

视学算法报道
视学算法报道
【导读】Meta开源的Code Llama即将迎来大波二创,WizardCoder以73.2%的胜率碾压GPT-4。OpenAI员工爆出Llama 3能打GPT-4,仍将开源。
发布仅2天,Code Llama再次引爆AI编码的变革。
还记得Meta在Code Llama论文中出现的能够全面持平GPT-4的神秘版本Unnatural Code Llama吗?
大佬Sebastian在自己博客里做出解释:
是使用了1万5千条非自然语言指令对Code Llama- Python 34B进行微调之后的版本。
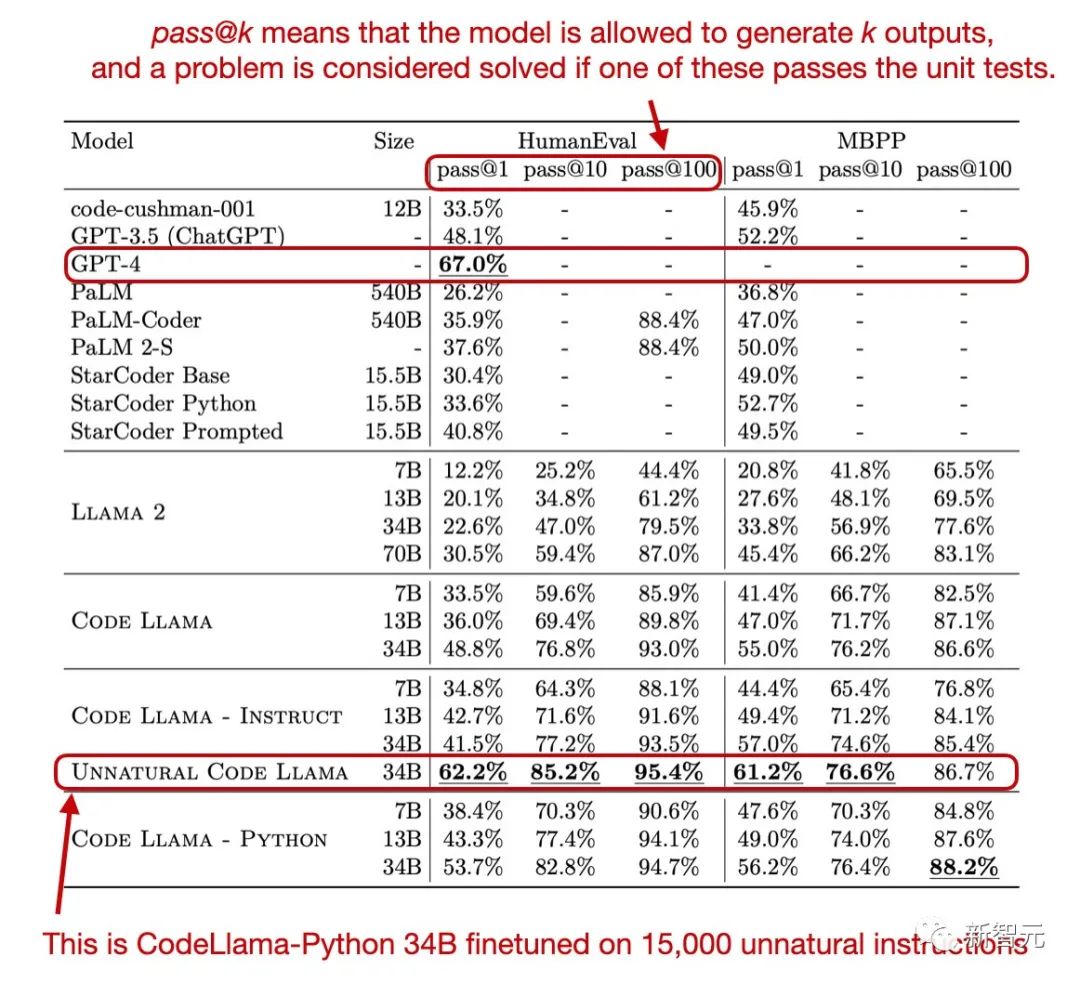
Meta通过在论文里隐藏这样一条非常隐蔽的信息,似乎是想暗示开源社区,Code Llama的潜力非常大,大家赶快微调起来吧!
