
对于不同的数据科学家,特征工程可能呈现不同的意义。对于一些数据科学家,特征工程是我们如何缩减用于监督模型的特征(例如,试图预测响应或结果变量)。
对于其他人,它是从非结构化数据中提取数值表示以供无监督模型使用的方法(例如,试图从之前非结构化的数据集中提取结构)。特征工程包括这两种情况,以及更多内容。
数据从业者通常依赖ML和深度学习算法,即使所使用的数据格式不良且非最佳。如果我们不构建适当的特征,依赖复杂而耗时的ML模型来解决问题,我们可能会得到糟糕的ML模型。如果我们花时间了解我们的数据,并为我们的ML模型构建特征,使其能够学习,那么我们最终可以得到更小、更快的模型,其性能可以与甚至优于复杂的模型相媲美。
特征工程并不是解决所有问题的灵丹妙药。例如,在数据量过小的情况下,特征工程无法解决机器学习模型面临的数据不足问题。对于包含少于1000行数据的数据集,在特征工程方面的努力有限,很难从这些数据观察中提取更多信息。
特征工程也不能在特征和响应之间创建本来不存在的联系。如果最初的特征在隐含上对于响应变量没有任何预测能力,那么再多的特征工程也无法创造这种联系。可以在性能上取得一些小幅度的提升,但不能指望特征工程或机器学习模型能够奇迹般地在特征和响应之间创造关系。
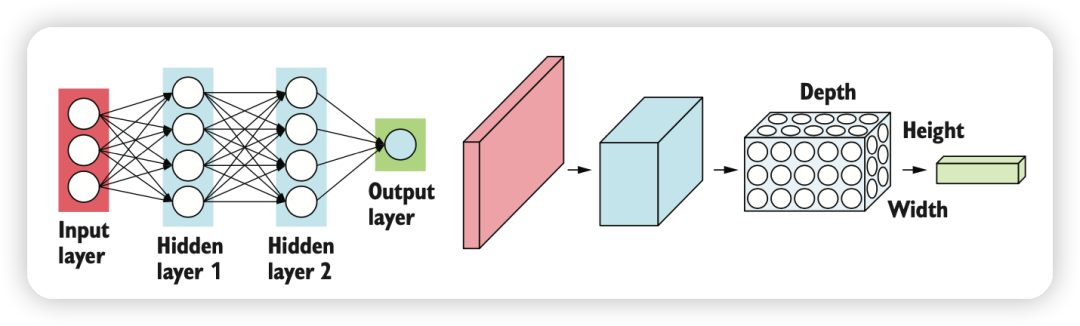
特征工程是指将原始数据转化为机器学习模型能够理解的数据表示的过程,它是整个ML流水线的关键一环。以下是文本中提到的主要概念和步骤:
机器学习流水线的五个步骤:
定义问题领域(Defining the problem domain): 这一步骤涉及明确我们想要通过机器学习解决的问题,同时考虑模型预测速度或可解释性等特点。这些考虑将在模型评估阶段起到关键作用。 获取准确代表问题的数据(Obtaining data): 考虑并实施数据收集方法,确保数据收集公平、安全,并尊重数据提供者的隐私。