论文链接:
https://arxiv.org/abs/2307.07944
https://github.com/zhuoxiao-chen/ReDB-DA-3Ddet
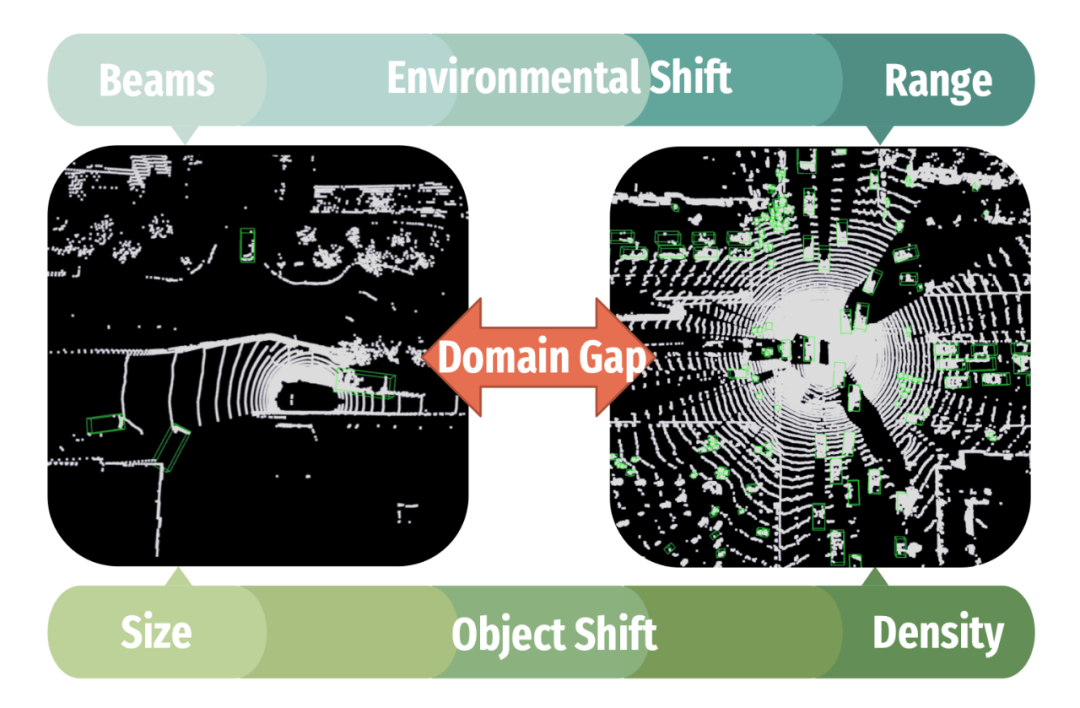
概述 随着基于激光雷达(LiDAR)的三维物体检测在机器人系统和自动驾驶汽车等各种应用中不断发展,解决在实际场景中部署检测器所面临的挑战变得愈加重要。主要难题源于训练数据和测试点云数据之间的差异,这些数据通常来自不同的场景、位置、时间和传感器类型,造成了“域差异”。 域差异主要来自于物体差异和环境差异,这些因素会显著降低 3D 检测器的预测精度。物体差异指的是训练和测试域之间物体的空间分布、点密度和尺度的变化。例如,Waymo 数据集中汽车的平均长度与 KITTI 数据集中的平均长度相差约 0.91 米。另一方面,环境差异则源自于周围环境的复合差异,如不一致的光束数量、角度、点云范围和数据采集位置。 ▲ 例如,在这个图中,Waymo(右)利用 64 束激光雷达传感器生成 3D 场景,而 nuScenes(左)则由更稀疏的 32 束环境和双大束角构成。
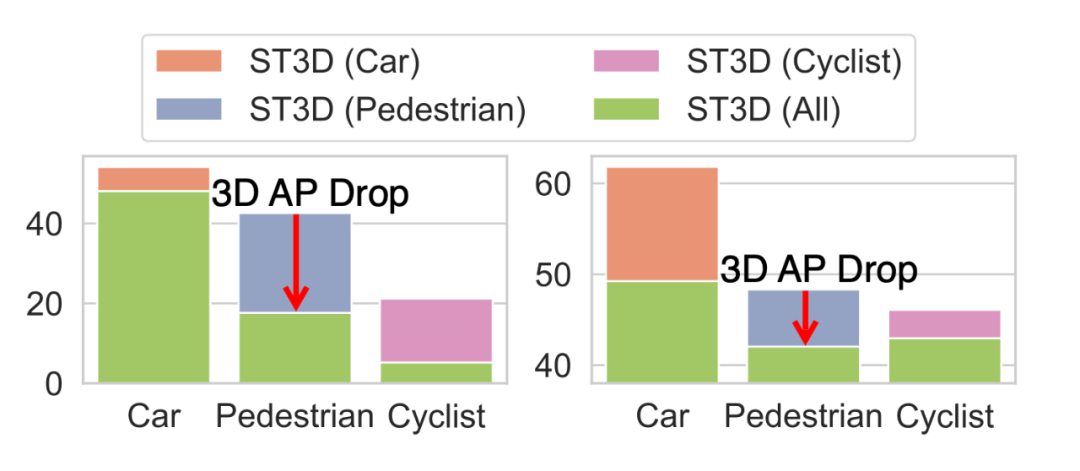
重新审视领域自适应 3D 检测设置。 已有的领域自适应 3D 目标检测方法通常遵循 单类别训练 设置,即对模型进行训练,使其分别适应每一个类别。虽然同时用所有类别来训练一个模型更为实际和公平,但我们的实证研究表明,在切换到 多类别设置 时,先前方法的检测性能会显著下降(如下图)。这种平均精度(AP)的下降可以归因于生成的伪标签的质量较差(即错误和冗余),以及稀有类别的较低识别准确率(例如在 Waymo 中自行车比汽车少 91 倍)。
