协作多智能体强化学习(Multi-agent Reinforcement Learning, 简称 MARL)方法是实现群体智能的重要手段,已成为人工智能重要研究方向。其在交互式、复杂的合作多智能体环境中表现出了显著的性能,例如多机器人控制、路径规划、智慧电网和多人游戏等。MARL 算法通常将合作多智能体学习系统建模为马尔可夫博弈(或随机博弈)。其中,每个智能体根据自身对于环境的观测以及其当前策略采取行动,这些行动共同决定了环境的后续状态变化,以及每个智能体接收到的奖励。现有的 MARL 算法主要遵循中心化训练分布式执行(CTDE)学习范式。CTDE 假设一个强大的中央控制器可以接收和处理所有智能体的信息,包括所有智能体的观测、策略和奖励,从而有效地解决了多智能体强化学习中的非平稳性问题。然而,CTDE 存在一些局限性。首先,随着智能体数量的增加,中央控制器需要处理的信息量将呈指数级增加,最终导致维度灾难,这将给整个系统带来巨大的时空开销。其次,训练的中心化假设在许多现实世界的场景中是不现实的。此外,中央控制器的存在还降低了系统抵抗恶意攻击的能力。总而言之,传统中心化多智能体强化学习方法,在处理智能体间非交互性以及维度灾难等问题时具有局限性,且通常需要在智能体间传输大量信息才能处理完全协作任务。如何设计一种灵活的完全去中心化多智能体强化学习算法框架是一个重要难题。本文介绍一种最优化驱动的基于原始-对偶混合梯度下降方法的完全去中心化 MARL 算法框架 F2A2(如图1所示),有效实现了智能体的独立学习和分布式控制。值得注意的是,该框架联合优化策略改进和价值评估两个子问题,从而增强多智能体的策略学习过程的稳健性,并在大规模场景下具备良好的扩展性,同时采用了基于心智理论的新颖智能体建模方法,在星际II等多个通用多智能体强化学习任务下表现出卓越性能。
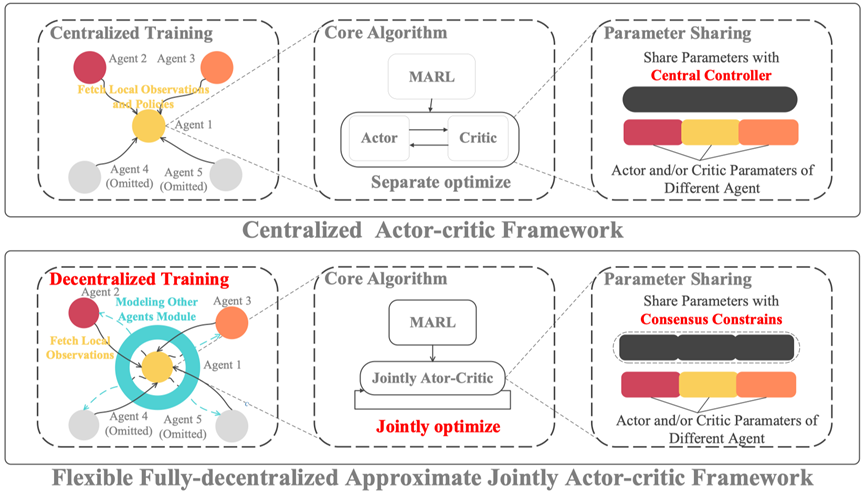
图 1 F2A2 完全去中心化多智能体强化学习算法框架
Part 1
马尔可夫决策过程与强化学习基础
序列决策(Sequence Decision)指的是在一个序列的时间步骤中,根据当前状态和之前的决策历史,做出一系列决策以达到某个目标。每一步决策都会影响后续的状态和可选的决策,因此需要综合考虑整个序列的决策才能得到最优解。马尔可夫决策过程(Markov Decision Process,简称 MDP)是一种典型面向序列决策的数学模型,其包含一个状态空间、一个动作空间、一个状态转移概率矩阵、一个奖励函数和一个折扣因子。在每个时间步骤中,智能体会处于一个特定的状态,然后选择一个动作来影响下一个状态和获得的奖励。状态转移概率矩阵描述了从一个状态转移到另一个状态的概率,奖励函数则表示在每个状态下采取不同动作所获得的奖励,具体状态转移过程可见下图 2。折扣因子用于平衡当前奖励和未来奖励的重要性。MDP 的目标是找到一个策略,使得智能体在长期内获得最大的期望奖励。
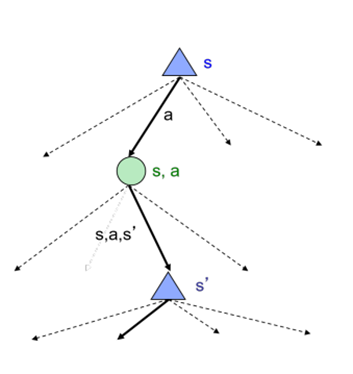
图 2 马尔可夫决策过程状态转移
