来发现高效的视觉Transformer架构设计。作者将沿着这个网络架构搜索的方向探索,以找到高效的视觉Transformer,但是作者将通过一种生成式方法来实现。
在本研究中,作者探讨了通过生成式架构搜索(GAS)来生成快速视觉Transformer架构设计,以实现精度与架构和计算效率之间的强大平衡。通过这个生成式架构搜索过程,作者创建了TurboViT,这是一种高效的分层视觉Transformer架构设计,围绕Mask单元注意力和Q-pooling设计模式生成。
在这项研究中,作者利用Generative Synthesis进行了生成式架构搜索(GAS),以确定TurboViT的架构设计。更具体地说,Generative Synthesis可以被公式化为一个受限制的优化问题,其目标是在由指示函数定义的一组操作约束下,找到生成网络架构N的最优生成器,以最大化通用性能函数U。
这个受限制的优化问题以迭代方式解决,完整的过程描述在Generative Synthesis中提供。在这项研究中,作者通过引入以下设计约束,以确定TurboViT的视觉Transformer架构设计,以满足适用于高吞吐量场景的期望计算复杂性:

利用全局注意力和Mask单元注意力设计模式,如Hiera中所介绍的。这些设计模式已被证明可以大大简化视觉Transformer架构的复杂性,同时不损失准确性,因为它们放弃了视觉特定的组件。
强制在3个位置使用Q-pooling设计模式,通过类似Hiera的方式通过减少空间查询来降低架构和计算复杂性,从而得到分层架构设计。
强制计算复杂性约束为2.5 GFLOPs,以确保TurboViT在高吞吐量场景下具有较低的计算复杂性(低于本研究中比较的所有最先进的视觉Transformer架构设计)。
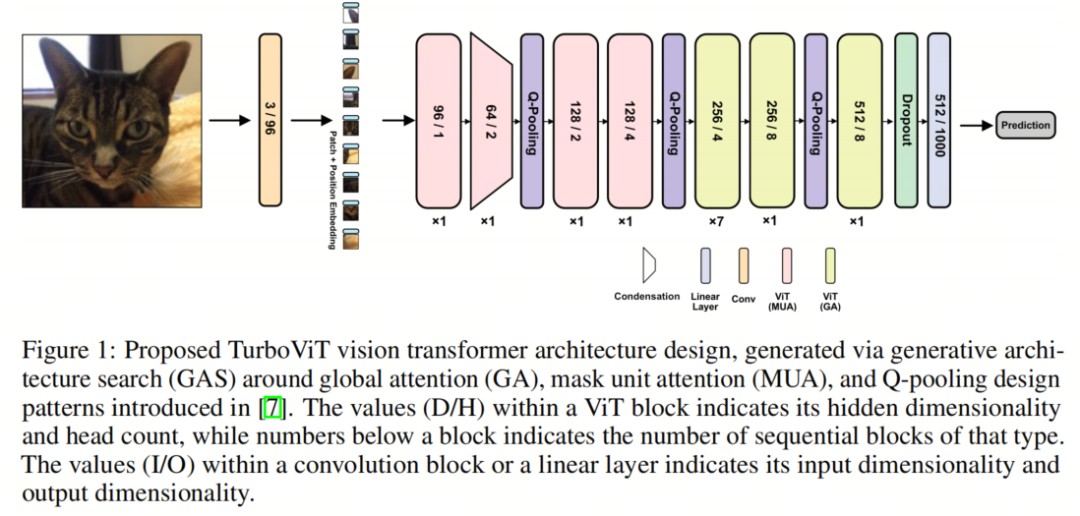
图1展示了通过生成式架构搜索生成的TurboViT架构设计。总体而言,可以观察到与其他最先进的高效视觉Transformer架构设计(特别是更复杂的混合卷积-Transformer架构设计)相比,该架构设计相当简洁和流畅,主要由一系列ViT块组成,具有相对较低的隐藏维度以及相对较低的头数(特别是与ViT相比),因此有助于实现更大的架构和计算效率。
正如预期的那样,可以观察到TurboViT架构设计在3个不同位置包括Q-pooling,以通过空间减少实现架构和计算效率,大多数层位于第2个Q-pooling之后。还可以观察到,在TurboViT架构设计中,较早的ViT块通过Mask单元注意力利用局部注意力,而较晚的ViT块则通过全局注意力利用全局注意力,因此在计算效率方面没有使用全局注意力,而是在架构中获得了显著的计算效率提升。