此时还可以进行探索性数据分析(EDA),以更好地了解正在处理的数据。 特征工程(Feature engineering): 这是文本中重点介绍的部分。特征工程涵盖了将数据转化为适合输入机器学习模型的最佳表示的所有工作。 模型选择和训练(Model selection and training): 在这个阶段,选择适合数据和问题的模型,并进行仔细的训练。如果在第一步中强调模型的可解释性,可能会选择基于树的模型而不是深度学习模型。 模型部署和评估(Model deployment and evaluation): 在这个阶段,数据准备就绪,模型已经训练完毕,可以将模型投入生产。同时需要考虑模型版本控制和预测速度等因素。必须部署评估过程,以跟踪模型随时间的性能变化,并注意模型的衰退情况。
概念漂移和数据漂移:
概念漂移(Concept Drift): 这是指随着时间推移,特征或响应的统计特性发生变化。模型训练时的数据代表了某个时间点的快照,随着时间的推移,数据所代表的环境可能会发生变化,导致我们对特征和响应的认识也发生变化。这可能需要更新模型以适应新的概念。 数据漂移(Data Drift): 这是指数据的基础分布因某种原因发生了变化,但我们对特征的解释保持不变。例如,在全球大流行病爆发后,人们的观影习惯发生了变化,观影时间的分布可能会发生显著变化。这需要我们调整模型以适应新的数据分布。
特征工程细分的步骤:
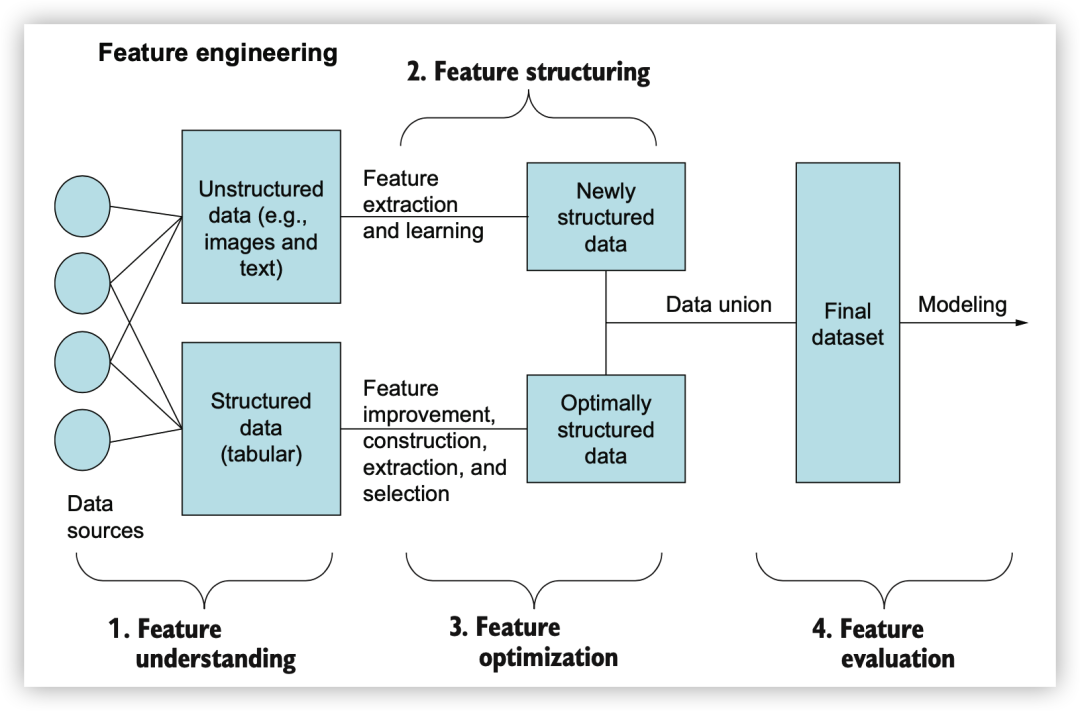
特征理解(Feature understanding): 理解正在处理的数据的层级结构对选择适当的特征工程方法至关重要。 特征结构化(Feature structuring): 如果数据是非结构化的(如文本、图像、视频等),需要将其转换为结构化格式,以便机器学习模型能够理解。这可能需要应用特征提取或学习方法。 特征优化(Feature optimization): 一旦数据被结构化,可以应用优化技术,如特征改进、提取、构建和选择,以获得最适合模型的数据表示。 特征评估(Feature evaluation): 在尝试不同特征工程方案时,可以选择一个学习算法和一些参数选项进行快速调整,以评估应用不同特征工程技术的效果。