▲ 将多类别 3D 检测器通过 ST3D 的方法进行领域自适应时,平均精度(AP)的降低情况。左图是从 nuScenes 到 KITTI,右图是从 Waymo 到 KITTI。
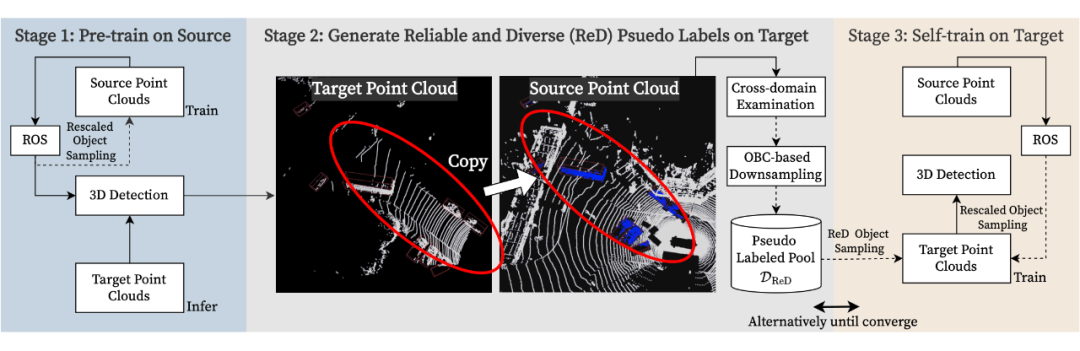
我们的工作将领域自适应三维检测的设置 修正为多类别情景 ,并提出了一种新颖的 ReDB 框架,用于在跨域三维目标检测中生成可靠、多样和类平衡的伪标签。在三个大规模测试集上的大量实验证据表明,所提出的 ReDB 对于基于体素和基于点的现代 3D 检测器在不同环境下都具有出色的适应性,在 nuScenes → KITTI 任务中,分别相对于现有最先进的方法提高了 20.66% 和 23.15% 的 3D mAP。 方法
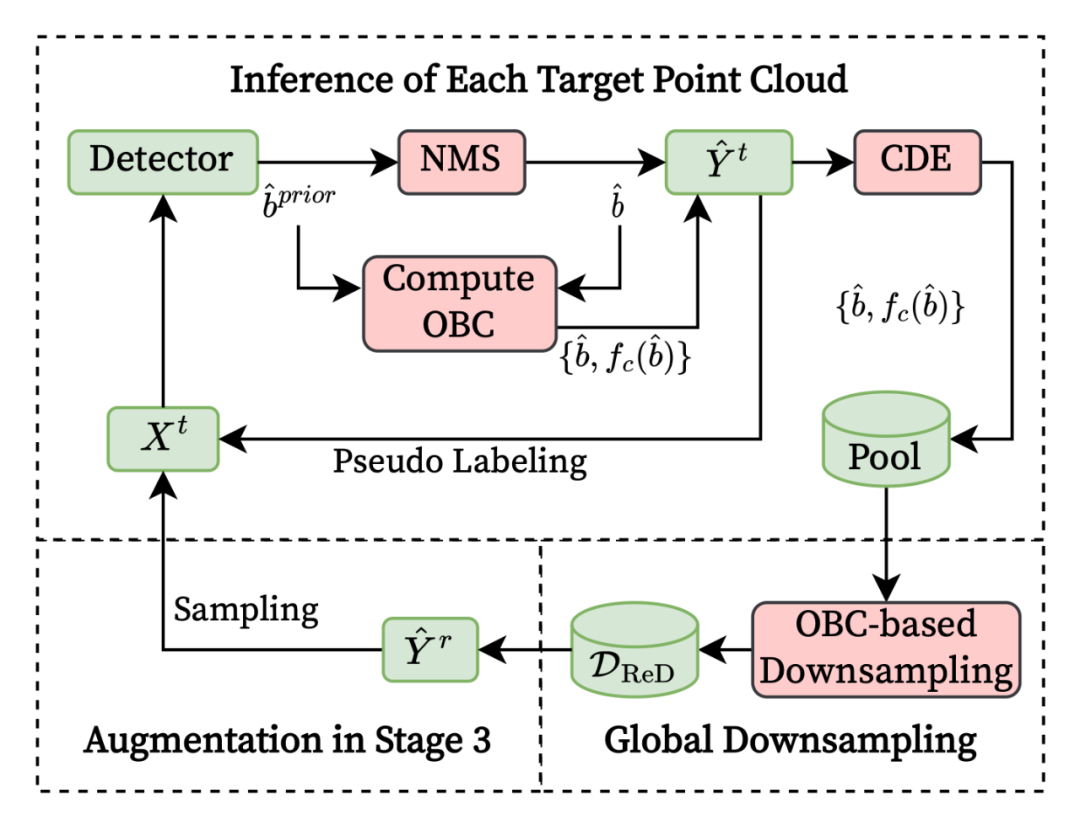
在第一阶段,3D 检测器(例如,SECOND 或 PointRCNN)在源域上进行预训练,同时使用随机物体缩放(ROS)进行数据增强。在预训练收敛后,即第二阶段,将未标记的目标域点云传递给预训练的检测器,以为目标域的数据生成高置信度的伪标签。 具体而言,所产生的伪标签将经过跨域检查(Cross-Domain Examination,简称 CDE),并由基于重叠框计数(Overlapped Box Counting,简称 OBC)的多样性模块进行下采样,形成可靠且多样化的(RED)的伪标签物体子集。