
作者:Anian Ruoss, Grégoire Delétang, Tim Genewein, Jordi Grau-Moya, Róbert Csordás, Mehdi Bennani, Shane Legg, Joel Veness 机构:DeepMind, The Swiss AI Lab, IDSIA, USI & SUPSI 题目:Randomized Positional Encodings Boost Length Generalization of Transformers 发表日期:2023年5月26日 论文链接:https://aclanthology.org/2023.acl-short.161.pdf 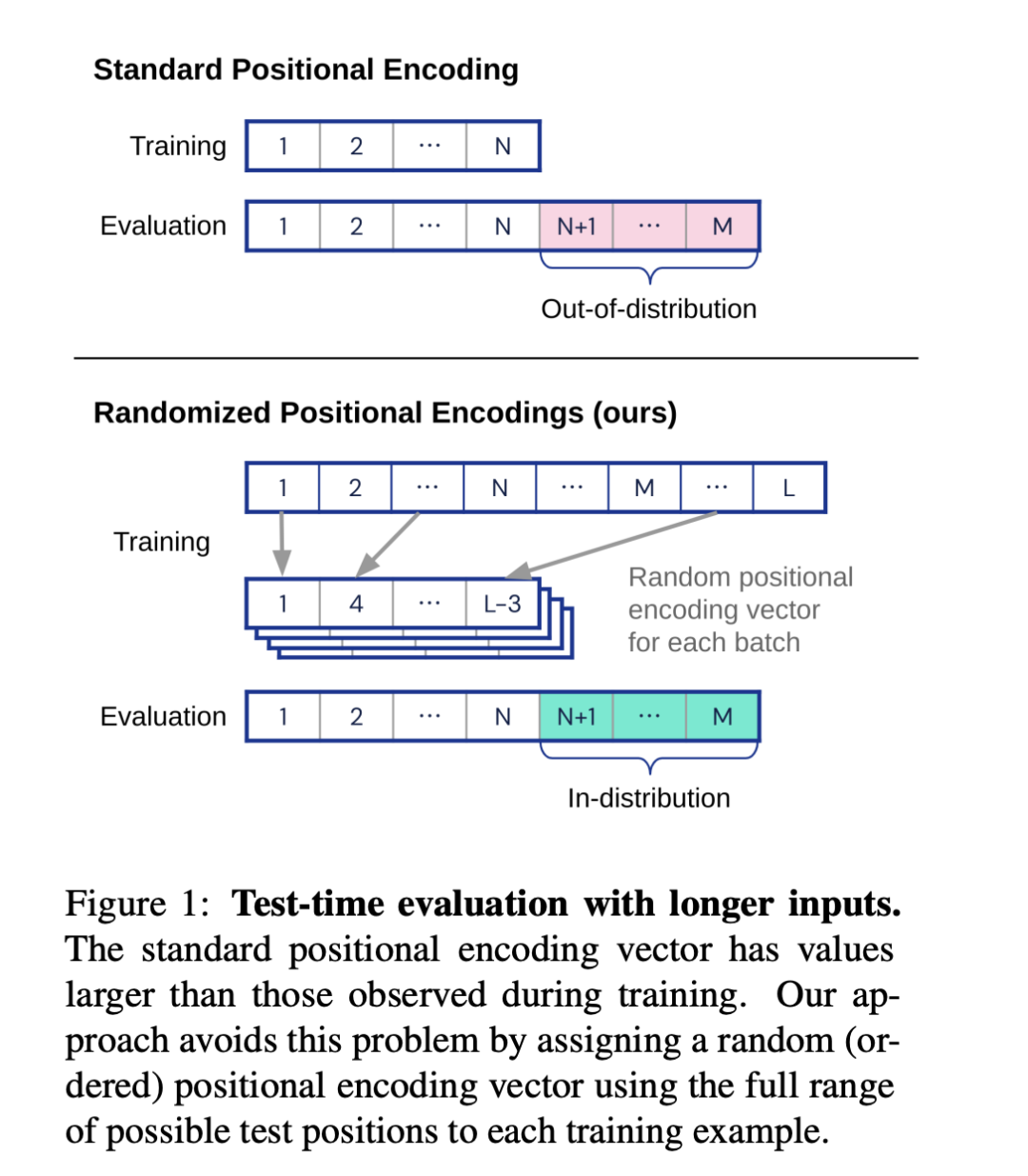
2. 主要内容
Transformers在固定上下文长度的任务上具有很好的泛化能力。然而,它们无法泛化到任意长度的序列,比如很简单的任务,如复制字符串。此外,由于全局注意力机制的计算复杂性,简单地在更长的序列上进行训练是十分低效的。
在这项工作中,作者证明这种失败模式与位置编码对于更长序列的分布(即使对于相对编码)是相关的,为此作者引入一种新的位置编码家族,可以克服这个问题。具体来说,作者提出了随机位置编码方案模拟了更长序列的位置,并随机选择一个有序子集来适应序列的长度。
作者对15种算法推理任务的6000个模型进行了大规模的实证评估,结果显示本文的方法使Transformers能够泛化到未见过的序列长度(平均测试精度提高了12.0%)。