结构化数据是按照严格的数据模型或设计组织起来的,通常以表格(行/列)格式表示,其中行代表个体观察,列代表特征。

而非结构化数据则没有预定义的设计,不遵循特定的数据模型,例如客户服务对话的转录、YouTube 视频、播客音频等。
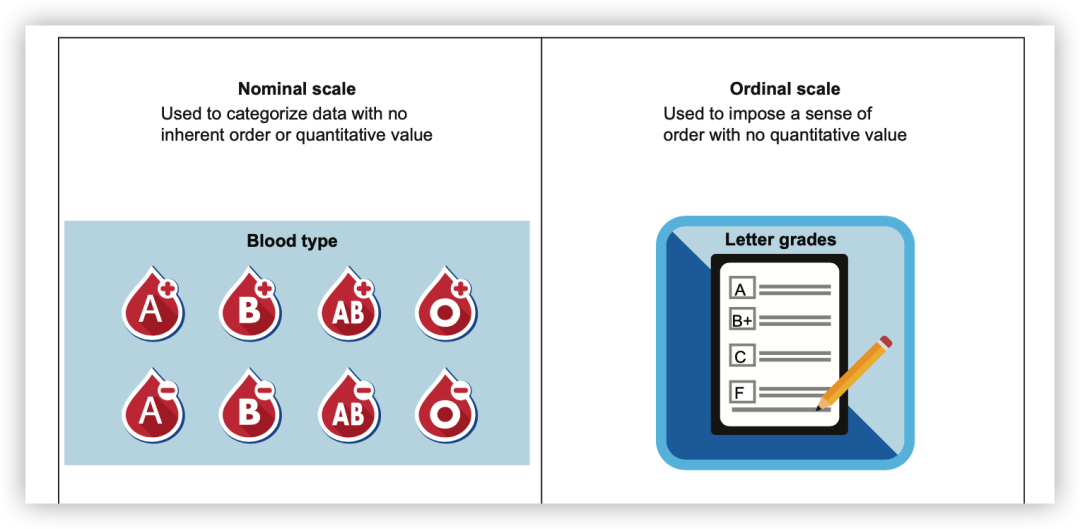
名义级别、序数级别、间隔级别和比例级别。名义级别是纯粹的定性数据,没有顺序和数值含义。序数级别在定性数据中具有一定的顺序,但值之间的差异没有实际意义。间隔级别中,数据之间的差异有一致的意义,可以进行加法和减法操作。比例级别是最高级别,除了有一致的差异意义外,还存在真正的零点,允许进行乘法和除法操作。
特征工程是指在机器学习流程中对原始数据进行预处理和转换,以便更好地适应模型的需求,提高模型的性能和效果。

特征改进(Feature Improvement): 特征改进技术通过各种数学转换来增强现有的结构化特征。通常是对数值特征应用转换,如填充缺失数据、标准化和归一化。这可以包括应用z-score转换、使用统计中位数来填充缺失值等。特征改进在早期的案例研究中扮演着重要角色。它适用于不同层级的数据,根据数据的层级可以选择不同的改进方式。 特征构建(Feature Construction): 特征构建是通过直接转换现有特征或将原始数据与新数据源的数据进行连接,从而手动创建新特征的过程。这可以包括从新数据源中提取信息,创建新的特征。例如,从住房数据集中提取户主总收入以及家庭人数作为新特征。特征构建可以涉及将分类特征转换为数值特征,或者将数值特征通过分桶转换为分类特征。 