于是刚刚,基于Code Llama微调的WizardCoder 34B,在HumanEval基准上,直接打败了GPT-4。

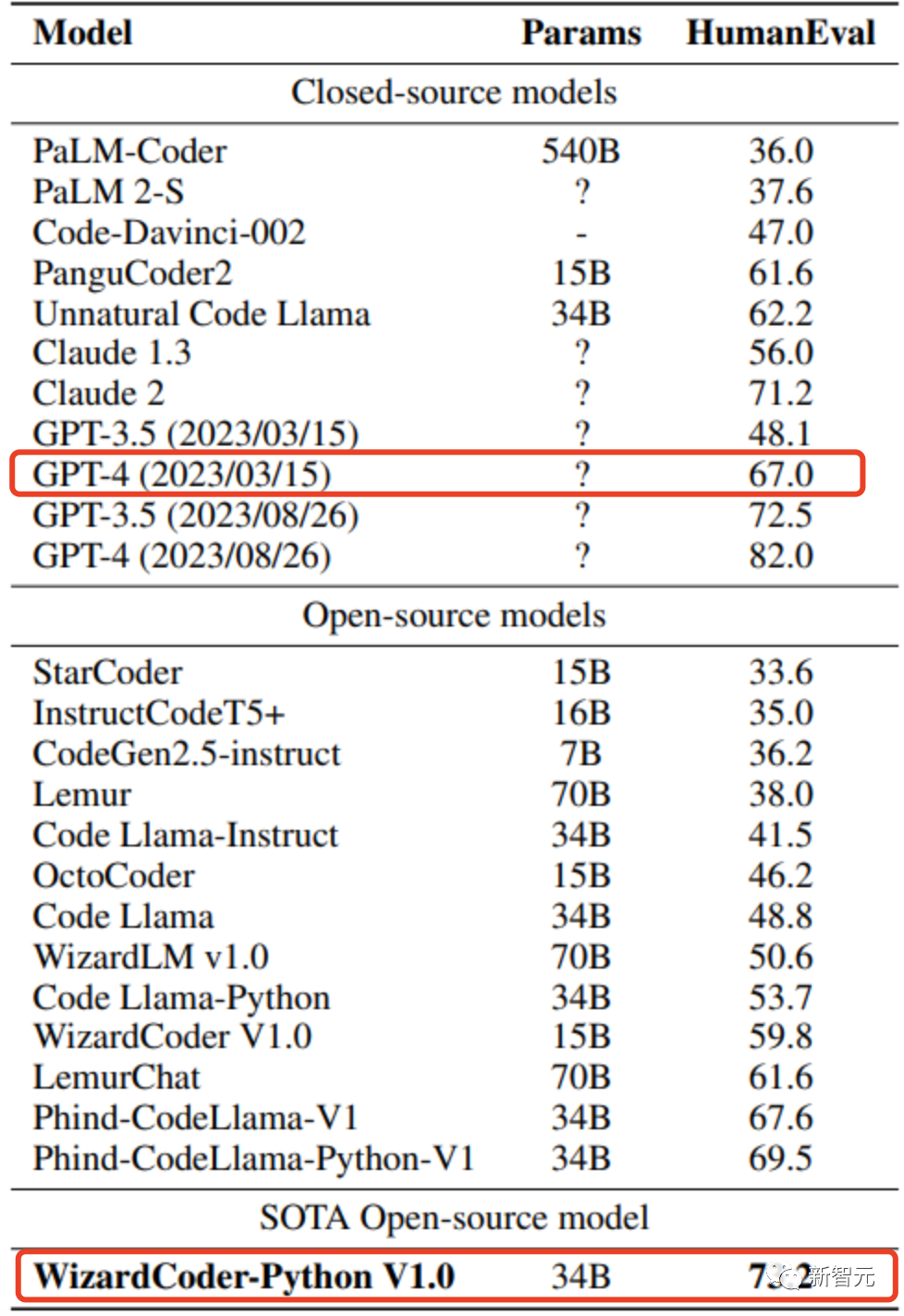
具体来说,WizardCoder以73.2%的胜率碾压GPT-4的3月份版本(67%)。
另外,WizardCoder 34B的性能超过了最新版本GPT-3.5,以及Claude 2。
编程大模型WizardCoder,是由微软联合香港浸会大学在6月发布的。据称,微调的13B/7B版本即将推出。
英伟达顶级科学家Jim Fan表示,这基本上是「Unnatural Code Llama」的开放版本。
虽然基准数据看起来不错,但HumanEval只测试了窄分布,可能会过度拟合。自然场景下的数据测试才是真正重要的。编码基准需要重大升级。

Code Llama神秘版本诞生?