关于TurboViT架构设计的一个特别有趣的观察是,在架构设计的开始处引入了1个隐藏维度浓缩机制,其中隐藏维度在第2个ViT块处大大减小,形成与第1个ViT块相比高度浓缩的嵌入,然后,随着作者在架构中移动,隐藏维度逐渐增加。这样的浓缩机制似乎在极大地减少计算复杂性的同时,在整体架构设计中仍然实现了高度的表征能力。
本研究在ImageNet-1K数据集上评估了提出的TurboViT架构设计,并与10种不同的最先进高效视觉Transformer架构设计进行了比较,这些设计在图像分类(MobileViTv2-2.0、MViTv2-T、Swin-T、SwinV2-T、CvT-13-NAS、FastViT-SA24、LITv2-S、FasterViT-0、PiT-S和Twins-S)方面具有相似的准确性。
比较使用了3个指标:
Top-1准确性 架构复杂性(基于参数数量) 计算复杂性(基于FLOP数量)
此外,对于TurboViT、FastViT-SA24和FasterViT-0,作者还在Nvidia RTX A6000 GPU上对两种不同场景下的推理延迟和吞吐量进行了比较。
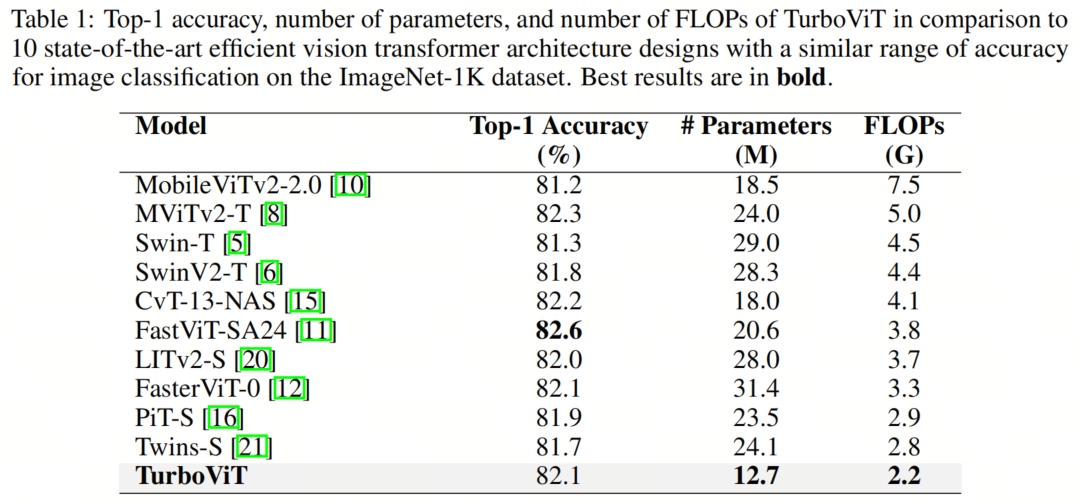
表1展示了提出的TurboViT架构设计与10种不同的最先进高效视觉Transformer架构设计之间的比较。就架构复杂性而言,与本次比较中的所有其他最先进高效视觉Transformer架构设计相比,TurboViT显著更小。
例如,TurboViT与FasterViT-0相比要小2.47倍以上,但准确性相同,与MobileViT2-2.0相比要小1.45倍以上,同时准确性还提高了0.9%。即使与CvT-13-NAS比较,后者是第2小的视觉Transformer架构设计,也是本研究中唯一通过网络架构搜索创建的设计,TurboViT也要小1.41倍以上,但准确性相似。
在计算复杂性方面,TurboViT所需的FLOP数量远远少于本次比较中的所有其他最先进高效视觉Transformer架构设计。例如,TurboViT所需的FLOP数量要比MobileViT2-2.0少3.4倍以上,同时准确性提高了0.9%。
与本研究中唯一通过网络架构搜索创建的另一个设计(CvT-13-NAS)相比,TurboViT所需的FLOP数量少1.86倍以上。即使与FLOP需求第2低的Twins-S比较,TurboViT也需要1.27倍以上的FLOP数量,同时准确性提高了0.4%。
就准确性而言,TurboViT在比所有其他最先进高效视觉Transformer架构设计更低的架构复杂性和计算复杂性下,实现了强大的Top-1准确性。例如,TurboViT的准确性比Swin-T和SwinV2-T分别高0.8%和0.3%,尽管它所需的FLOP数量分别少于它们的2.04倍和2倍。
