
。
本篇推文有两个重点:1.这家伙又要骗人买课了;2.超形象讲解AIGC相关的图像foundational model的相关技术点
(1)我们实诚点 ,这是个带有卖课的推文。区别于b站上大量的拿stable diffusion webui跑图应用的课程,他们很好,适合你体验AIGC的有趣,但是光靠跑图没法找到算法相关的工作和做深入的科研;另一种b站公开课是数学推导,他们也很好,有助于你详细了解期间的数学过程,但是你得写程序的。
,这是个带有卖课的推文。区别于b站上大量的拿stable diffusion webui跑图应用的课程,他们很好,适合你体验AIGC的有趣,但是光靠跑图没法找到算法相关的工作和做深入的科研;另一种b站公开课是数学推导,他们也很好,有助于你详细了解期间的数学过程,但是你得写程序的。
BUT!!!!作为一个算法工程师或者研究生、博士生,我们应该要深入原理和代码层面,将数学、图解原理、手写代码给统一、高度对应起来才是立于不败之地,不容易被取代的根本。
本次课程是由手写AI的Coey Liang(苏苏)主讲(对了! 就是那个在b站上讲剪枝sparsegpt和OBS复现的那位),不是du老师。
就是那个在b站上讲剪枝sparsegpt和OBS复现的那位),不是du老师。
好的,我们正题说完了,下面小伙伴们感兴趣的可以瞄一眼下面凑字数的文字。
(2)拥抱AIGC
AIGC 关于NLP的我就不做介绍了,就一句,OpenAI ChatGPT YYDS。国产大模型听说不错,隔行如隔山,这很难评。下面来快速过一下视觉生成大模型相关的重要技术点:
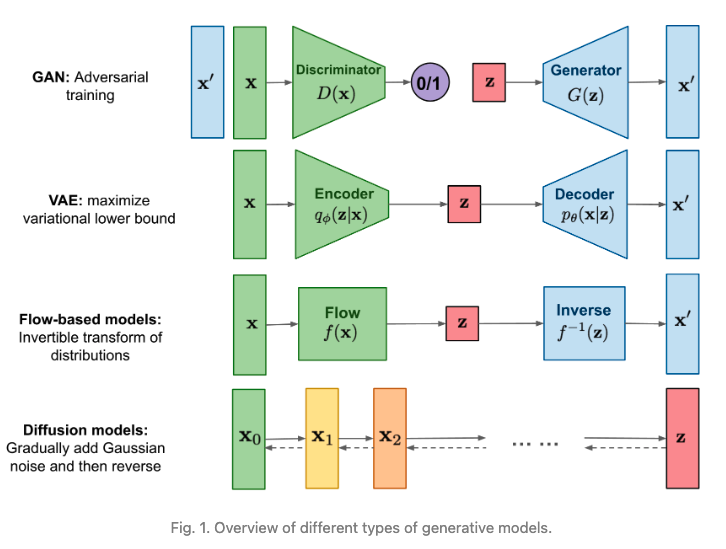
上面的图片中所涉及到的VAE和GAN大家可能做视觉的都比较熟悉,在很多数据生成、去噪、影片上色的工作中都会用到。最后的diffusion model这几年来最有代表性的工作就是OpenAI的DALL.E 、midjourney和runwayml这些明星初创公司。
以下我们通过图来去快速cover掉扩散生成式AI的基本知识,来勾起你现有知识与AIGC的知识的联系:
更加详细的版本:建议看下面两个视频:
【如果不想用脑,可以直接看视频-手写扩散模型-形象理解sd组件-"梵高"来画"蒙娜丽莎"
https://www.bilibili.com/video/BV1yN411B7hK/?share_source=copy_web&vd_source=c2943614860835ab3609130be342280f 】
【手写扩散模型-用混合高斯理解事物的采样和生成】 https://www.bilibili.com/video/BV1hN411B7RZ/?share_source=copy_web&vd_source=c2943614860835ab3609130be342280f
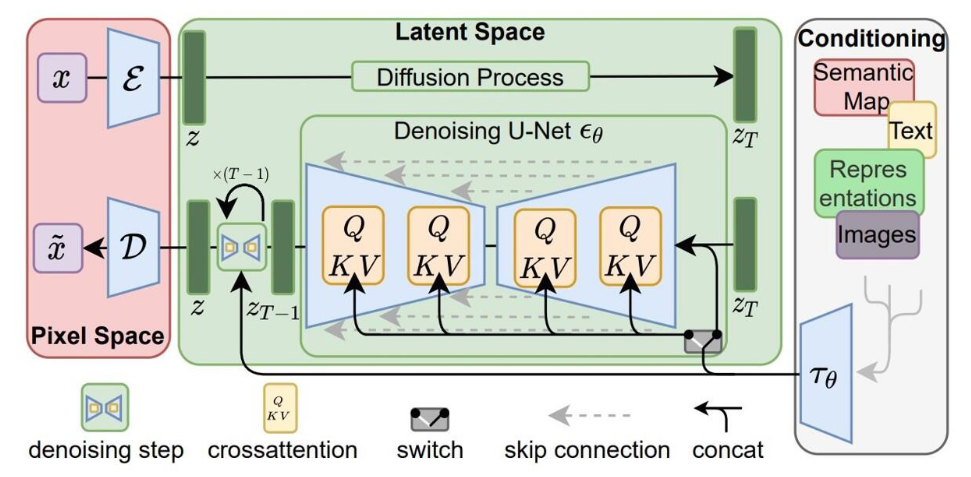
让我们来想象一下,我们让“梵高”去画一幅“蒙娜丽莎”。映入梵高眼睛都会是一幅现成的蒙娜丽莎,所以那得先学会并且找到画出(生成)蒙娜丽莎的方法。