在第三阶段对目标域进行模型自训练时,我们以类平衡的方式在每个点云中随机注入 RED 目标域物体和源域对象,并且源样本的比例逐渐降低。3D 检测器通过在第二阶段和第三阶段之间交替进行,迭代地进行以适应目标域的环境。
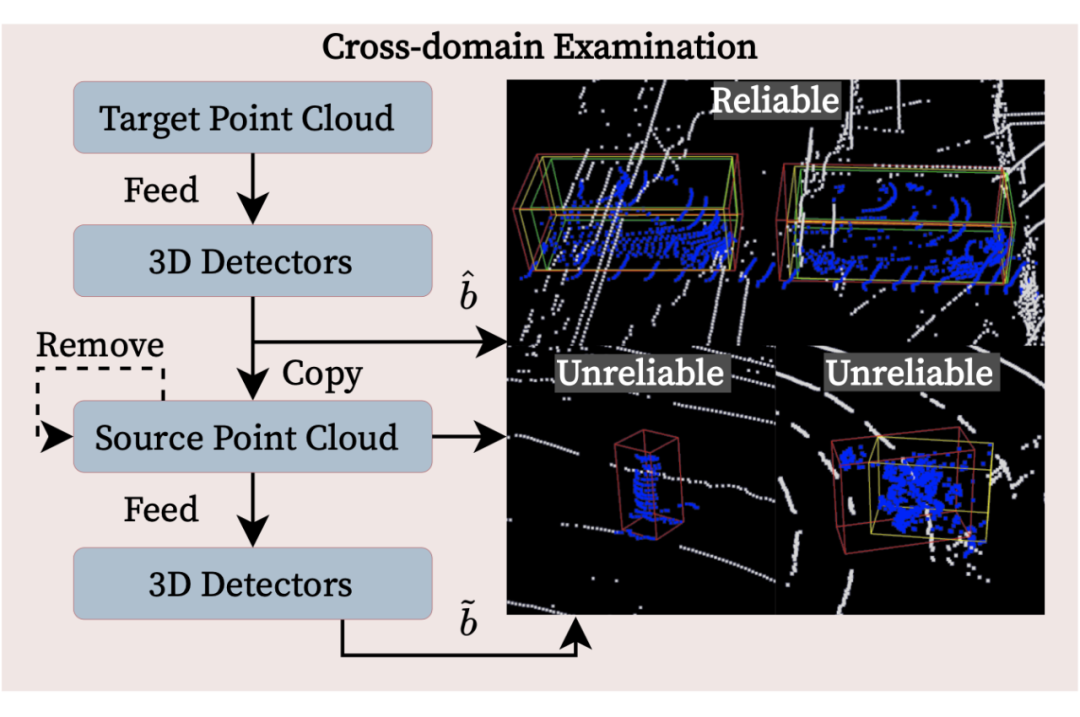
为了消除高置信度的错误伪标签并避免自训练中的错误累积,我们引入了一种跨域检查(CDE)策略来评估伪标签的可靠性。在将伪标签的目标域的物体复制到模型所熟悉的源域环境中再进行预测,我们通过目标域和源域中两个预测框之间的一致性,即交并比(Intersection-over-Union,IoU)来衡量伪标签的可靠性。 任何 IoU 值较低的物体都将被视为不可靠。为了防止源域和目标域点云之间的点冲突,我们会删除落在将复制伪标签物体区域内的源域点。所提出的 CDE 策略确保接受的伪标签物体是领域无关的,并且受 环境差异 的影响较小。
▲ 所提出的跨域检查(CDE)策略。蓝色点为被复制到源域点云的伪标签物体。红色和黄色框分别表示目标域和源域中的预测框。绿色框为真值,在这里仅作参考。例子一:目标域和源域的预测框之间 IoU 足够大,该伪标签可靠性被接受;例子二和三:源域中未被检测到,或 IoU 不够大,该伪标签可靠性不被接受。
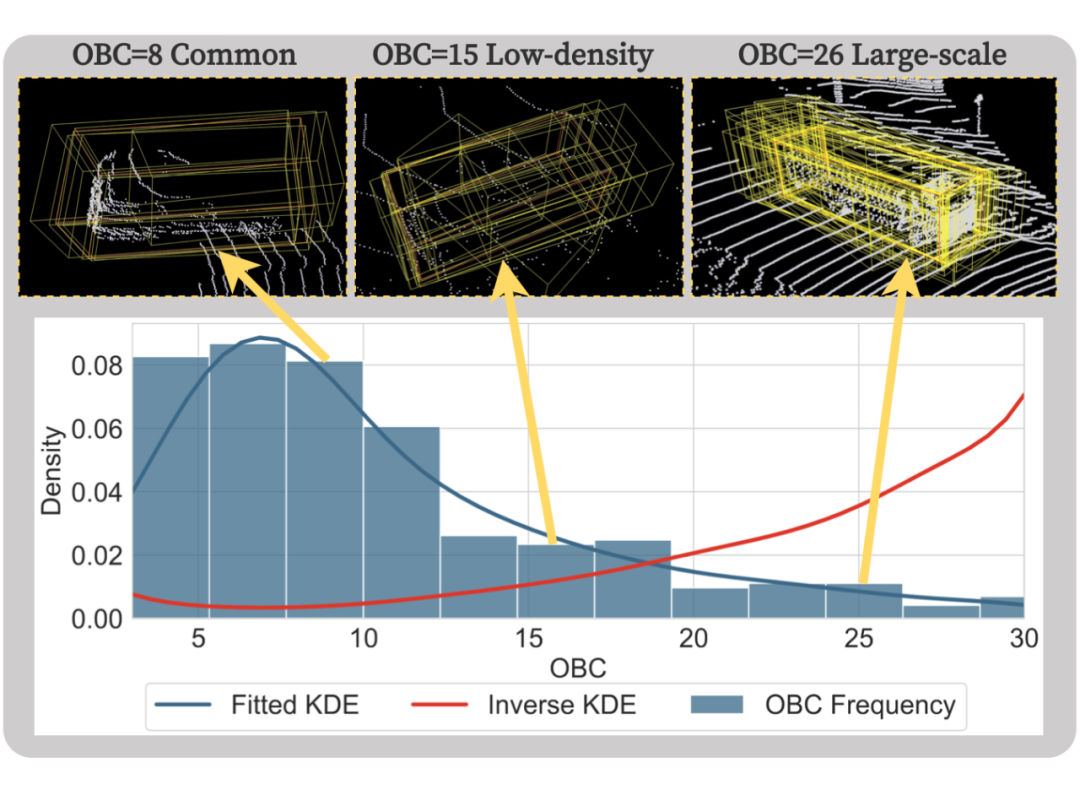
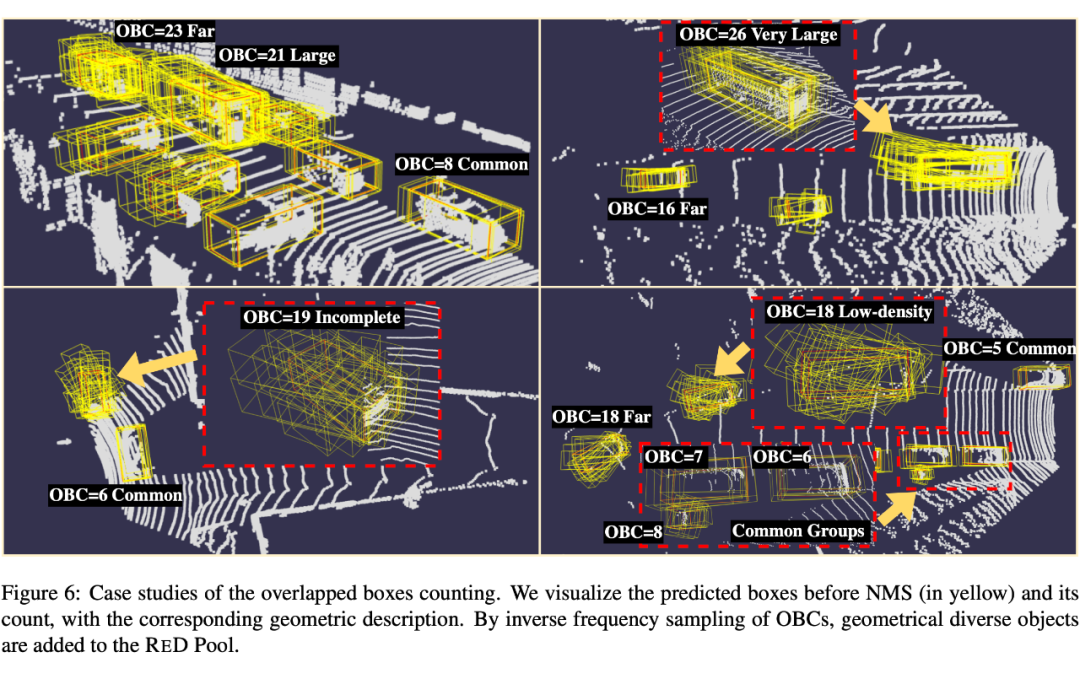
