
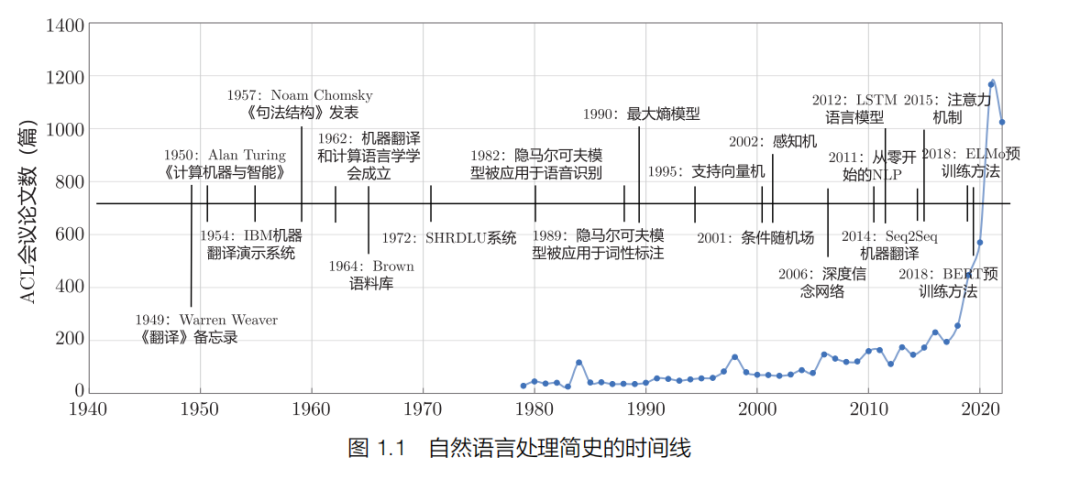
由于自然语言是人类最方便、最重要的交流方式,是描述知识、传承文化的重要工具,因此对自然语言处理的研究几乎从计算机一出现就开始了。这一领域也一直是人工智能研究的重要分支。自然语言处理的发展历史悠久,涉及的面很广,积累了大量的成果,但这些成果分散在多个领域。
因此,一本全面、系统介绍自然语言处理的书是非常必要的。
写这样的书也是一项艰巨的任务,需要从大量已有成果中筛选出既有代表性,又能全面反映领域发展全貌的材料,并将它们合理地组织起来。复旦大学张奇、桂韬、黄萱菁三位老师在经过几十次的讨论,以及对大纲和结构的反复修改后,历时近三年之久,《自然语言处理导论》终于完成。


本书的目标是介绍自然语言处理的基本任务和主要处理算法。为了能够让读者更好地了解任务的特性和算法设计的主要目标,在介绍每个自然语言处理任务时,除了介绍任务的目标,还会介绍该任务所涉及的主要语言学理论知识以及任务的主要难点。针对自然语言处理历史发展过程中的不同研究范式,选择不同类型的算法进行介绍。
自然语言处理的研究内容十分庞杂,整体上可以分为基础算法研究和应用技术研究。基础算法研究又可以细分为自然语言理解和自然语言生成。从语言单位的角度来看,涵盖了字、词、短语、句子、段落、篇章等不同粒度。从语言学研究的角度来看,则涉及形态学、语法学、语义学、语用学等不同层面。此外,由于目前绝大多数自然语言处理算法都采用基于机器学习的方法,针对特定的自然语言处理任务,以有监督、无监督、半监督、强化学习等不同的机器学习算法为基础进行构建。因此,自然语言处理研究又与机器学习和语言学的研究交织在一起,使得自然语言处理的研究内容涉及范围广,学科交叉度大。
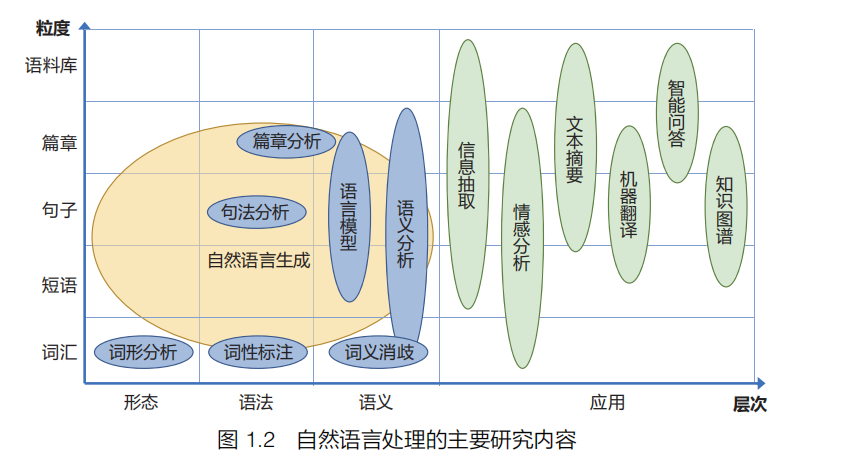
从自然语言处理研究内容的难度来看,从形态、语法、语义到语用是逐层递增的。目前基于机器学习和深度学习的自然语言处理算法的处理主要集中在形态、语法、语义这三个层面,基于目前的处理框架,部分语义层面的任务仍较难突破,语用层面的任务难度更大,在该层面的研究相对较少。我们从语言单元粒度和语言学研究层次两个维度,对自然语言处理的主要研究内容进行了归类,如图 1.2 所示。
01
自然语言处理的基本范式