与本研究中唯一通过网络架构搜索创建的另一个设计(CvT-13-NAS)相比,TurboViT实现了非常相似的Top-1准确性(只低了0.1%),但在架构复杂性和计算复杂性方面要小得多(分别小1.41倍和1.86倍)。
最后,TurboViT的Top-1准确性仅比本研究中表现最好的高效视觉Transformer架构设计(FastViT-SA24)低0.5%。然而,值得注意的是,TurboViT要小1.62倍以上,FLOP数量要少1.72倍以上。
在推理延迟和吞吐量方面,作者评估了两种不同的场景:
低延迟处理(使用Batch-size为1)
批处理(使用Batch-size为32)
表2比较了TurboViT、FasterViT-0和FastViT-SA24在Nvidia RTX A6000 GPU上的推理延迟和吞吐量。可以观察到,在低延迟处理场景中,TurboViT在延迟方面明显优于FasterViT-0和FastViT-SA24,延迟分别提高了3.21倍以上和1.66倍以上。
此外,TurboViT在该场景的吞吐量比FasterViT-0和FastViT-SA24分别高出3.18倍以上和1.53倍以上。可以观察到,在批处理场景中,TurboViT在延迟方面明显优于FastViT-SA24,延迟降低了1.54倍以上,吞吐量提高了1.56倍以上。有趣的是,在这种情况下,TurboViT和FasterViT-0的延迟和吞吐量表现相当。
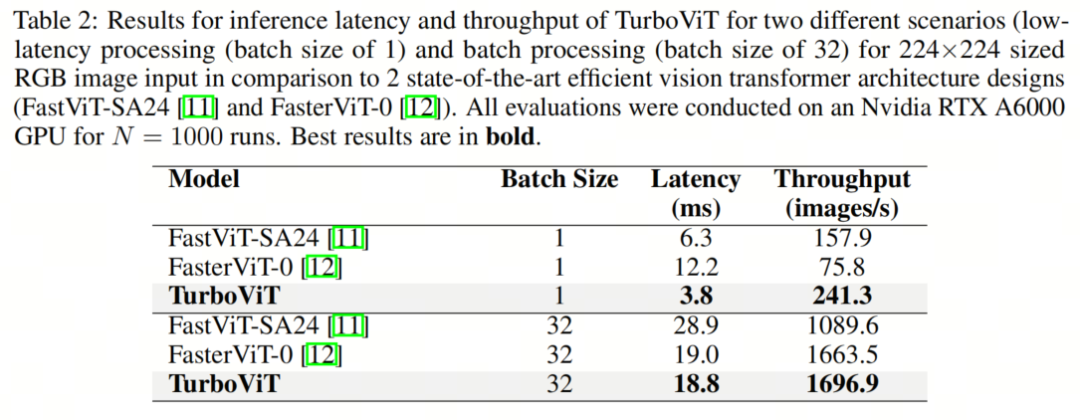
这些结果表明,TurboViT在准确性、架构复杂性、计算复杂性以及在低延迟和批处理场景下都表现出强大的延迟和吞吐量之间取得了良好的平衡,因此非常适合高吞吐量的用例。此外,这些结果表明,利用生成式架构搜索生成高效的Transformer架构设计对于高吞吐量场景非常有效。
[1]. TurboViT: Generating Fast Vision Transformers via Generative Architecture Search.

DETR忆往昔 | 全面回顾DETR目标检测的预训练方法,让DETR训练起来更加丝滑
训练Backbone你还用EMA?ViT训练的大杀器EWA升级来袭
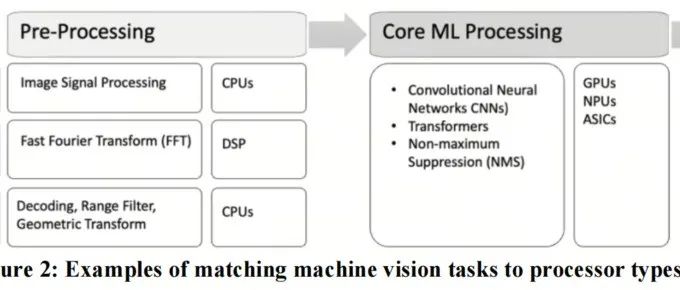
ADAS落地 | 自动驾驶的硬件加速

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)





前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