为了避免频繁出现且在尺度上相似的冗余伪标签,必须防止训练的检测器塌陷到一个固定的模式中,这种模式可能只会检测到某些固定模式的物体(如小型汽车),而漏掉其他风格特殊的物体(如公共汽车和卡车)。为了增强几何多样性,我们提出了一个称为“重叠框计数(OBC)”的指标来均匀地下采样伪标签。该度量的设计灵感来自于以下观察:3D检测器倾向于为具有不常见几何形状的物体预测更多的边界框,因为仅使用少量紧密边界框难以定位这些物体。 我们将每个检测到的物体周围的回归边界框数目作为 OBC,并使用核密度估计(KDE)来估计其经验分布。然后,我们根据 KDE 的反概率进行下采样,从而有效减少了高密度 OBC 区域的伪标签数量,因为这些区域的物体具有相似且频繁的几何形状。通过从多样化的伪标签子集中学习,3D 检测器可以更好地识别不同尺度和点密度的物体,潜在地消除 物体差异 。
▲ 重叠框计数(OBC)示意图。上半部分显示的是在非极大值抑制(NMS)之前生成的围绕三个具有不同 OBC 值的正预测物体的预测框。下图展示了所有检测到的物体的 OBC 值分布,以及用于多样下采样的拟合核密度估计(KDE,蓝色)和反向核密度估计(inverse KDE,红色)。
尽管前两个模块能够选择可靠且多样化(ReD)的伪标签,但仍存在严重的类间不平衡。为了实现类平衡的自训练,我们随机向每个目标域的点云注入伪标签物体,每个类别中的样本数量相等。通过从这种类别平衡的目标域数据中学习,模型能够更好地掌握目标域标签的整体语义。 为了实现从源域数据到目标域数据的平滑过渡,我们首先在最初的训练步中以类平衡的方式用真标签(Gound truth)的源域物体来增强目标域数据。然后随着自训练的进行,我们逐渐减少源域物体的比例,增加 ReD 伪标签的数量。