自然语言处理的发展经历了从理性主义到经验主义,再到深度学习三个大的历史阶段。在发展过程中也逐渐形成了一定的范式,主要包括:基于规则的方法、基于机器学习的方法和基于深度学习的方法。这三种范式也基本对应了自然语言处理的不同发展阶段的重点。需要特别说明的是,虽然以上三种范式来源于自然语言处理的不同发展阶段,有明显的发展先后顺序,并且在大部分自然语言处理任务的标准评测集合中,基于深度学习的方法都好于基于机器学习的方法,更优于基于规则的方法,但是它们各有利弊,在实际应用中需要根据任务的特点、计算量、可控制性、可解释性等具体情况进行选择。
上述三种范式虽然有很大的不同,但是它们一个相同点,就是都需要针对特定的任务进行构建。面向不同的任务,按照不同的范式构建数据、模型等不同方面,所得到的算法或者系统仅能够处理特定的任务。在基于机器学习和基于深度学习的范式下,即使对模型预测目标进行微小修正,通常也都需要对模型进行重新训练。对于未知任务的零样本学习(Zero-shot Learning)能力,则很少在上述范式中进行讨论和研究。基于机器学习和基于深度学习的范式也很难实现模型对未知任务的泛化。随着 2022 年 11 月 ChatGPT 的发布,大模型所展现出来的文本生成能力以及对未知任务的泛化能力,使得未来的自然语言处理的研究范式很可能会发生非常大的变化。
▊ 基于规则的方法
基于规则的自然语言处理方法的主要思想是通过词汇、形式文法等制定的规则引入语言学知识,从而完成相应的自然语言处理任务。这类方法在自然语言处理早期受到了很大的关注,包括机器翻译在内的很多自然语言处理任务都采用此类方法。目前,仍有很多系统还在使用基于规则的方法。基于规则的自然语言处理方法的基本流程如图 1.3 所示,主要包括数据构建、规则构建、规则使用和效果评价四个部分。
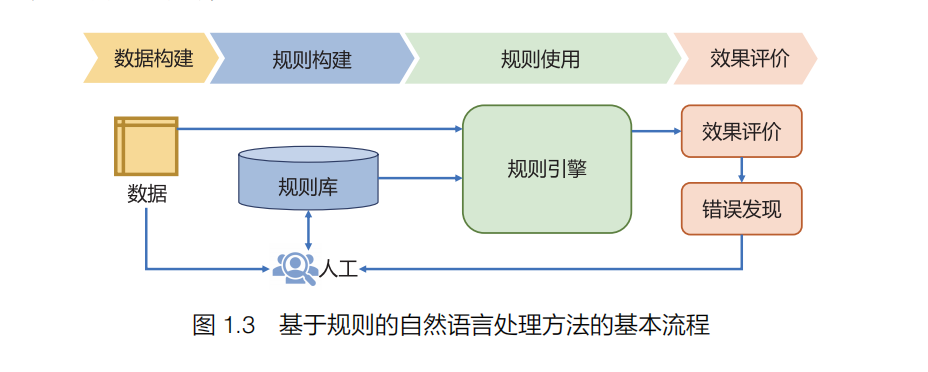 基于规则的方法的核心是规则形式定义,其目标是使语言学家可以在不了解计算机程序设计的情况下,能够容易地将知识转换为规则。这就要求规则描述具有足够的灵活性,并易于使用和理解。规则引擎的目标是高效地解析这些人工定义的大量规则,针对输入数据,根据规则库进行解释执行,从而完成特定的任务。这种方式使语言学家不需要编写代码就可以完成规则库的构建。