马尔可夫决策过程重点关注对上图 2 中节点的评价,因此可以定义出关键最优价值函数:为每个状态的价值函数;为每个状态选择动作对应的价值函数。马尔可夫决策过程旨在建立状态空间与动作空间的映射,即学习最优策略。最优价值函数与最优策略之间可以基于状态转移建立Bellman方程,即:马尔可夫决策过程的典型求解方法为动态规划,包括价值迭代方法、策略迭代方法等,这些方法都可以看作为以Bellman方程为基础的不动点迭代方法。
强化学习(Reinforcement Learning,简称 RL)是一种机器学习方法,它关注如何通过智能体与环境的交互来学习如何做出最优的决策。在强化学习中,智能体通过试错的方式进行学习,不断尝试不同的行动,并根据环境的反馈来调整自己的决策策略,以获得最大的奖励。强化学习中的环境通常被建模为马尔可夫决策过程(MDP),智能体则通过学习 MDP 中的最优策略来实现最大化奖励的目标,其基本框架见下图3。强化学习与马尔可夫决策过程的核心区别是没有已知的状态转移函数,学习过程中需要通过对动作和状态的不断尝试来近似马尔可夫决策过程中的状态转移过程。强化学习被广泛应用于机器人控制、游戏AI、推荐系统、自然语言处理等领域。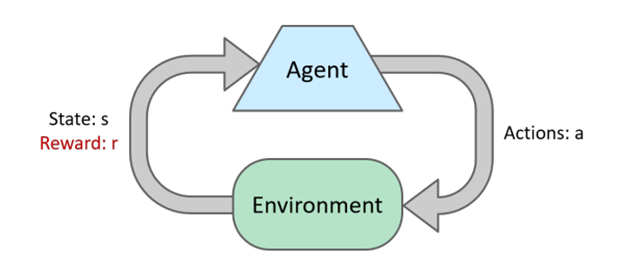
图 3 强化学习基本框架
Actor-Critic方法是一种常用的强化学习方法,它将强化学习中的策略评估和策略改进分别交给两个不同的模型来完成,其中Actor模型负责生成策略,Critic模型负责评估策略的好坏并提供反馈,以便Actor模型进行改进。具体来说,Actor-Critic方法中的Actor模型是一个决策策略模型,它通过学习最大化长期奖励的策略来指导智能体的行动。Critic模型则是一个价值函数模型,它评估Actor模型生成的策略在当前状态下的好坏,并提供反馈,以便Actor模型进行改进。在Actor-Critic方法中,Actor模型和Critic模型可以是任何类型的模型,比如神经网络模型。在训练过程中,Actor模型根据当前状态生成一个行动,然后将该行动提交给环境。环境返回一个奖励信号和下一个状态。Critic模型根据当前状态和奖励信号评估Actor模型生成的策略,并计算出一个价值函数,用来指导Actor模型的改进。Actor模型根据Critic模型提供的价值函数来更新自己的策略,以便更好地最大化奖励。Actor-Critic方法可以有效地解决强化学习中的信用分配问题,即如何将奖励信号分配给产生该奖励的行动和状态。Actor-Critic方法通过最小化累积期望折扣代价(可以看作为负奖励)来直接优化Actor策略,即其中表示策略函数的参数,表示初始状态的分布。进一步结合Critic价值函数,可以建立基于双层规划(bi-level programming)的Actor-Critic算法模型。近期单智能体强化学习一些理论工作表明,从双层规划视角建模 Actor-Critic 算法能够进行更有效的收敛性以及样本复杂度的分析。具体来说,基于双层规划的 Actor-Critic算法具有以下形式:
传统Actor-Critic算法通常交替优化上述双层规划问题的上层目标和下层目标函数,即这类方法也可以理解为一种块坐标下降类方法驱动的Actor-Critic强化学习算法。Part 2
协作多智能体强化学习建模
以马尔可夫决策过程为基础,给出协作局部观测随机博弈的定义,其可以表示为如下元组:具体来说,针对上述协作部分观测随机博弈问题,同样可以从双层优化视角将其建模为如下优化问题:将约束转化为罚函数后,上式可以转化为下列无约束优化问题:上述优化目标中同时包含了策略评价和价值改进两个子问题,分别对应于演员(actor)以及评论家(critic)的参数更新。为了从演员-评论家框架角度更清晰的表示上述无约束优化问题,论文引入以下记号:如此一来,我们就可以将上述无约束优化问题,或者说协作部分观测随机博弈问题,从多智能体强化学习以及双层优化的视角,表示为以下一般性的优化问题:其中,表示一个可选的正则项,以防止过拟合或实现稀疏性等。在所提出 F2A2 框架中,我们假设它具有可分结构。近期一些研究工作表明,参数正则技术对单智能体强化学习算法的性能有显著影响。多智能体强化学习算法的规模通常比单一智能体模型的规模要大得多。因此,正则化的影响不应被忽略。为了使所提出的框架具有更好的泛化性能,通常需要将正则化项添加到多智能体Actor-Critic的目标函数中。Part 3
F2A2 算法框架
在解决一般协作部分观测随机博弈问题时,为了学习分布式策略同时实现全局协作,现有工作主要使用以下三类技术:
(1)基于共识,建立关于其他智能体动作或局部观测的共识,利用共享的共识生成器实现全局协作;
(2)基于显式通信,通过在决策阶段交换信息达成一定共识。但所交换的信息必须能被所有智能体理解,因此消息生成模块也需要在智能体之间共享;
(3)隐式通信算法,直接在智能体之间共享动作和/或局部观测。与此同时,类似于显式通信,每个智能体处理这些全局信息的模型也必须保持对环境的相同理解,以实现全局协作。
为了使得上述一般性的优化问题能够兼容这些分布式框架,F2A2 需要考虑到这些方法中的核心模块可以被所有智能体共同访问,因此需要将灵活的参数共享机制引入到所提框架中。此外,参数共享机制还可用于实现更好可扩展性。近期的研究也表明,参数共享在提高算法合作性能方面发挥着关键作用。为了实现参数共享机制与一般性优化问题的有机融合,论文将上述一般性优化问题的参数划分为共享部分和非共享部分:
其中
为了分布式、完全去中心化地求解上述问题,并实现演员(策略改进)和评论家(价值评估)的联合优化,F2A2 将其转化为如下具有一致性约束的优化问题:接着使用原始-对偶混合梯度框架(或非精确交替方向乘子法)将其转化为以下无约束优化问题,便于后续的求解:论文证明了在遵循以下参数更新规则时,算法可以收敛到稳定点,且演员以及评论家可以使用深度神经网络进行参数化:现有的去中心化强化学习工作假设每个智能体都能访问到其他智能体的策略。然而,这样的假设过于严格,更现实的假设是智能体必须根据历史观测来建模其他智能体的策略。为了使所提出的框架更适用于这种更一般的假设,我们在算法框架中进行了进一步改进。另一个重要问题是,建模的策略和预测的动作由于存在误差,可能导致算法中梯度的失真。