
点关注,不迷路,用心整理每一篇算法干货~
今天介绍的这篇文章来自华南理工大学,提出了一种基于RNN的长周期时间序列预测模型,取得了优于SOAT Transformer系列模型的效果。

论文标题:SegRNN: Segment Recurrent Neural Network for Long-Term Time Series Forecasting
下载地址:https://arxiv.org/pdf/2308.11200v1.pdf
在长周期时间序列预测任务中,Transformer系列模型占据主导地位,而基于RNN的模型逐渐销声匿迹。其主要原因在于,RNN是串行计算的,长周期预测需要串行迭代多轮,计算复杂度高,并且随着迭代的进行,时间序列的信息不断损失,影响最终预测。在Decoder阶段,RNN的串行方式也会造成误差累积问题。

那么,RNN这种天生适用于时间序列建模的模型架构,真的无法有效应用于长周期时间序列预测吗?这篇文章提出了一种简单的基于RNN的长周期时间序列预测模型,在Encoder阶段,采用切片的方式减少串行数量;在Decoder阶段采用并行多步预测的方式缓解误差累积问题。
传统RNN模型中,以每个时间步为基础单元迭代计算,这种方式在长周期预测会导致过长的迭代路径。为了缓解这个问题,本文借鉴了PatchTST的思路,提出了对时间序列先分片,再输入RNN的方式。
具体来说,首先将时间序列分成多个片段,每个片段经过全连接+激活函数层进行编码,以生成的Embedding作为RNN的输入。RNN的具体模型采用了GRU的计算方式。整体的Encoder结构如下左图所示。

对于Decoder,文中采用了并行预测的方式。以往的RNN在Decoder阶段,经常会以上一个时刻的预测结果作为下一个时刻的输入,存在误差累积问题,且计算效率低。为了解决这个问题,本文直接改成了多步并行预测的方式,将Encoder的编码结果输入到多个MLP层,并行的得到多个时间步的预测结果。
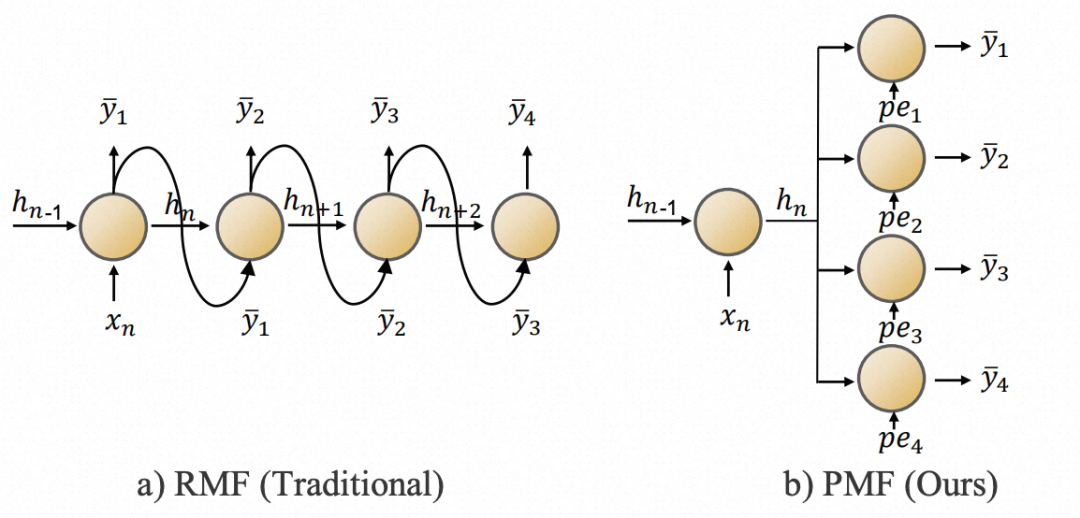
这种方式会导致模型无法感知每个时间步的序列顺序。为了解决这个问题,文中在Decoder部分加入了position embedding。此外,由于采用了多变量独立的建模方式,文中进一步为每个序列增加了channel的position embedding。这两类position embedding,和Encoder的编码结果拼接到一起,接MLP得到预测结果。

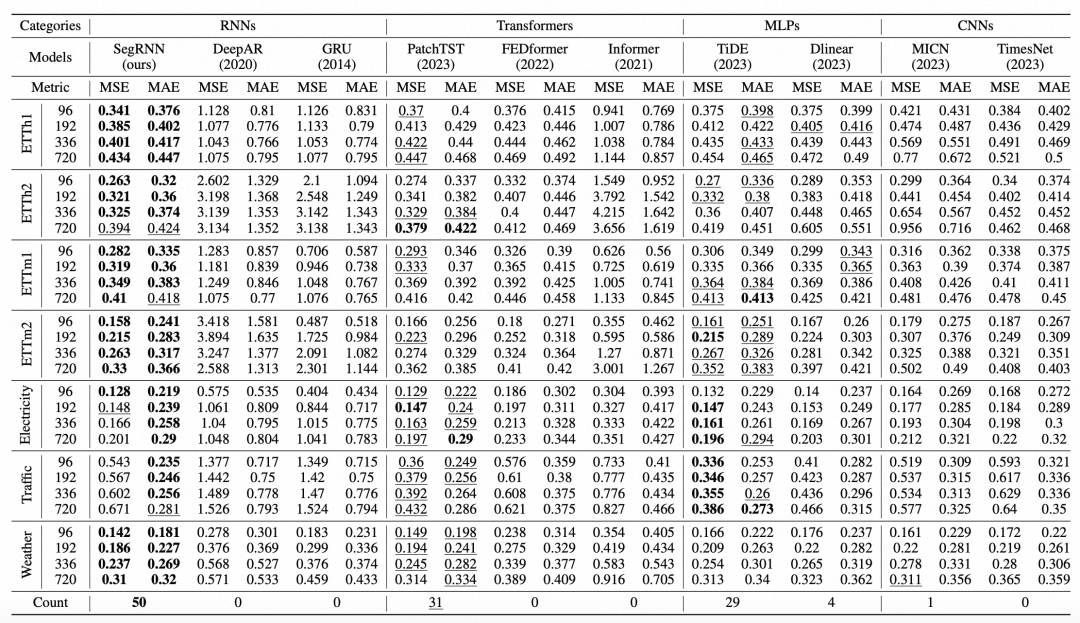
文中对比了本文提出的模型,与RNN类型模型、Transformer类型模型、CNN类型模型、Linear类型模型等4类模型的效果。首先在RNN模型中,本文提出的方法效果要大幅超越DeepAR、GRU这类方法。在于SOTA的Transformer类型模型的对比中,也具有很大的优势。验证了使用RNN也能解决长周期的时间序列预测问题。



加交流群请加微信,备注机构+方向拉群~


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