这种渐进式的类平衡自训练使模型能够稳定地适应目标域,增强对频繁出现和罕见类别的识别能力。 在第二阶段,我们将每个目标点域云 输入到预训练好的检测器中,并获得 3D 边界框预测。通过采用非极大值抑制(NMS),我们选择置信度高且不重叠的方框 作为伪标签。同时,我们基于 NMS 之前的框 为每个伪标签框 计算 OBC 分数。 接下来,我们使用 CDE 将合格的 添加到伪标签池中。在推理所有目标域数据之后,我们使用 OBC 对池中的伪标签框进行全局下采样,得到 。在第三阶段,我们在自训练过程中以类平衡的方式从 中采样高质量伪标签(ReDB)物体,从而增强每个目标域点云。第二阶段和第三阶段交替进行,直至收敛。
实验
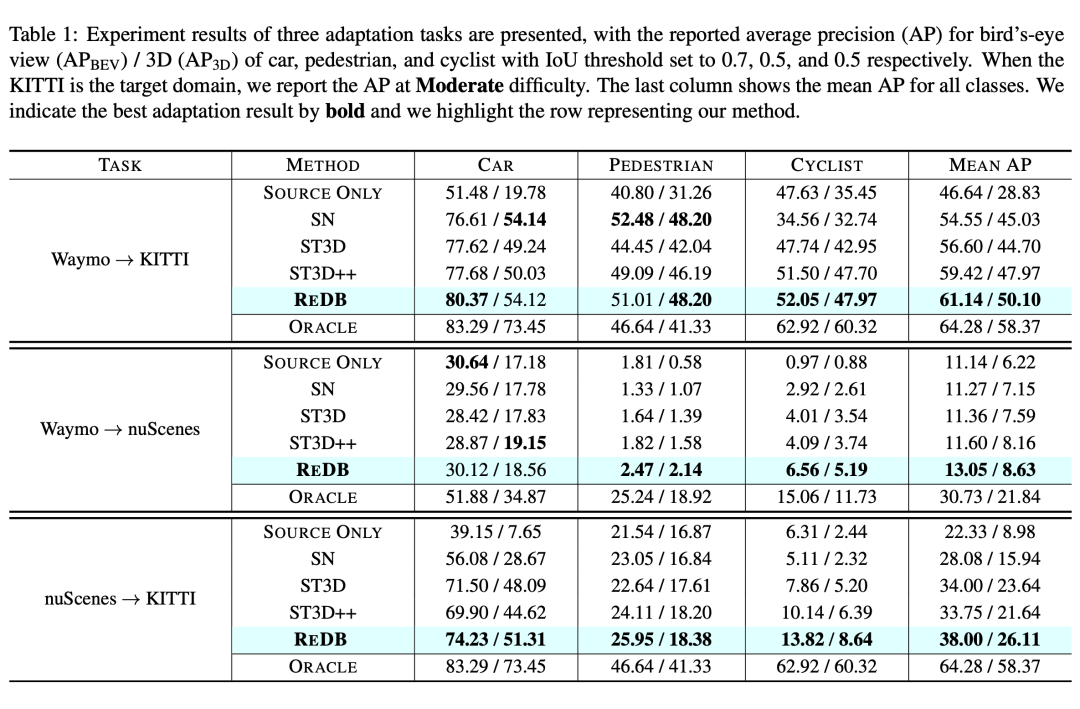
1)SECOND 在 Waymo → KITTI, Waymo → nuScenes 以及 nuScenes → KITTI 三个领域自适应任务上的结果对比。
所提出的 ReDB 在后两个任务(即 Waymo → nuScenes 和 nuScenes → KITTI)中获得的性能明显高于第一个任务(即 Waymo → KITTI),这表明 ReDB 对于适应具有较大环境差异的 3D 场景更加有效。更明显的是,ReDB 方法在所有类别中的表现都很均衡,而所有 baslines 方法都偏向于最常出现的类别(即汽车),在罕见类别(即行人和骑车人)中表现不佳。总体而言,在跨域三维目标检测任务的所有场景中,ReDB 优于所有 baslines 方法。