特征选择(Feature Selection): 特征选择涉及从现有特征集中选择最佳特征,以减少模型需要学习的特征数量,同时减少特征之间的依赖关系。这可以防止模型中出现特征之间的混淆,从而提高模型的性能。特征选择适用于处理维度灾难、特征之间存在依赖性以及需要提高模型速度的情况。 特征提取(Feature Extraction): 特征提取是自动生成新特征的过程,基于对数据的潜在形状做出假设。这可以涉及应用线性代数技术来执行主成分分析(PCA)和奇异值分解(SVD)等。在自然语言处理(NLP)案例研究中,可以通过学习词汇并将原始文本转换为词频向量来执行特征提取。 特征学习(Feature Learning): 特征学习类似于特征提取,但不同之处在于它是通过应用非参数(不对原始数据的形状做出假设)的深度学习模型来自动生成一组特征,从而自动发现原始数据的潜在表示。特征学习适用于处理非结构化数据,如文本、图像和视频。但它也可能需要更多的数据,并且生成的特征可能难以解释。
在特征工程中,需要采用多种评估方法来确保模型的质量。以下将介绍几种评估特征工程成果的指标。
与基准相比,机器学习指标可能是最直接的评估方法。这包括在应用特征工程方法之前和之后查看模型性能。具体步骤如下:
在应用任何特征工程之前,获取计划使用的机器学习模型的基准性能。 对数据进行特征工程处理。 从机器学习模型中获取新的性能指标值,并将其与第一步得到的值进行比较。如果性能有所提升,并且超过了数据科学家定义的某个阈值,则表明特征工程取得了成功。
数据科学家和其他模型相关者应该深刻关注管道的可解释性,因为它可能会影响业务和工程决策。可解释性可以定义为我们能够多好地询问我们的模型“为什么”做出了特定的决策,并将该决策与用于做出模型决策的个别特征或特征组联系起来。
