本文介绍了由剑桥大学Alexei Lapkin课题组开发的ORDerly开源Python库,它为开源数据集ORD(Open Reaction Database)提供了化学反应数据的新基准和高度可定制的清洗数据工作流程,为研究有机化学反应相关(尤其是反应条件预测)的人工智能、机器学习问题提供便利[1]。
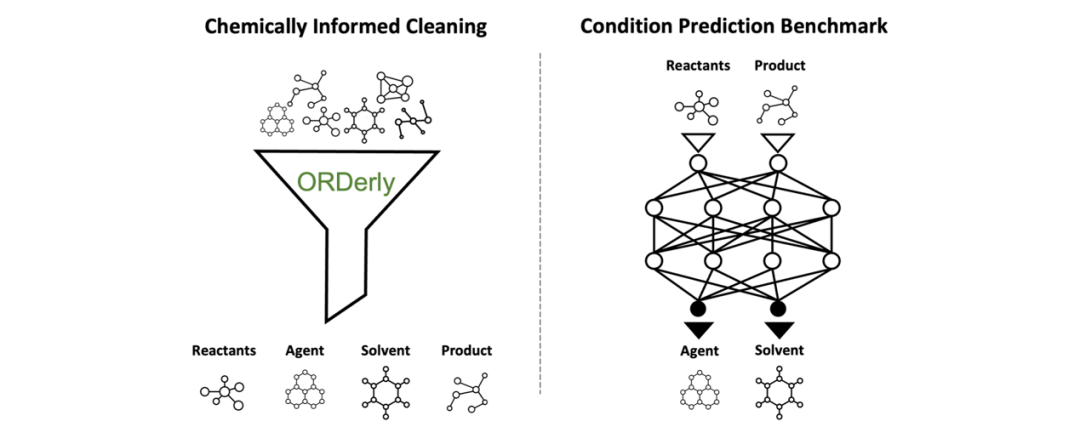
——背景—— 目前最大的开源有机化学反应数据库是由MIT、UCLA、默克、辉瑞等研究者于2019年开始开发的ORD(Open Reaction Database)数据集。该数据集目前包含未清洗的数据有2百万条,其中大部分来源于用自动化算法挖掘的1976-2016年USPTO中的有机反应数据。此外还包含一些已发表的高通量有机反应数据。这些数据包含了反应物、产物、催化剂、溶剂、温度、压力、产量等详细参数。 虽然ORD数据库的数据高度结构化,但是一方面其数据格式无法直接用于相关机器学习任务,另一方面存在不少重复、谬误、罕见的反应数据需要清洗。此前也有MIT的rdchiral[2]以及AstraZeneca[3]的Python脚本用于处理USPTO的csv数据,然而并无法直接处理ORD更复杂的数据。TDC数据集[4]尽管有USPTO数据集的基准,但是缺少反应条件等数据,无法进行条件预测。 因此针对这些问题,研究人员开发了ORDerly库,用来提供一种稳健、灵活、易于访问的方法,将ORD原始数据转化为适用于机器学习的数据。通过化学信息分配反应角色、特定名称解析和可重现的开源基准生成等标准清洗操作,助力于推动AI化学应用的边界。 图1 ORDerly 清洗反应数据并建立反应条件(分子角色)预测的基准 ——方法与结果—— ORDerly采用了两种从ORD中提取分子角色的方法:一种是信任ORD中的数据标签(一般是由自然语言处理算法从原始文本中预测的),后文简称labeling;另一种是利用化学反应逻辑从反应字符串中识别不同分子的角色(例如用原子匹配区分反应物、溶剂、催化剂,利用常用溶剂名单来匹配溶剂分子),后文简称reaction string。前者labeling存在将试剂错标为反应物的情况,导致数据中反应物频次偏多。 作者统计了一条反应中反应物、产物、溶剂、试剂、催化剂的出现次数的频次,确定了保留出现次数的上限,即反应物不超过2个,产物不超过1个,溶剂不超过2个,试剂不超过3个。用labeling方法得到的数据,存在试剂错标为反应物的情况,导致数据中反应物频次偏多,因此清洗后,labeling的数据明显少于reaction string方法。 除了一些常规的反应数据清洗手段,ORDerly讨论了两种处理罕见分子(出现频率小于100次)的方法:一种是删除(delete),将带有罕见分子的反应删除;另一种是将罕见分子标注为“其他(other)”。 1)Dataset A: Labeling, "other" (76,634
reactions)
2)Dataset B: Labeling, delete rxn (75,033 reactions)
3)Dataset C: Reaction string, "other"
(392,996 reactions)
4)Dataset D: Reaction string, delete rxn (356,906
reactions) 作者使用MIT的Connor Coley组2018年的神经网络模型[5],在这四个数据集上进行测试(已知反应物与产物,预测2个溶剂与3个试剂)。Baseline是简单预测训练集中发现的最常见分子(基于频率的预测)。得到的预测结果如表1所示。 表1 Top-3 精确匹配溶剂- 试剂组合的准确度 (%) :基于频率的预测 // 模型预测// AIB (average improvement over baseline )% 其中AIB%公式如下,Am 为模型预测的准确度,Ab 为基线准确度。 从表1可以看出,在所有数据集上,神经网络模型都优于基于频率预测的基线。标签(labeling)数据集的表现优于从反应字符串提取(reaction string)的数据集,这可能是因为labeling数据集中存在溶剂、试剂被标为反应物,降低了预测难度。 此外,ORDerly的测试结果明显差于MIT的Connor
Coley组2018年的工作,很有可能是因为后者数据量达到1000万(Reaxys数据),而前者数据量只有几十万。对此,作者做了数据量对于模型表现的影响的探究,如图2所示。训练数据越多,表现越好,并且delete比“other“表现更好。因此作者把数据集D(reaction string,delete)作为ORDerly的基准(Benchmark)。