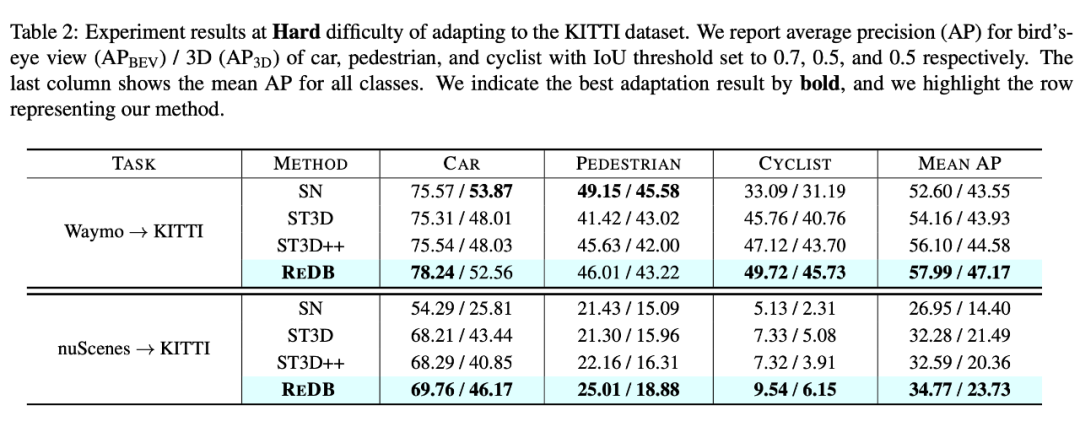
2)SECOND 在 Waymo → KITTI 以及 nuScenes → KITTI 两个领域自适应任务上,用困难指标来评估指标计算的结果对比。
在从 Waymo 自适应到 KITTI 的过程中,所提出的 ReDB 优于 SOTA 方法 ST3D++ 5.81% 的 3D mAP 。在更具挑战性的跨域检测任务中(即 nuScenes → KITTI),光束数量、角度和点云范围都会发生显著的环境变化,ReDB 比 SOTA 方法的 mAP 3D 高出 16.55%。因此,当使用 KITTI 指标的 困难难度指标 来评估时,我们的方法远远超过了 baseline 方法,这表明 ReDB 能够使 3D 检测器有效地泛化到目标域中困难的物体。
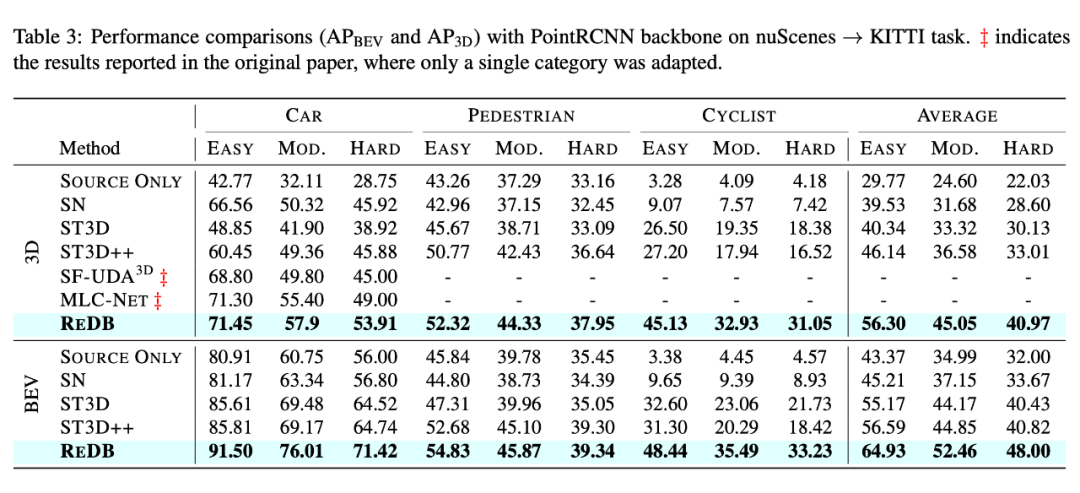
3)PointRCNN 在 nuScenes → KITTI 任务上结果对比。
值得注意的是,与 MLC-Net 和 在 单类别训练 设定下得到的结果相比,我们的多类别方法 ReDB 甚至取得了更卓越的性能(分别提升了 10.02% 和 19.8%),且这两种方法都是专为基于点的 3D 检测器设计的。
我们可以看到,大多数具有较小OBC值(例如,介于 5 和 8 之间)的物体通常具备以下特点:1)通常更接近激光雷达传感器,2)具有完整的物体形状,3)通常是小尺寸的物体。这些物体通常具有高度相似且完整的几何特征,构成了数据集的大部分。相反,具有高 OBC 值的物体在几何表示的一个或多个方面通常具有多样性。