为了确保模型不会根据数据中固有的偏见产生预测,必须根据公平性标准来评估模型。这在涉及个人高度影响的领域特别重要,比如金融贷款授予系统、识别算法、欺诈检测和学术表现预测。在同一份2020年的数据科学调查中,超过一半的受访者表示已经实施或计划实施解释性更强(可解释性)的解决方案,而只有38%的受访者表示对公平性和偏见缓解的情况也是如此。
机器学习流程的复杂性、规模和速度通常是一个被忽视的方面,但有时可能决定部署的成败。正如之前提到的,有时数据科学家会转向大型学习算法,例如神经网络或集成模型,而不是进行适当的特征工程,希望模型能够自己解决问题。
在结构化数据上进行特征工程是提高模型性能和泛化能力的关键步骤,在结构化数据上进行特征工程的步骤:
查看字段类型、确定字段的噪音和分布:
分析数据集中的每个字段,了解字段的数据类型(数值、分类、文本等)。 统计每个字段的缺失值数量和比例,决定是否需要处理缺失值。 绘制字段的分布图、箱线图等可视化工具,检查是否存在异常值或噪音。 了解每个分类特征的唯一值数量,以及数值特征的统计摘要信息。 计算字段与标签的相关性:
使用相关系数、互信息等方法计算每个特征与标签之间的相关性。 可以通过绘制热力图等方式可视化特征与标签之间的关系,识别出与标签强相关的特征。 对字段进行编码,找到新特征:
对分类特征进行编码,例如使用独热编码(One-Hot Encoding)、标签编码(Label Encoding)等。 对数值特征进行归一化(Normalization)或标准化(Standardization),确保特征处于相似的尺度范围内。 根据领域知识或特征与标签的相关性,创建新的特征。例如,从日期中提取年、月、日作为新的时间特征。 使用聚类、降维(如主成分分析 PCA)、多项式特征生成等技术,衍生出更高层次的特征表示。
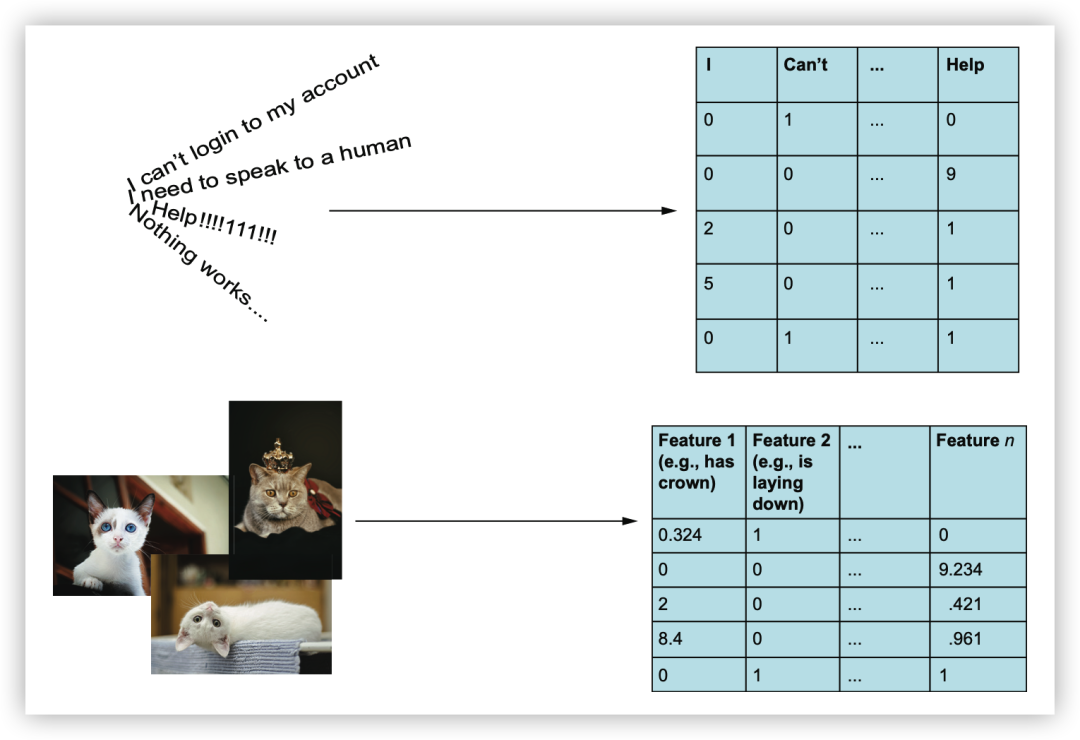
将原始文本数据转化为可供机器学习算法使用的特征,有多种方式:
文本向量化:对于定量特征,可以考虑使用诸如TF-IDF(词频-逆文档频率)等技术将文本数据转化为数值特征。TF-IDF可以将文本中的每个词转化为一个数值,表示该词在文本中的重要性。