然而,在本工作中,我们发现带有噪声的梯度可能有助于优化算法收敛到全局最优解,这一结论同样也受到一些前期工作的支撑。尽管估计的策略可能带来偏差,但它可以降低算法的方差,进一步提高系统的稳健性。这将在后面的实验中得到验证。具体而言,受到目前在强化学习领域受到广泛认可的机器心智理论启发,F2A2 提出了一个新颖的、基于心智理论的智能体建模方法,如图4所示。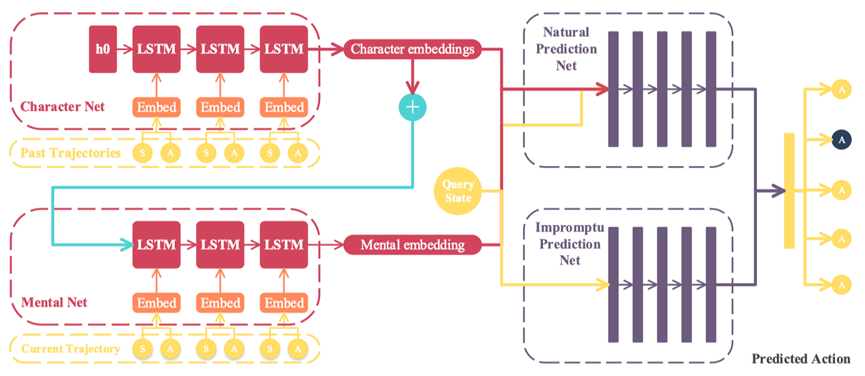
图 4 基于心智理论的智能体建模框架
具体来说,首先,每个智能体在训练前在环境中随机采样固定数量的轨迹,并使用长短期记忆网络 LSTM 对每个轨迹进行编码。然后,将所有轨迹编码的平均值作为智能体的“特性”。训练开始后,对于每个当前未完成的轨迹,F2A2 引入另一个 LSTM 用于将其历史片段编码为智能体的当前“心智”。一方面,智能体的当前状态、特性和当前心智一起作为“自然预测网络”的输入;另一方面,F2A2 引入“即兴预测网络”,仅依赖当前状态来预测其他智能体的动作。这两个网络的输出被结合起来产生最终的预测。整个网络的训练过程与多智能体强化学习算法一起执行,并且训练数据会定期重新收集。最终,整个 F2A2 框架的训练流程如图5所示。
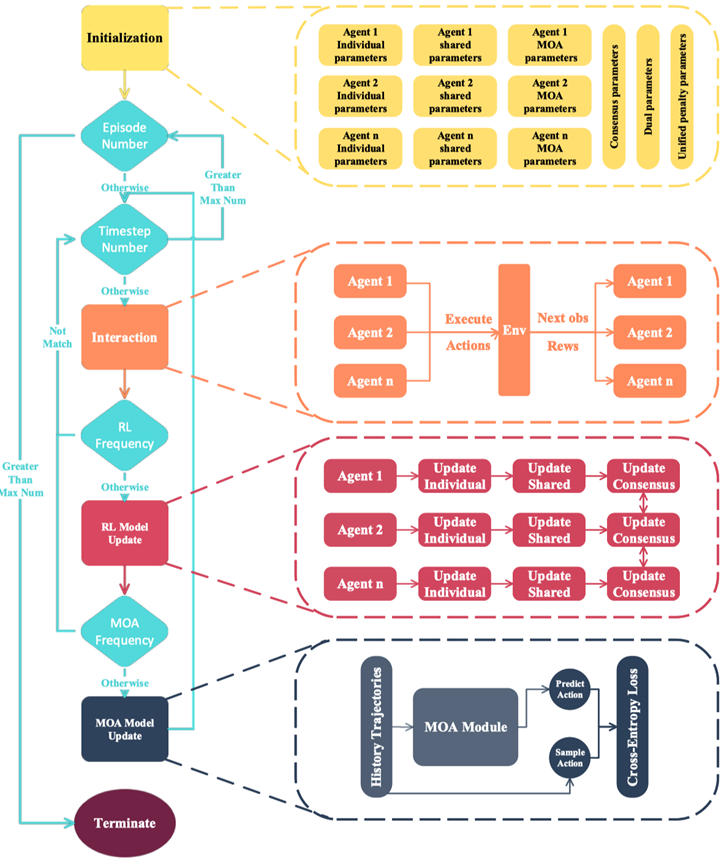
图 5 F2A2 完全去中心化框架
Part 4
部分实验结果
F2A2 完全去中心化框架可以与多种Actor-Critic类型强化学习方法相结合,引导出一系列去中心化训练去中心化执行版本的强化学习方法,比如 F2A2-DDPG、F2A2-SAC、F2A2-COMA、F2A2-TD3等。我们也在星际II实验中验证了一系列 F2A2 完全去中心化框架赋能改造的去中心化多智能体强化学习方法。
星际II实验考虑两组相同单位在地图上对称放置的战斗场景。第一组(盟友)单位由一系列F2A2算法控制;敌方单位由内置的StarCraft II AI控制,后者使用人工设计的启发式规则。各组单位的初始位置通过随机初始化确定。控制敌方单位的电脑AI的难度设定为中等。我们在一组不同难度的地图上进行了数值实验,并与基准算法进行对比。对于不同地图,每组单位分别由3名士兵(3m)、8名士兵(8m)和2名潜行者及3名狂热者(2s3z)组成。智能体的动作空间由离散动作组成:move[direction]、attack[enemy id]、stop 和 noop。智能体只能向四个方向移动:北、南、东或西。只有当敌人在射程内时,单位才允许执行attack[enemy id]操作。此外,智能体只能在其他单位处于活跃状态时观察到它们,并无法区分死亡或超出范围的单位。在每个时间步,智能体收到的奖励等于对敌方单位造成的总伤害。此外,在击败每个对手后,智能体会获得10点奖励,在击败所有对手后获得200点奖励。所有奖励均按比例分配,以确保在一次任务中获得的最大累积奖励为20。