基于规则的方法的核心是规则形式定义,其目标是使语言学家可以在不了解计算机程序设计的情况下,能够容易地将知识转换为规则。这就要求规则描述具有足够的灵活性,并易于使用和理解。规则引擎的目标是高效地解析这些人工定义的大量规则,针对输入数据,根据规则库进行解释执行,从而完成特定的任务。这种方式使语言学家不需要编写代码就可以完成规则库的构建。
▊ 基于机器学习的方法
基于机器学习的自然语言处理方法绝大部分采用有监督分类算法,将自然语言处理任务转换为某种分类任务,在此基础上根据任务特性构建特征表示,并构建大规模的有标注语料,完成模型训练。其基本流程如图 1.4 所示,通常分为四个步骤:数据构建、数据预处理、特征构建和模型学习。
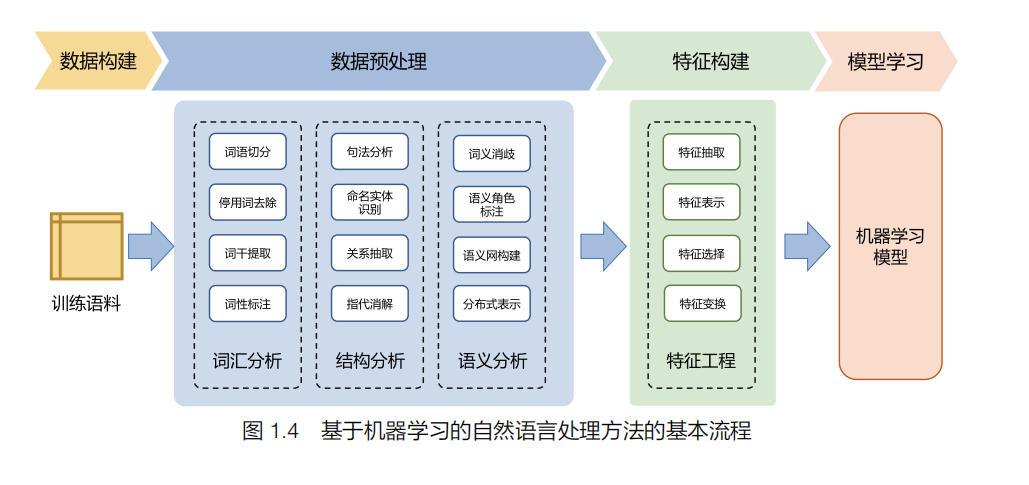
通过整体流程可以看到,基于机器学习的自然语言处理方法需要针对任务构建大规模的训练语料,以人工特征构建为核心,针对所需的信息利用自然语言处理的基础算法对原始数据进行预处理,并需要选择合适的机器学习模型,确定学习准则,采用相应的优化算法。在整个流程中,需要人工参与和选择的环节非常多,从特征设计到模型,再到优化方法和超参数,并且这些选择非常依赖经验,缺乏有效的理论支持,这也使得基于机器学习的方法需要花费大量的时间和工作在特征工程上。开发一个自然语言处理算法的主要时间都消耗在数据预处理、特征构建、模型选择和实验上。此外,对于复杂的自然语言处理任务,需要在数据预处理阶段引入很多不同的模块。首先,这些模块之间需要单独优化,其目标并不一定与任务总体目标一致。其次,多模块的级联会造成错误传播,前一步的错误会影响后续的模型,这些问题都提高了基于机器学习的方法实际应用的难度。
▊ 基于深度学习的方法
基于深度学习(Deep Learning)的方法通过构建具有一定“深度”的模型,将特征学习和预测模型融合,通过优化算法使模型自动地学习到好的特征表示,并基于此进行结果预测。基于深度学习的自然语言处理方法的基本流程如图 1.5 所示。与传统机器学习算法的流程相比,基于深度学习方法的流程简化很多,通常仅包括数据构建、数据预处理和模型学习三个部分。同时,在数据预处理方面也大幅度简化,仅包含非常少量的模块,甚至目前很多基于深度学习的自然语言处理方法可以完全省略数据预处理阶段。例如,对于汉语,直接使用汉字作为输入,不提前进行分词;对于英语,也可以省略词的规范化步骤。
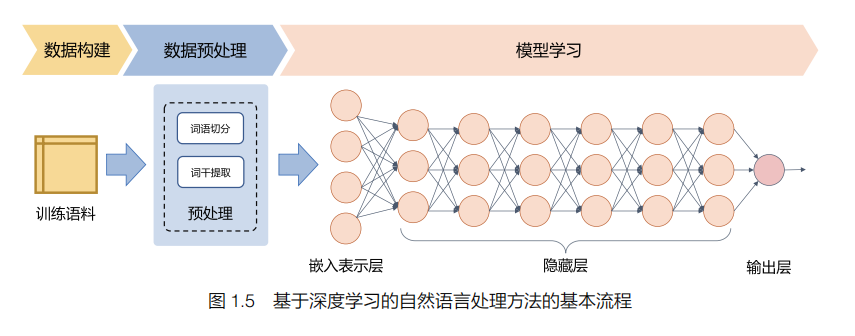