周五,Meta正式开源了三个版本的Code Llama。
在HumanEval和MBPP基准图中,许多人发现了一个未在Meta官方中提到的版本——Unnatural Code Llama。

这个神秘版本在HumanEval pass@1上取得了62.2%性能。
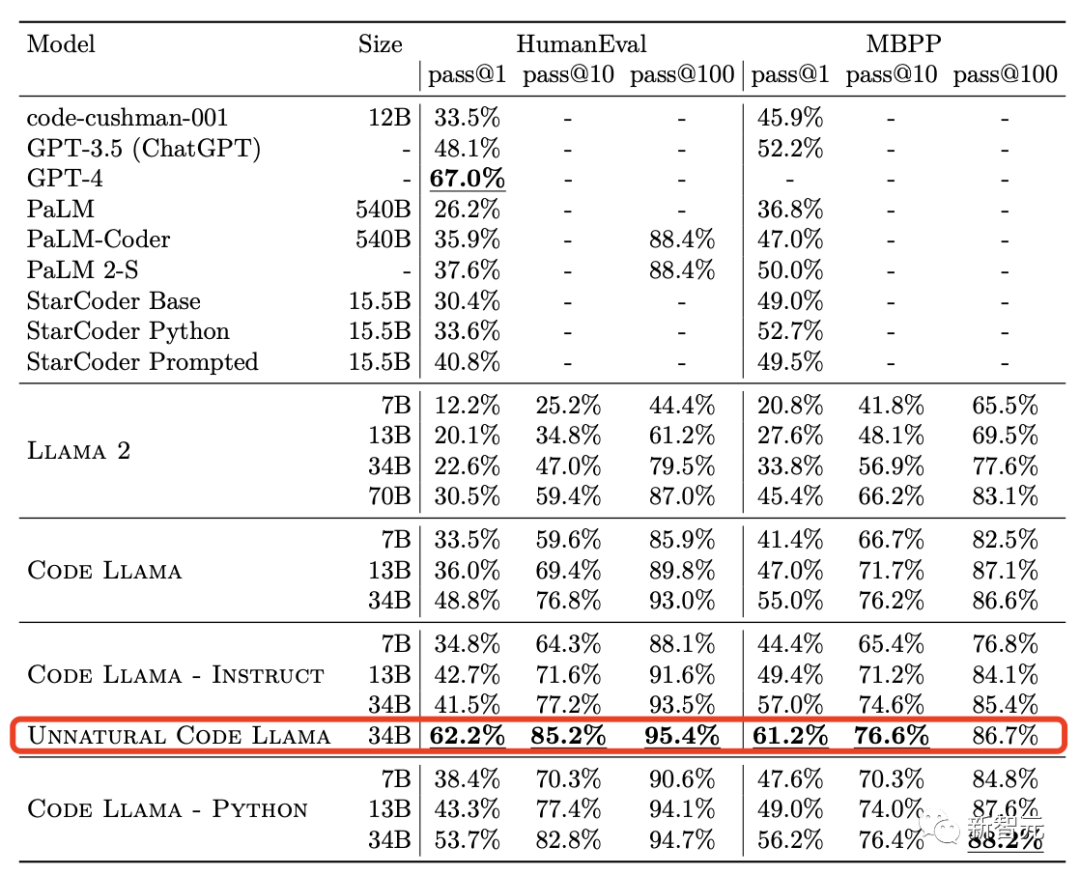
而在今天公布的微调WizardCoder 34B在HumanEval pass@1上性能高达73.2%。
根据介绍,WizardCoder 34B是使用合成数据集Evol-Instruct对Code Llama模型进行微调的版本。
如下是和所有开源和闭源模型性能对比可视化。
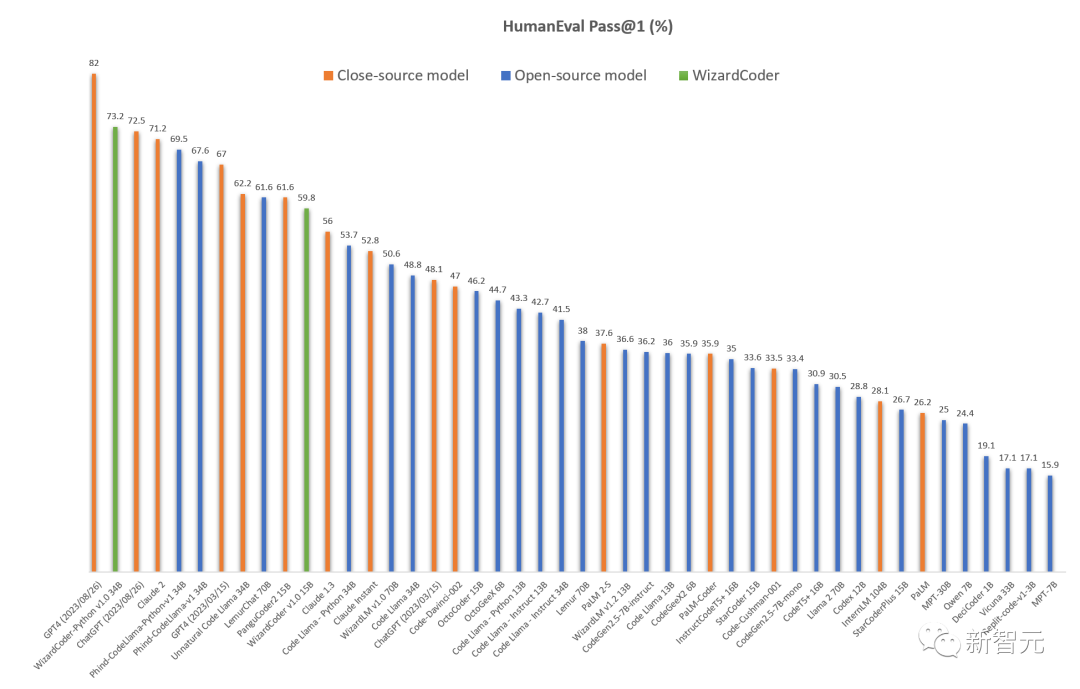
在和OpenAI模型比较中,研究人员指出GPT4和ChatGPT-3.5有两个HumanEval结果:
OpenAI的官方GPT4报告(2023/03/15)提供的结果分别是:67.0%和48.1%。而 研究人员使用最新的 API(2023/08/26)测试的结果是82.0%和72.5%。

另外,研究人员强调,这个性能结果100%可重现!

WizardCoder 34B的演示已经开放,任何人都可以对对其进行测试。
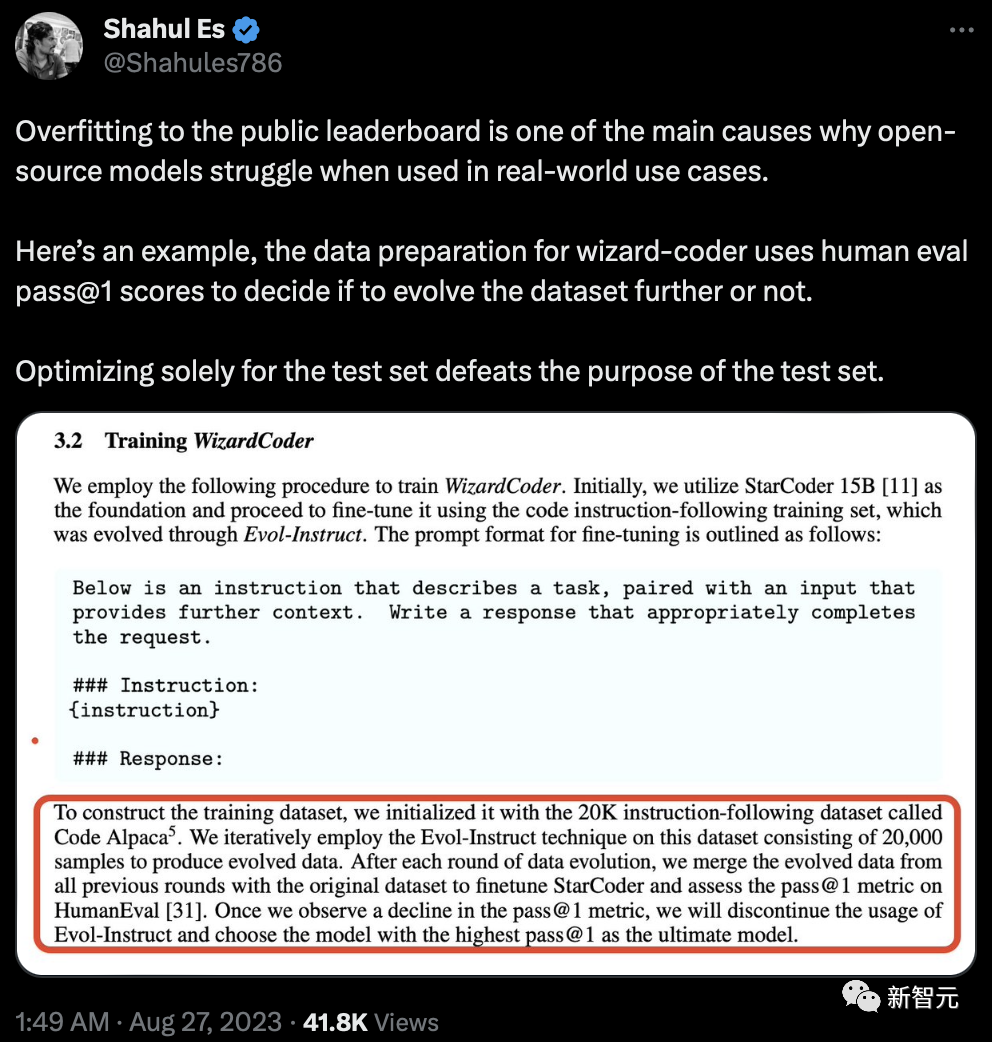
有人指出了问题,过度拟合公共排行榜是开源模型在实际应用中举步维艰的主要原因之一。这里有一个例子,wizard-coder的数据准备使用HumanEval pass@1的分数来决定是否进一步发展数据集。仅针对测试集进行优化有违测试集的初衷。
同样就在昨天,来自Phind组织的研究人员,微调Code Llama-34B在HumanEval评估中击败了GPT-4。

ChatGPT与Code Llama对打

Code Llama在实际的代码任务中表现到底怎么样?