图6(a)、6(b)和6(c)分别绘制了F2A2系列算法在三个StarCraft II地图中相对于其中心化基准版本的胜率。从图中可以看出,即使StarCraft II环境较为复杂,F2A2框架的实例化算法仍然可以达到或超过其相应的中心化基准算法的性能,这证明了F2A2框架的鲁棒性与有效性。
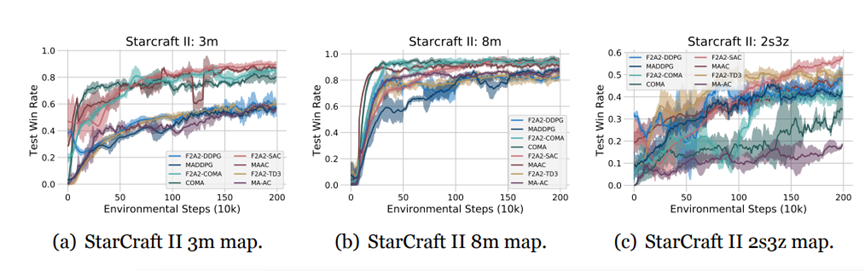
图 6 星际II实验结果
此外,为了验证PDHG(主对偶混合梯度)型方法的优越性,我们在星际 II环境中选择了相应的最优算法并进行了比较实验。从图7可以看出,PDHG型联合优化方法(*-with-JOINT)与BCGD(块坐标梯度下降)型可分优化方法(*-w/o-JOINT)相比,性能得到了显著提升。
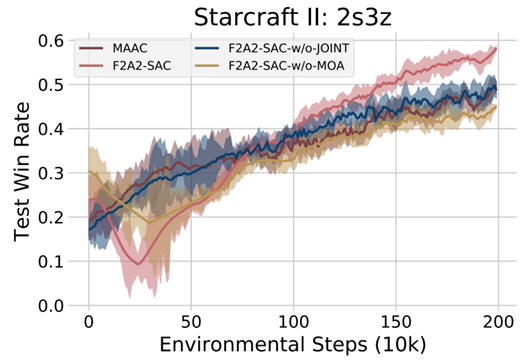
图 7 PDHG 算法与 BCGD 算法性能对比
在前面的内容中,我们认为通过引入噪声,心智(MOA)模块可以防止智能体过度拟合其他智能体的次优策略,并增加探索强度,从而最终提高算法性能。此外,在某些情况下,它还可以超过中心化算法的效果。为了定量衡量MOA模块的效果,我们同样进行了比较实验,图7中展示的实验结果也支持了上述结论。
Part 5
结论
为了在交互式多智能体环境中实现适用性和可扩展性,本文给出了一个灵活的、完全分散的近似Actor-Critic多智能体强化学习框架,设计了原始-对偶优化和联合行动者-批评者学习,以保证充分的去中心化和可扩展性,并引入基于心智理论的智能体建模方法来增加算法的健壮性。在不同类别、不同规模的仿真协同环境中,该方法甚至可以超过中心化基准算法。未来,我们计划在训练过程中引入通信,以促进更高效的合作,以更好地适应复杂场景。
详见下文:
Wenhao Li, Bo Jin, Xiangfeng Wang, Junchi Yan and Hongyuan Zha, F2A2: Flexible Fully-decentralized Approximate Actor-critic for Cooperative Multi-agent Reinforcement Learning, Journal of Machine Learning Research, 2023.
供稿:李文浩、金博、王祥丰、严骏驰、查宏远
排版:柚子美编十二号(西安交通大学金融优化组萧潇)
如需转载请联系公众号
加群:加入全球华人OR|AI|DS社区硕博微信学术群
资料:免费获得大量运筹学相关学习资料
人才库:加入运筹精英人才库,获得独家职位推荐
电子书:免费获取平台小编独家创作的优化理论、运筹实践和数据科学电子书,持续更新中ing...
加入我们:加入「运筹OR帷幄」,参与内容创作平台运营
知识星球:加入「运筹OR帷幄」数据算法社区,免费参与每周「领读计划」、「行业inTalk」、「OR会客厅」等直播活动,与数百位签约大V进行在线交流
文章须知
文章作者:李文浩,金博等
责任编辑:Road Rash
微信编辑:疑疑
文章由『运筹OR帷幄』转载发布
如需转载请在公众号后台获取转载须知



内容中包含的图片若涉及版权问题,请及时与我们联系删除






评论
沙发等你来抢