深度学习是机器学习的一个子集,通过多层的特征转换,将原始数据转换为更抽象的表示。这些学习到的表示可以在一定程度上完全代替人工设计的特征,这个过程也叫作表示学习(Representation Learning)。随着深度学习研究的不断深入和计算能力的快速发展,模型深度也从早期的 5 ∼ 10 层增加到现在的数百层。随着模型深度的不断增加,其特征表示能力也在不断增强,从而也使得深度学习模型中的预测部分更加简单,预测也更加容易。
自 2018 年 ELMo 模型被提出之后,基于深度学习的自然语言处理范式又进一步演进为预训练微调范式。首先利用自监督任务对模型进行预训练,通过海量的语料学习到更为通用的语言表示,然后根据下游任务对预训练网络进行调整。这种预训练微调范式在几乎所有自然语言处理任务上的表现都非常出色。预训练模型在模型网络结构上可以采用 LSTM、Transformer 等具有较好序列建模能力的模型,预训练任务可以采用语言模型、掩码语言模型(Masked LanguageModel)、机器翻译等自监督或有监督的方式,还可以引入知识图谱、多语言、多模态等扩展任务。自 2018 年以来相关研究非常多,取得了非常好的效果,但仍然面临模型稳健性提升、模型可解释性等诸多问题亟待解决。
▊ 基于大模型的方法
大模型是大规模语言模型(Large Language Model)的简称。从 2018 年开始以 BERT、GPT为代表的预训练语言模型相继推出,它们在各种自然语言处理任务上都取得了非常好的效果。此后,语言模型的规模不断扩大,2020 年 OpenAI 发布的 GPT-3 模型的规模达到了1750 亿参数量,Google 发布的 PaLM 模型[41] 的参数量达到了 5400 亿。这种参数量级的语言模型很难再延续此前针对不同的任务而使用的预训练微调范式。因此,研究人员开始探索使用提示词(Prompt)模式完成各种类型的自然语言处理任务。此后又提出了指令微调(InstructionFinetuning)方案,将大量各种类型的任务统一为生成式自然语言理解框架,并构造训练语料进行微调。2022 年 ChatGPT 所展现出的通用任务理解能力和未知任务泛化能力,使得未来自然语言处理的研究范式可能进一步发生变化。如图 1.6 所示,基于大模型的自然语言处理方法的基本流程包括大规模语言模型构建、通用能力注入和特定任务使用三个主要步骤。