作者提出的随机位置编码方案主要依赖于序列中元素的顺序信息,而不是具体的位置信息。在每次训练步骤中,首先随机选择一个长度n,然后从长度为L的序列中随机选择n个位置索引,将这些索引排序后得到一个有序集合I。然后,对于序列中的每个元素,都使用对应的位置索引来计算其随机位置编码。这种方法的关键在于,虽然每个元素的位置编码在训练过程中会发生变化,但由于保持了编码的顺序,因此Transformer仍然可以从子采样的编码中提取出相关的位置信息。
在测试阶段,当处理长度大于N的序列时,使用相同的过程,但对所有位置1<=j<=M进行处理。这种方法的主要限制是,必须提前知道测试序列的最大长度M,以便选择L<=M。然而,这种方法可以兼容一系列的L值,而且这比简单地在更长的序列上进行训练所需要的假设要弱得多。
具体的位置编码计算如下:
其中,pos是序列中元素的位置,d_model是输入嵌入的维度,i是{1,2, . . . , d_model/2}。
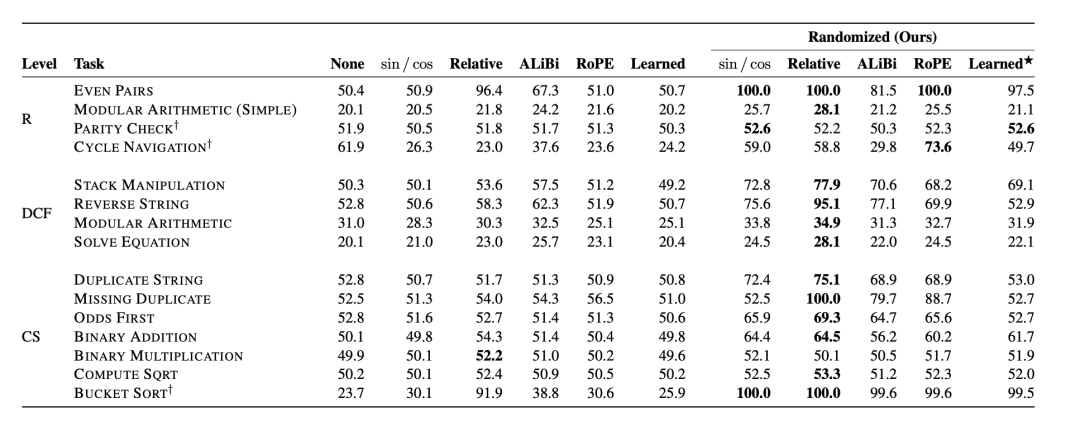
作者对15种算法推理任务的6000个模型进行了大规模的实证评估。结果显示,使用随机位置编码的Transformer在未见过的序列长度上的测试精度平均提高了12.0%。在某些任务上,如反转字符串或找出重复项,随机位置编码的Transformer甚至解决了之前的方法无法解决的问题。
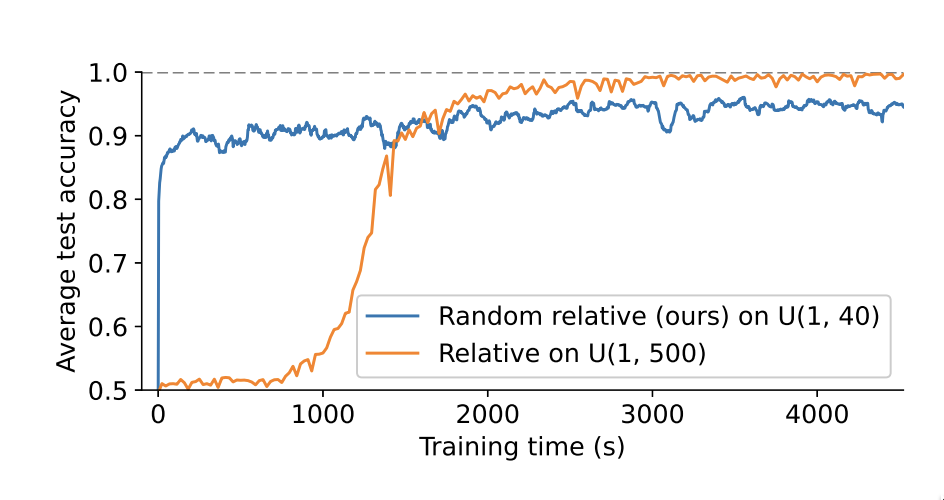
此外,作者还发现,使用随机位置编码的Transformer在短序列上的训练效率显著提高。具体来说,使用随机位置编码的Transformer在训练过程中,每秒可以进行168.4步的训练,而直接在长序列上训练的Transformer每秒只能进行22.1步的训练。这是因为全局注意力的运行时间与序列长度的平方成正比,因此在短序列上训练的Transformer的训练速度更快。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