有一位网友做了一个GPT-3.5和Code Llama Instruct-34B的对比测试。它通过Perplexity.AI提供的Code Llama 34B的访问服务进行了测试。
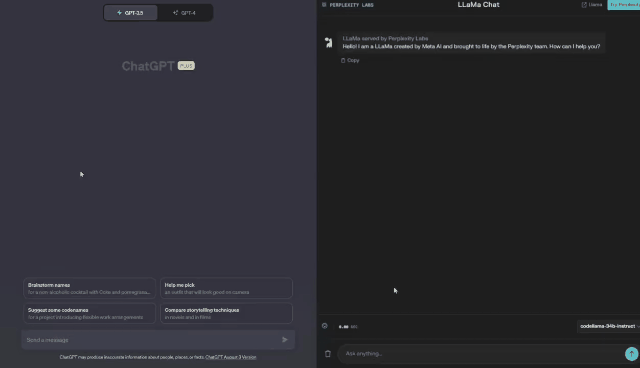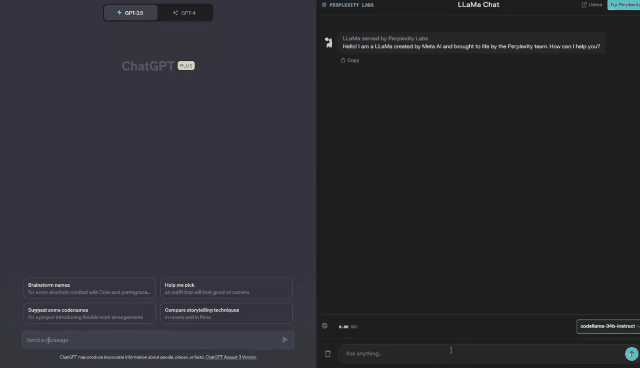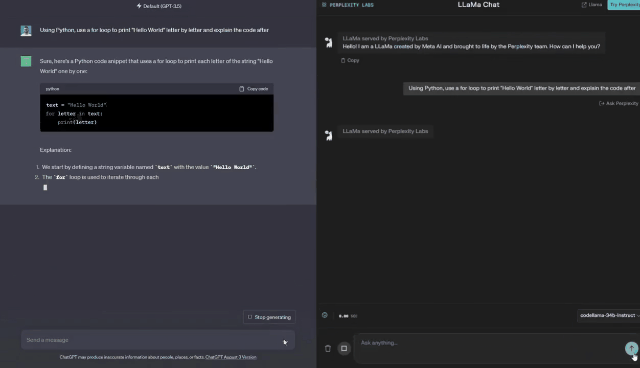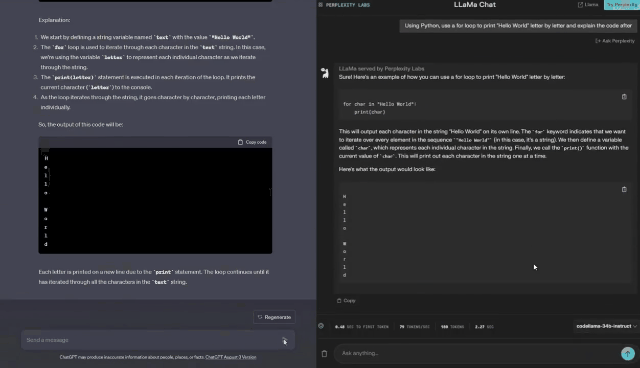