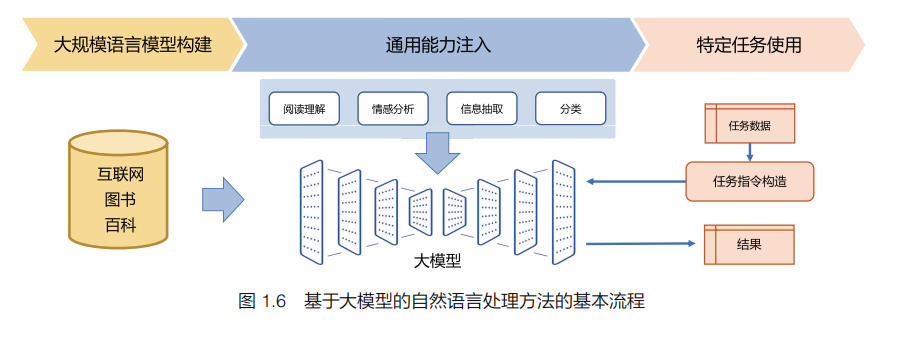
在大规模语言模型构建阶段,通过大量的文本内容训练模型对长文本的建模能力,使得模型具有语言生成能力,并使得模型获得隐式的世界知识。由于模型参数量和训练数据量都十分庞大,普通的服务器单机无法完成训练过程,因此需要解决大模型的稳定分布式架构和训练问题。在通用能力注入阶段,利用包括阅读理解、情感分析、信息抽取等现有任务的标注数据,结合人工设计的指令词对模型进行多任务训练,从而使得模型具有很好的任务泛化能力,能够通过指令完成未知任务。特定任务使用阶段则变得非常简单,由于模型具备了通用任务能力,只需要根据任务需求设计任务指令,将任务中所需处理的文本内容与指令结合,然后就可以利用大模型得到所需的结果。
如果该范式在非常多的任务上都达到了目前基于预训练微调范式的结果,那么就会使得自然语言处理产生质的飞跃。突破了传统自然语言处理需要针对不同的任务进行设计和训练的瓶颈,任务可以不需要预先给定,仅依赖很少的任务特定标注数据,或者完全不依赖任何任务的有监督数据就可以得到相应的结果。当然,这种方法也仅仅刚刚展露出一定的希望,当前使用该范式的大模型在绝大部分任务上所取得的效果仍然与基于预训练微调范式的结果有很大的差距,模型参数量太大导致训练和使用的成本过高…… 这些问题都亟待研究。
02
本书内容安排
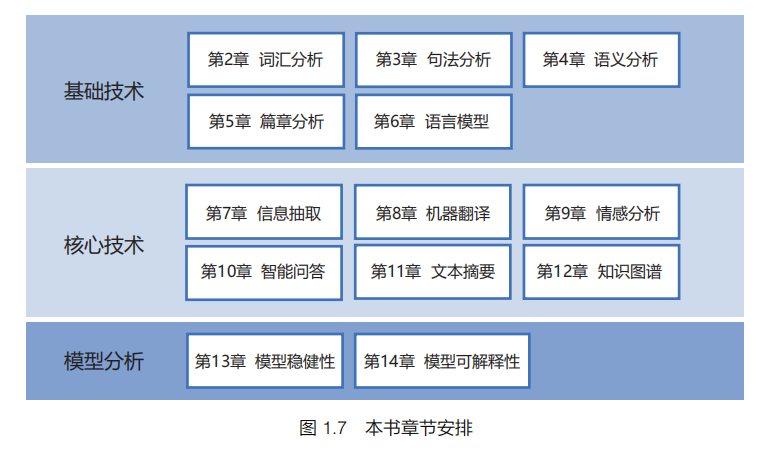
本书共分为 14 章,主要包含三个部分:第一部分主要介绍自然语言处理的基础技术,包括词汇分析、句法分析、语义分析、篇章分析和语言模型;第二部分主要介绍自然语言处理的一系列核心技术,包括信息抽取、机器翻译、情感分析、智能问答、文本摘要、知识图谱;第三部分主要介绍基于机器学习的自然语言处理模型的稳健性和可解释性问题。本书章节安排如图 1.7 所示。


全书近600页,全彩印刷
复旦大学教授历时3年打造的精品图书
从规则方法到大语言模型基础
全面覆盖NLP典型范式
配全书PPT课件
专属五折,快快扫码抢购吧!
福利时间
活动方式:在添加下方微信好友,备注『NLP』,届时我们会拉群抽奖,在参与的小伙伴中选取3名幸运鹅!
活动时间:截至8月30日开奖。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