
本次京东城市带来的技术分享是,JUST(https://just.urban-computing.cn/)是如何使用ClickHouse实现时序数据管理和挖掘的。ClickHouse是一个高效的开源联机分析列式数据库管理系统,由俄罗斯IT公司Yandex开发的,并于2016年6月宣布开源。
CK原理介绍
要利用CK的优势,首先得知道它有哪些优势,然后理解其核心原理。根据我们的测试结果,对于27个字段的表,单个实例每秒写入速度接近200MB,超过400万条数据/s。因为数据是随机生成的,对压缩并不友好。 而对于查询,在能够利用索引的情况下,不同量级下(百万、千万、亿级)都能在毫秒级返回。对于极限情况:对多个没有索引的字段做聚合查询,也就是全表扫描时,也能达到400万条/s的聚合速度。 3.1 CK为什么快
可以归结为选择和细节,选择决定方向,细节决定成败。 CK选择最优的算法,比如列式压缩的LZ4[6];选择着眼硬件,充分利用CPU和分级缓存;针对不同场景不同处理,比如SIMD应用于文本和数据过滤;CK的持续迭代非常快,不仅可以迅速修复bug,也能很快纳入新的优秀算法。 3.2 CK基础
(1)CK是一个纯列式存储的数据库,一个列就是硬盘上的一个或多个文件(多个分区有多个文件),关于列式存储这里就不展开了,总之列存对于分析来讲好处更大,因为每个列单独存储,所以每一列数据可以压缩,不仅节省了硬盘,还可以降低磁盘IO。 (2)CK是多核并行处理的,为了充分利用CPU资源,多线程和多核必不可少,同时向量化执行也会大幅提高速度。 (3)提供SQL查询接口,CK的客户端连接方式分为HTTP和TCP,TCP更加底层和高效,HTTP更容易使用和扩展,一般来说HTTP足矣,社区已经有很多各种语言的连接客户端。 (4)CK不支持事务,大数据场景下对事务的要求没这么高。 (5)不建议按行更新和删除,CK的删除操作也会转化为增加操作,粒度太低严重影响效率。 3.3 CK集群
生产环境中通常是使用集群部署,CK的集群与Hadoop等集群稍微有些不一样。如图6所示,CK集群共包含以下几个关键概念。
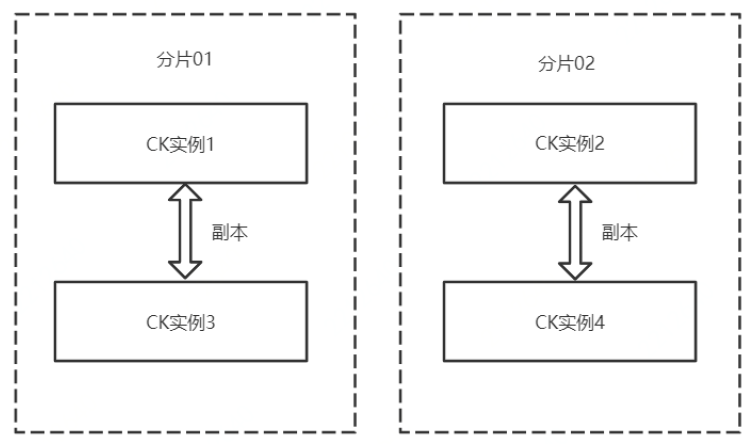 (1)CK实例。可以一台主机上起多个CK实例,端口不同即可,也可以一台主机一个CK实例。
(2)分片。数据的水平划分,例如随机划分时,图5中每个分片各有大约一半数据。
(3)副本。数据的冗余备份,同时也可作为查询节点。多个副本同时提供数据查询服务,能够加快数据的查询效率,提高并发度。图5中CK实例1和示例3存储了相同数据。
(4)多主集群模式。CK的每个实例都可以叫做副本,每个实体都可以提供查询,不区分主从,只是在写入数据时会在每个分片里临时选一个主副本,来提供数据同步服务,具体见下文中的写入过程。
(1)CK实例。可以一台主机上起多个CK实例,端口不同即可,也可以一台主机一个CK实例。
(2)分片。数据的水平划分,例如随机划分时,图5中每个分片各有大约一半数据。
(3)副本。数据的冗余备份,同时也可作为查询节点。多个副本同时提供数据查询服务,能够加快数据的查询效率,提高并发度。图5中CK实例1和示例3存储了相同数据。
(4)多主集群模式。CK的每个实例都可以叫做副本,每个实体都可以提供查询,不区分主从,只是在写入数据时会在每个分片里临时选一个主副本,来提供数据同步服务,具体见下文中的写入过程。
CK与时序的结合
在了解了CK的基本原理后,我们看看其在时序数据方面的处理能力。 (1)时间:时间是必不可少的,按照时间分区能够大幅降低数据扫描范围; (2)过滤:对条件的过滤一般基于某些列,对于列式存储来说优势明显; (3)降采样:对于时序来说非常重要的功能,可以通过聚合实现,CK自带时间各个粒度的时间转换函数以及强大的聚合能力,可以满足要求; (4)分析挖掘:可以开发扩展的函数来支持。 另外CK作为一个大数据系统,也满足以下基础要求: (1)高吞吐写入; (2)海量数据存储:冷热备份,TTL; (3)高效实时的查询; (4)高可用; (5)可扩展性:可以实现自定义开发; (6)易于使用:提供了JDBC和HTTP接口; (7)易于维护:数据迁移方便,恢复容易,后续可能会将依赖的ZK去掉,内置分布式功能。 因此,CK可以很方便的实现一个高性能、高可用的时序数据管理和分析系统。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