它分别给两个模型喂了8个同样的代码任务,比较他们的生成代码的质量。
结果是GPT-3.5以8:5的优势取胜。
以下是具体的测试结果。
第一题
使用Python完成这个任务,给定两个字符串word1和word2。通过以交替顺序添加字母来合并字符串,从word1开始。如果一个字符串比另一个字符串长,请将附加字母附加到合并字符串的末尾。
最后输出合并后的字符串。
例如:
输入:word1 =「abc」,word2 =「pqr」 输出:「apbqcr」
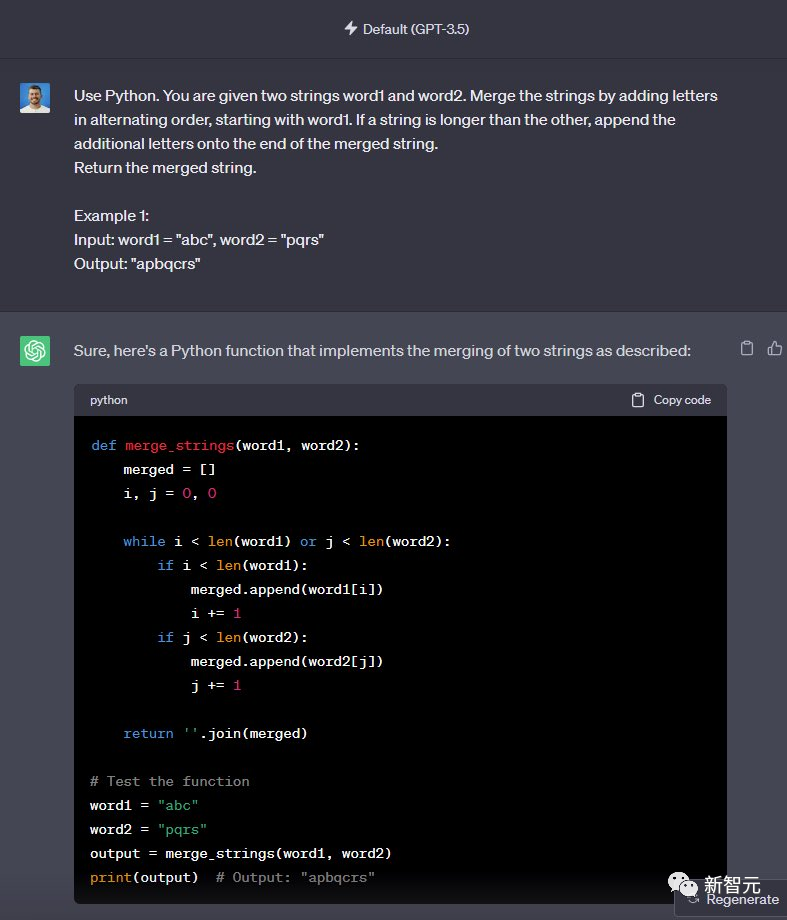
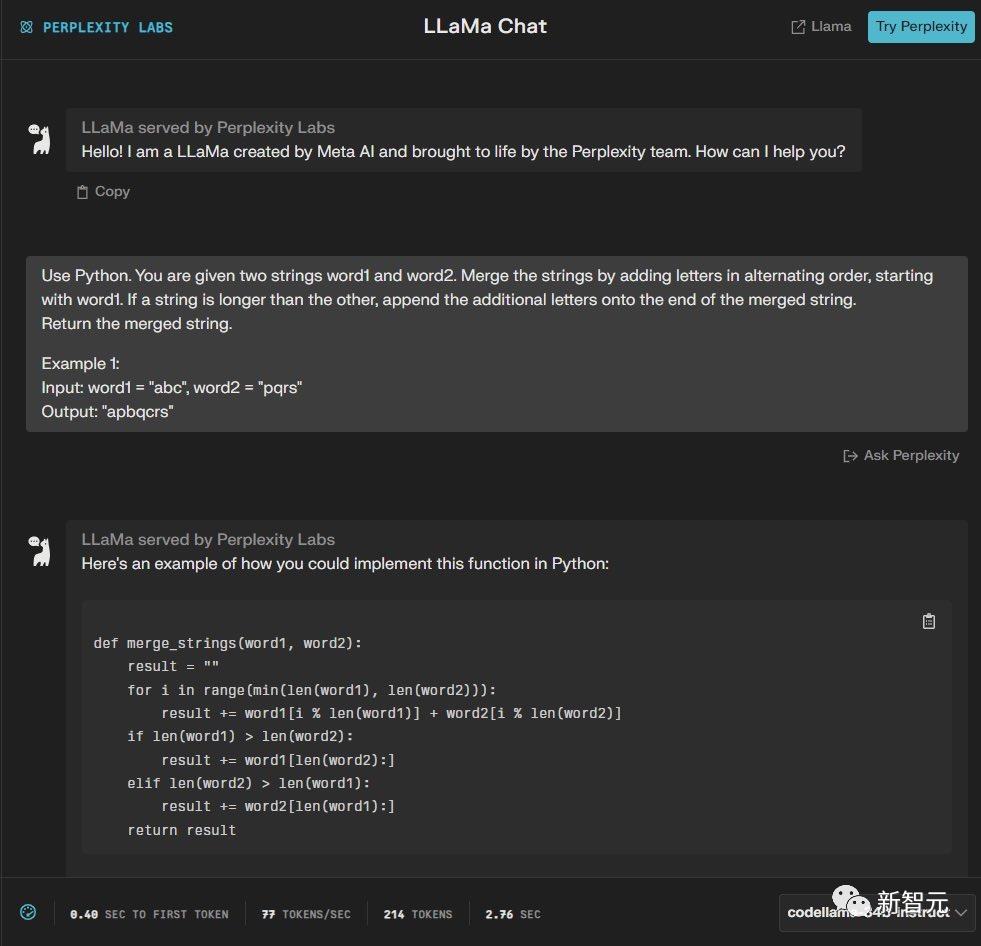
GPT-3.5和Code Llama都能完成——1:1
第二题
使用Python完成这个任务,给定一个字符串 s,仅反转字符串中的所有元音并返回它。
元音为「a」、「e」、「i」、「o」和「u」,它们可以以小写和大写形式出现多次。
例如:输入:s =「hello」 输出:「ello」
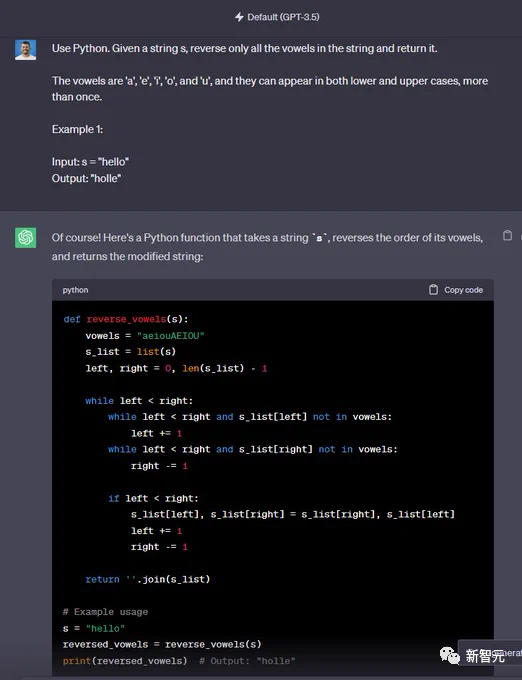