1. 学习生成新样本的方法(学会拆解成品)

在拆解的过程当中,会有不一样的拆解策略,比如说我们一共要分多少步来拆解,每一步拆解得多与少?是不是可以早一点的阶段加拆多一点,后面的阶段拆少一点?这里对应的其实就是我们的加噪策略。

从很形象和很高维度的角度来说,你可以暂时不严谨地理解为,你拆的东西多了,你就学会了见过了各种东西,你就有学会拼回去的基础。这里对应的就是我们扩散模型中的前向扩散过程(forward diffusion)。
2. 如何拼回去?
理论上来手,你只要很清楚的指导你每一步是怎么拆的,你就可以训练一个神经网络,拿真值和预测值做对比,就相当于,梵高旁边站着个达芬奇,他拼接回去的时候,每一步拼之前都问一下达芬奇这样拼对不对,差多少,对应的就是下面的这个公式。为了让loss最小,左边的是真值,右边的是预测值。这里拼起来并且算loss就是我们的反向扩散(重建)过程(reverse diffusion)
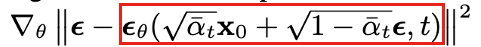

3.将图像和文字联系起来

现在梵高想给蒙娜丽莎加上一对翅膀。为了实现这个目标,他需要一个明确的指导方向。这时,原作达芬奇来了,他给了梵高一个指导方向:“蒙娜丽莎带有翅膀”。这个提示就像CLIP将文本转化为tensor的过程。接着,梵高将这个提示与他手头的蒙娜丽莎草图(也可以看作是一个tensor)结合起来,形成了一个完整的创作方向。
这个结合的过程,就像将提示的tensor与图像的tensor进行concat操作。有了这个结合后的方向,梵高开始绘画,确保在完成的画作中,蒙娜丽莎有了那对翅膀。
同样地,当我们使用diffusion模型和CLIP时,CLIP将文本提示转化为tensor,并与图像tensor结合,为模型提供了一个明确的创作方向。模型在这个方向的指导下,可以生成既符合原始目标(蒙娜丽莎的画像),又加入了新的元素(翅膀)的图像。以上对应的其实就是我们的conditioning
4.不是完全临摹
在重新创作蒙娜丽莎的过程中,梵高不会一丝不苟地复制每一个细节,而是捕捉画作的精髓或最重要的特征。这与自动编码器(AE)的工作方式相似。它将图像(或任何数据)压缩成更简洁的表示形式(潜在空间),然后重新构建它。这种压缩表示封装了数据的最关键特征,使得减轻了网络训练的压力,最直接的原因就是分辨率变小了。
5. 分层次地学习我们的画作
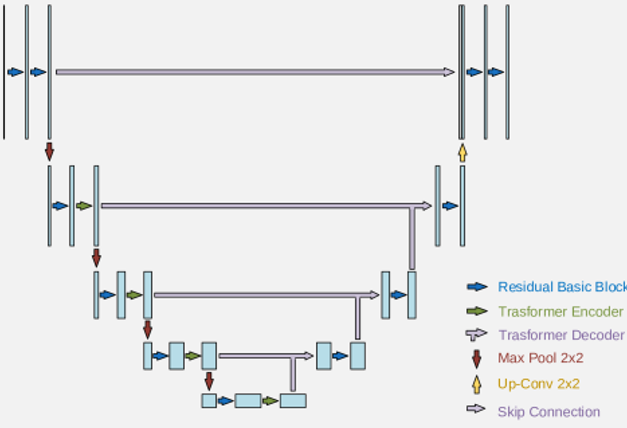
梵高在画蒙娜丽莎的过程中是分层次的学习我们的画作的。他首先从整体构图开始,确定画面的大致布局和主要元素的位置,这可以看作是捕捉图像的全局信息。然后,他逐渐关注细节,如蒙娜丽莎的微笑、眼睛和皮肤的纹理。这是从全局到局部的过程。
UNet的结构也遵循这种从全局到局部的思路。在UNet的编码阶段,图像被逐渐下采样,捕捉到的是全局的、粗糙的特征。随后,在解码阶段,这些特征被逐渐上采样并与之前的高分辨率特征结合,从而恢复图像的细节。
在扩散模型中,由于噪声的存在,直接恢复细节可能会导致错误。因此,首先捕捉全局信息,然后再逐步恢复细节是非常重要的。UNet的这种特点使其非常适合这种任务,因为它可以在恢复图像的同时,确保全局结构和局部细节都得到很好的保留。
以上就是Diffusion里面比较重要的概念的形象理解。如果想要更深刻的理解(手写复现代码)欢迎直接看以下b站DDPM复现视频。(如何觉得质量不错的话,欢迎点赞收藏加关注)
【1.【引言】扩散(diffusion)简介】 https://www.bilibili.com/video/BV1BN41117NJ/?share_source=copy_web&vd_source=c2943614860835ab3609130be342280f
完整课程目录

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