清洗和分词:对原始文本进行清洗,去除特殊字符、标点符号和无关信息。然后,将清洗后的文本进行分词,将文本划分为词语或标记。可以使用各种文本处理库(如NLTK、spaCy)来实现。
特征提取:在深度学习方面,可以使用词嵌入技术(如Word2Vec、GloVe)来将每个词转化为具有语义信息的向量表示。
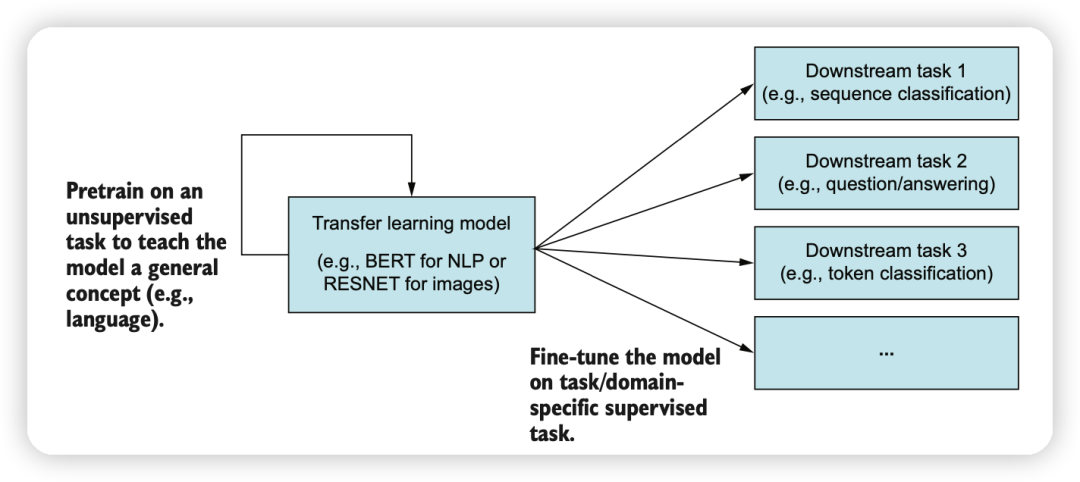
迁移学习:使用预训练的大型模型(如BERT、T5、ChatGPT等)来进行迁移学习。这些模型在大规模文本数据上进行了预训练,可以捕捉丰富的语义信息。
深度学习模型特别是卷积神经网络(CNN),已经在图像处理领域取得了显著的成功。可以使用预训练的深度学习模型(如VGG、ResNet、Inception等)作为特征提取器,通过去掉最后的分类层,将模型用作特征提取器。然后可以对这些提取的特征进行降维(如PCA或t-SNE)或直接用于机器学习模型。
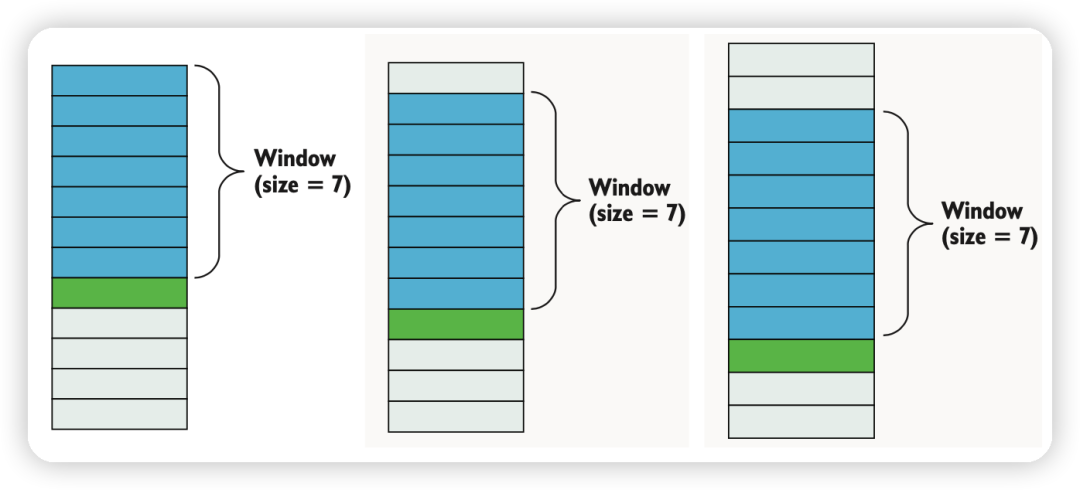
1. 理解时序数据: 首先需要理解你的时序数据的特点。了解时间戳、观测频率、时间间隔等信息。
2. 构建自定义特征集和响应变量: 根据问题的需求,你可能需要构建自定义的特征集和响应变量。这可能包括计算滚动统计量(如移动平均、滚动标准差)、创建时间窗口特征、构建滞后特征等。
3. 使用标准时序特征类型: 在时序数据中,有一些常见的特征类型,如趋势、季节性、周期性等。你可以尝试提取这些特征,并将它们作为模型的输入。
4. 添加领域特定的特征: 在一些情况下,你可能有领域特定的知识,可以用于构建有用的特征。例如,在股票市场数据中,你可以添加技术指标(如移动平均线、相对强弱指标等)作为特征。
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