在物体尺寸方面,大尺寸物体往往会产生较高的 OBC 分数(如 21 和 26)。 除了物体体积外,我们还可以发现明显远离激光雷达中心的物体也会产生较高的 OBC 值(从 16 到 23),而低密度和严重遮挡的物体也会产生较高的 OBC 值,分别为 18 和 19。因此,所提出的 OBC 指标能够有效地在几何特征的多个维度上量化伪标签的多样性,有助于三维检测器学习更多样化的目标物体分布,从而缓解跨域目标检测中的多维度的物体差异问题。 方法不足与未来展望 尽管我们的方法在性能上相较于以往取得了显著的提升,但在涉及到域差异极大的三维场景(例如 Waymo → nuScenes)时,性能仍然受到限制,距离实际应用场景的要求仍有很大差距。除了域差异,另一个限制因素是当前最先进的三维目标检测器在 nuScenes 数据集上表现受限。因此,近期越来越多的研究方法开始将 2D 图像与 3D 点云进行融合,以在 nuScenes 等困难的数据集上获得更出色的目标检测效果。工业界也在积极探索这一融合策略并投入实际生产应用。 因此,未来的跨域目标检测任务可能需要考虑多模态信息,而不仅仅局限于使用单一的点云数据。这一发展趋势对于实现更全面、鲁棒的目标检测方法具有重要意义。 若觉得还不错的话,请点个 “赞” 或 “在看” 吧
全栈指导班
全栈指导班面向的是真正想从事CV的、想培养自己的能力和知识面的、具备算法工程师思维的朋友 。 有很多朋友仅仅了解自己的科研方向、仅仅了解YOLO怎么用,做过几个简单的项目,但从没系统地学过CV,也没有重视培养自己的学 习能力和思维能力。 