
前言 本文介绍了3D Deformable Attention (DFA3D),一种全新的将2D特征拉升到3D空间的基础算子。和现有的基于Lift-Splat的方法以及基于2D注意力机制的方法相比,我们的方法即能受益于Transformer的多层优化能力来解决Lift-Splat中的one-pass问题又可以保持对深度感知来解决2D注意力机制中深度模糊(Depth Ambiguity)问题。我们在数学的角度对DFA3D进行了工程上的优化,并提供了CUDA实现。我们在多个使用基于2D注意力机制进行特征拉升的多视角3D目标检测方法上验证了其有效性。
论文:https://ttps://arxiv.org/abs/2307.129722
代码:https://github.com/IDEA-Research/3D-deformable-attentionh/3D-deformable-attention
1、简介
1. 2D主干网络,用来对输入的多视角图片进行编码,得到2D图像特征; 2. 2D到3D的特征拉升,用来将上一步中获取到的2D图像特征拉升到3D空间中预定义的一些锚点上,得到拉升后的3D特征; 3. 基于拉升后的3D特征做3D目标检测。
1. 由Lift-Splat-Shoot提出的基于Lift-Splat的特征拉升方法(如下图a),虽然具有对深度的感知能力,但是由于该方法中3D锚点和2D图像特征之间的关系是由确定的几何关系固定了的,无法进行调整,因此,该拉升方法在整个3D目标检测流程中只能进行一次,一旦有任何误差便无法纠正回来。除此之外该方法还有一个小缺点,由于在拉升过程中需要显式地根据2D特征构建3D特征,2D特征的分辨率就不能太大,否则显存占用会急速膨胀。 2. 基于2D注意力机制的特征拉升方法,例如由PETR提出的基于dense attention的、由BEVFormer提出的基于deformable attention的、由DETR3D提出的基于point attention(deformable attention的一种退化形式,只有一个采样点)的等等。在这类方法中,3D锚点与2D图像特征之间的关系是由学习到的采样点确定的,是可调整的,因此该拉升方法在整个检测流程中可以多次进行,从而进行优化。但,由于这类拉升方法直接将深度方向给忽略掉了,因此存在深度模糊问题。更具体的,如下图(b,c)所示,多个3D锚点投影到某个视图的时候,会落到十分相近的位置,导致他们采样到的特征耦合的十分严重,最终引起误检。
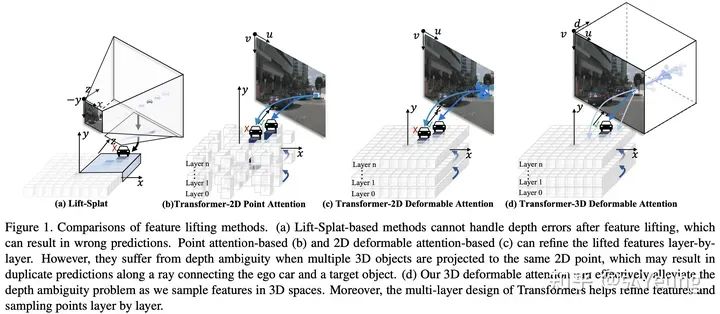
2、方法
2.1 3D Deformable Attention及基于其的特征拉升
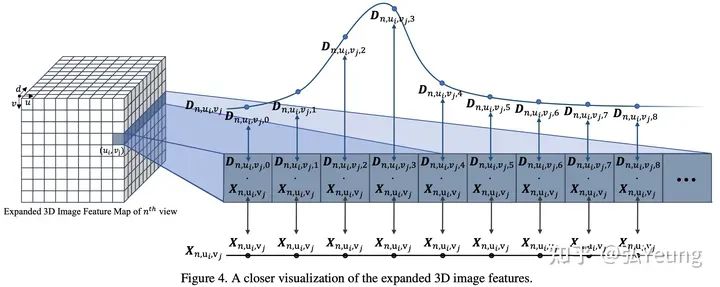
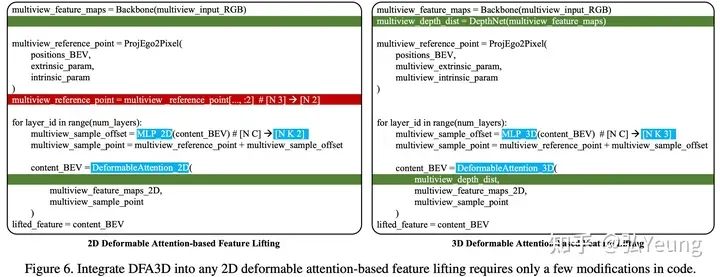