图2 不同罕见分子处理方法的数据集,数据集大小对于模型表现的影响。 ——结论—— ORDerly是一个可以将ORD中的化学反应数据清洗并转化为机器学习即用数据集的开源框架。作者发现USPTO数据集中利用NLP算法文本挖掘的反应条件数据,其效果不如从反应式中根据化学逻辑(原子匹配、常用溶剂)重新识别的反应条件数据。并且删除罕见数据的效果比单独保留成“other”效果更好 。 ——笔者小结—— 笔者认为,ORDerly的出发点是具有积极意义的,因为ORD作为集成了开源有机反应数据的数据库,需要合理高效的数据处理工作流程以及基准。然而,笔者认为相关工作还有值得改进的地方: 1)改进划分数据集的方法:本文用的是随机划分,然而同一种反应的反应条件往往是相似的,因此笔者认为可以根据反应类型(或反应模板的种类)进行分层划分与孤立划分,分别用来检验模型的拟合能力和泛化能力。 2)改进Labeling方法:USPTO数据集里的反应条件是2012年由Lowe开发的基于规则的NLP算法,自动从文本中提取的,因此目前可以尝试用新的基于预训练的深度学习模型进行文本信息提取,准确率与召回率可以达到95%。 3)拓展数据集:本文ORDerly重点关注USPTO数据集,然而USPTO的数据质量并不如其他高通量的反应数据集(针对特定种类的小规模反应数据,例如Buchwald偶联反应),存在实验室、人工之间的系统误差,并且几乎没有阴性数据(负样本)。此外,报道的反应条件不一定是最佳条件,预测的反应条件虽然与报道不同,但是也有可能是可行的。因此一方面需要更高质量的大规模数据库,另一方面需要拓展统一化、标准化、包含正负样本的高通量实验数据。 参考文献 [1] Wigh, D.; Arrowsmith, J.; Pomberger, A.; Felton, K.;
Lapkin, A. ORDerly: Datasets and benchmarks for chemical reaction data. ChemRxiv2023. DOI: 10.26434/chemrxiv-2023-qkjtb. [2]
Coley, C. W.; Green, W. H.; Jensen, K. F. RDChiral: An RDKit Wrapper for
Handling Stereochemistry in Retrosynthetic Template Extraction and Application.J. Chem. Inf. Model. 2019, 59 (6), 2529-2537. DOI:
10.1021/acs.jcim.9b00286. [3]
Thakkar, A.; Kogej, T.; Reymond, J.-L.; Engkvist, O.; Bjerrum, E. J. Datasets
and their influence on the development of computer assisted synthesis planning
tools in the pharmaceutical domain. Chem. Sci. 2020, 11(1), 154-168, 10.1039/C9SC04944D. DOI: 10.1039/C9SC04944D. [4]
Gao, H.; Struble, T. J.; Coley, C. W.; Wang, Y.; Green, W. H.; Jensen, K. F.
Using Machine Learning To Predict Suitable Conditions for Organic Reactions. ACS
Cent. Sci. 2018, 4 (11), 1465-1476. DOI:
10.1021/acscentsci.8b00357. 点击左下角的" 阅读原文 "即可查看原文章。
作者:黄志贤
审稿:郭家盛
编辑:王宇哲
GoDesign
ID:Molecular_Design_Lab
( 扫描下方二维码可以订阅哦!)
内容中包含的图片若涉及版权问题,请及时与我们联系删除


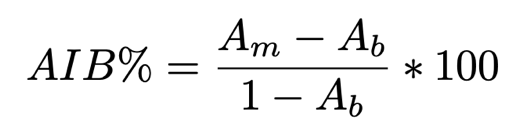 从表1可以看出,在所有数据集上,神经网络模型都优于基于频率预测的基线。标签(labeling)数据集的表现优于从反应字符串提取(reaction string)的数据集,这可能是因为labeling数据集中存在溶剂、试剂被标为反应物,降低了预测难度。
从表1可以看出,在所有数据集上,神经网络模型都优于基于频率预测的基线。标签(labeling)数据集的表现优于从反应字符串提取(reaction string)的数据集,这可能是因为labeling数据集中存在溶剂、试剂被标为反应物,降低了预测难度。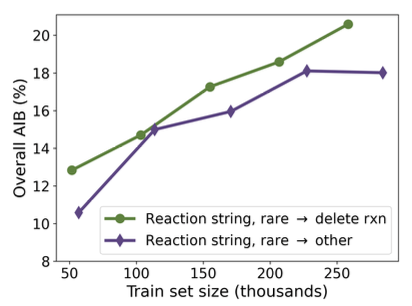


评论
沙发等你来抢