也有很多朋友想找目标检测的岗位、医学图像的岗位,但实际上哪个企业招聘上写目标检测工程师呢?写的都是算 法 工程师,一个合格的算法工程师需要能快速上手任意一个新的方向,这意味着 需要 广泛大知识面、扎实的基础、 很强的 自学能力。知识面太少,谈何设计模型?不会看论文,谈何学习能力? 因此,对于全栈班而言,如何培养上面这三点是非常重要的。这也意味着它与基础入门班不同之处在于 全栈班更注重培养方法、能力以及知识面 。 内容范围:全栈。包括基础、代码能力、模型设计分析、目标检测、数字图像处理、部署等全流程 。 说明: 虽然看起来跟基础入门班内容没什么区别,但实际每个内容涉及更深、范围更广、要求更高,且包含部署方面的学习和能力培养 。 比如同样的模型设计,基础班只要求掌握十几个模型的设计思路,全栈班会要额外推荐一些重要的论文去学、要求效率更高,且基础班是老师直接讲,而全栈班是学员先自主学再指导,前者是入门、后者是深入学习。如果你本身是一个基础很好的,仅仅想学习部署方面的内容,也可以报名,我们会针对你的个人情况,单独设计部署方面的学习计划,安排有六年部署工作经验的大佬给你指导。 课程形式:50%学员自主学习+50%的方法、能力的指导培养 。可以理解为报了一个全栈班,就是找了两个大佬对你进行二对一指导,但仍然是你自己自学。 报名请扫描下方二维码,备注:“全栈班报名”
内容中包含的图片若涉及版权问题,请及时与我们联系删除



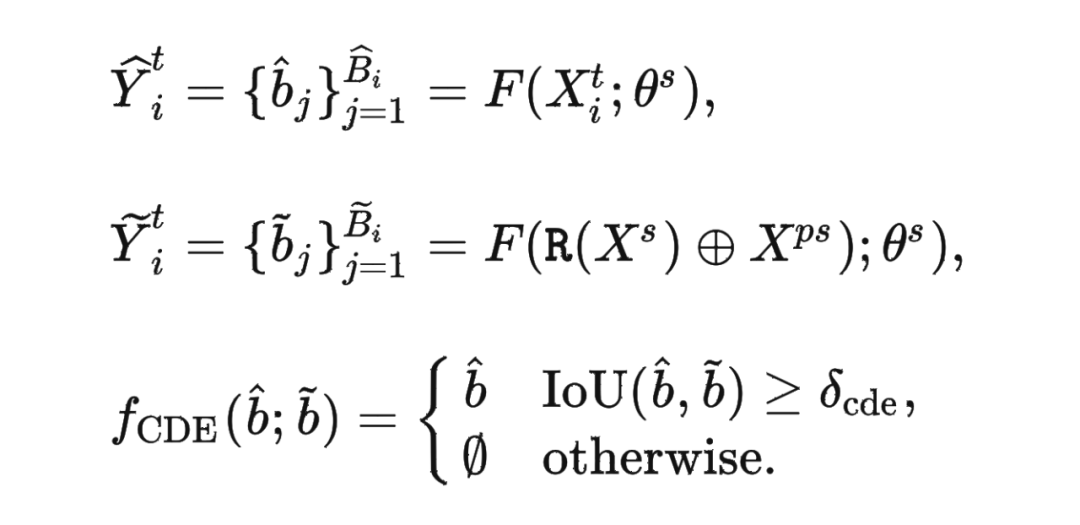
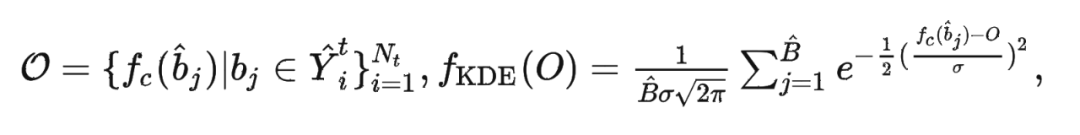




评论
沙发等你来抢