首先,和BEVDet这类方法类似,我们将该2D图像特征图 送入到一个深度估计子网络中来为每个2D特征估计深度,并将该深度通过深度分布的形式 将深度表示出来,其中,V表示视角数(比如在nuScenes数据集上为V=6),H和W表示特征图的大小,C表示2D特征的维度,D表示深度方向被量化后的类别数量。而后,将每个2D图像特征与其对应的深度分布做外积来将2D图像特征图沿着深度轴延展成一个3D特征图(expanded 3D feature map) , 。和Lift-Splat这类方法不同的是,我们并没有将延展后的3D特征图 通过相机内外参转换到自车坐标系从而生成伪雷达特征,而是将他们留在图像坐标系不动。除此之外,在内存空间维持这个3D特征图会消耗大量的显存资源,这就使得Lift-Splat这类方法无法使用大尺度的2D特征图,限制了其对小和远距离物体的感知能力。在下一部分中我们将会解释我们如何通过数学上的优化来使得我们无需真正地执行这个外积,也无需维持这么巨大的特征在内存空间。 将自车坐标系下的3D锚点看作是3D查询(query),而步骤1中得到的3D特征图 看作是3D键值对(key,value)。每一个3D查询根据自身的3D坐标以及当前视角相机的内外参数投影到当前视角的图像坐标系下。该3D查询进一步根据自身的语义特征(content feature,该特征是随机初始化的)来估计该查询具体应该在哪些位置(sampling locations)对3D键值对进行采样(trilinear sampling),以及采样到的特征应该被赋予多少的注意力(attention)。对于每一个3D查询,将它采样到的特征以及他们所对应的注意力值做加权求和便得到了该视角在该3D查询所在的3D坐标的拉升结果。这一步骤实际上也就是3D Deformable Attention这一算子内部机制的具体内容。 对于每一个3D查询,将在多个视角多个尺度下的到的拉升结果聚合在一起,这样之后,一次特征拉升过程便结束了。但,聚合得到的特征可以用于更新该3D查询的语义特征,并可以再次进入到步骤2进行再一次的特征拉升。由于此时3D查询的语义特征更加有意义,再一次的特征拉升所得到的结果也将更好。
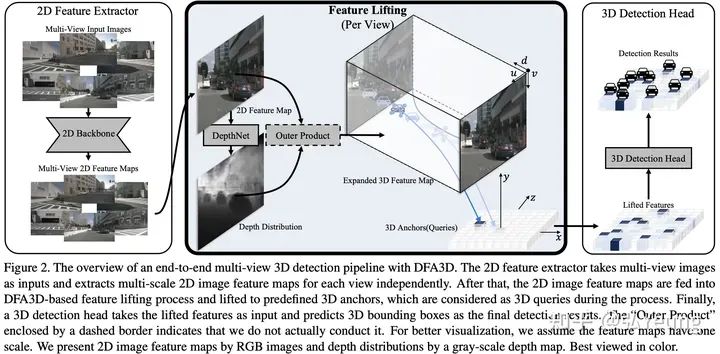
2.2 3D Deformable Attention的优化
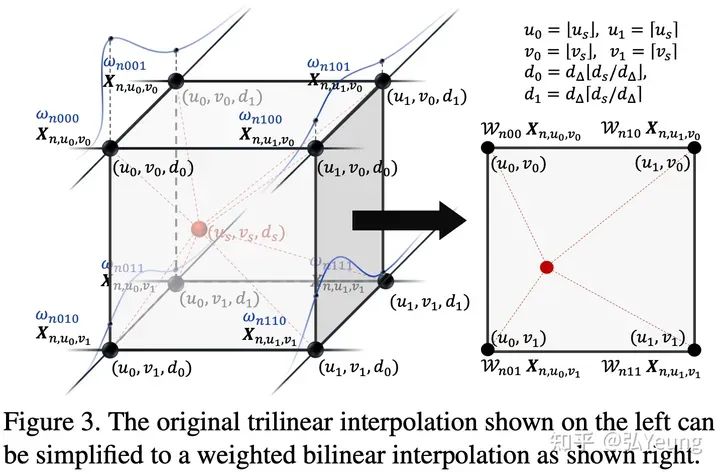
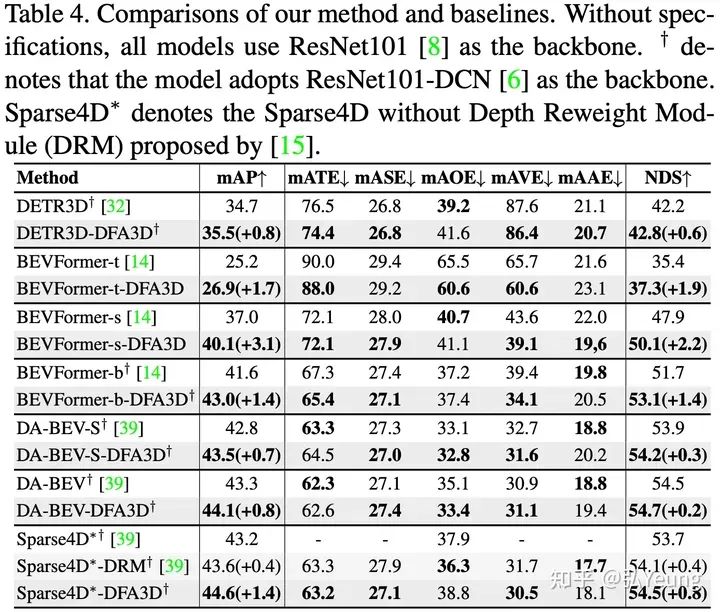
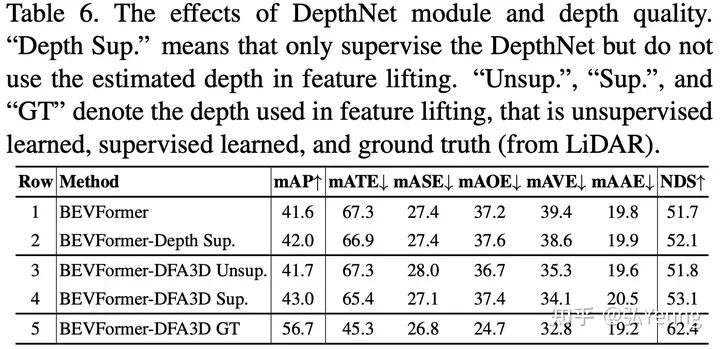
3、实验
4、总结与展望
若觉得还不错的话,请点个 “赞” 或 “在看” 吧
全栈指导班
报名请扫描下方二维码,备注:“全栈班报名”

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