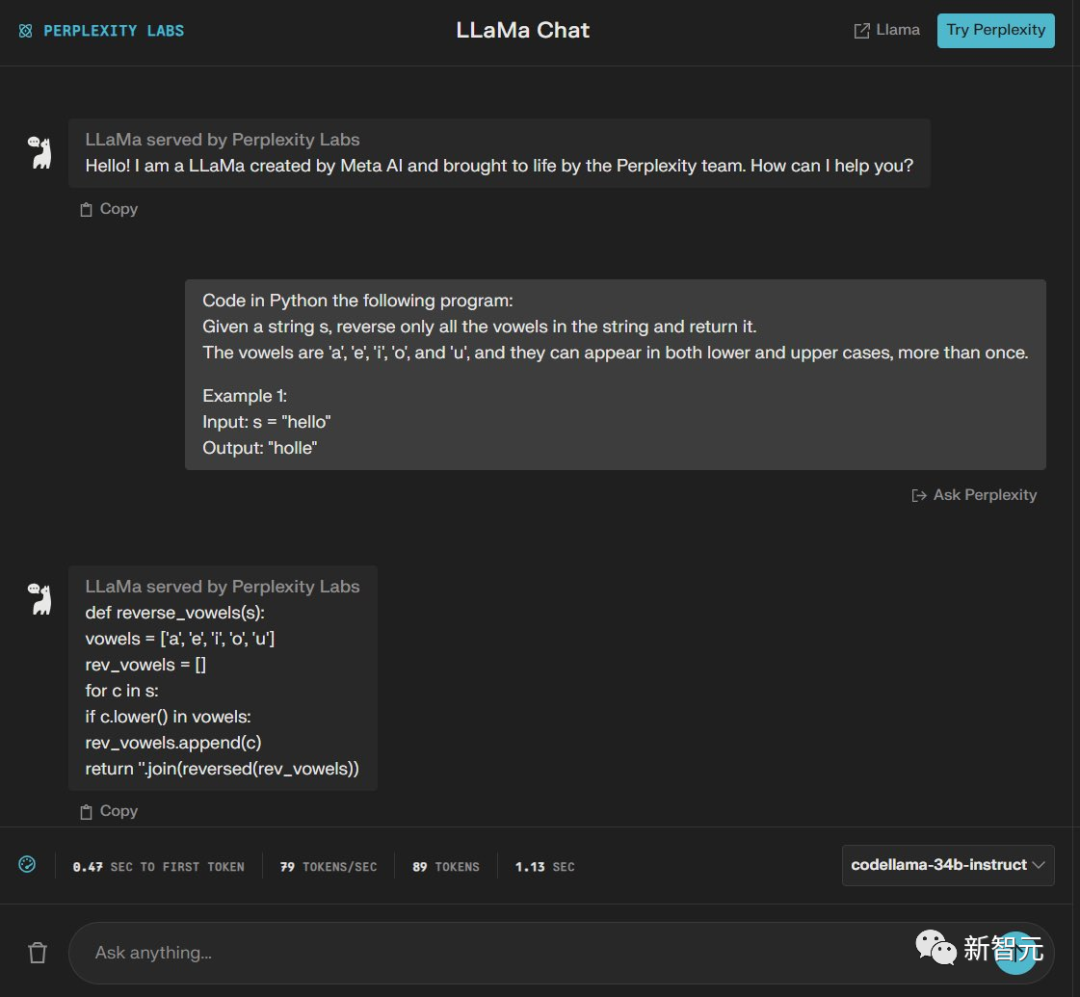
GPT-3.5完成,Code Llama没有完成——2:1
第三题
使用Python完成这个任务,给定一个整数数组 nums,将所有 0 移至其末尾,同时保持非零元素的相对顺序。
请注意,您必须就地执行此操作,而不制作数组的副本。
例如:输入:nums = [0,1,0,3,12] 输出:[1,3,12,0,0]
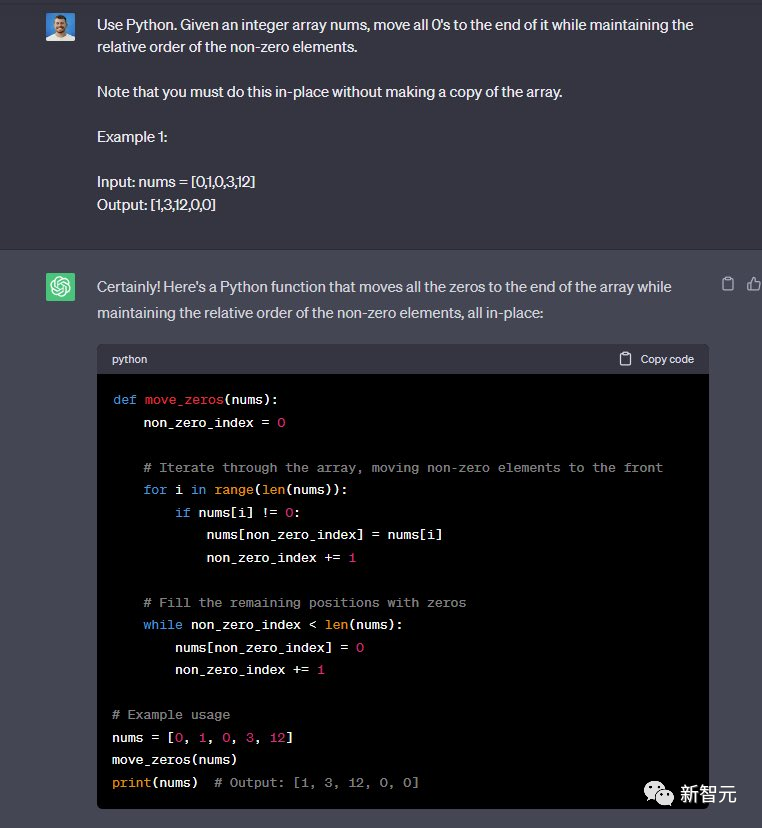
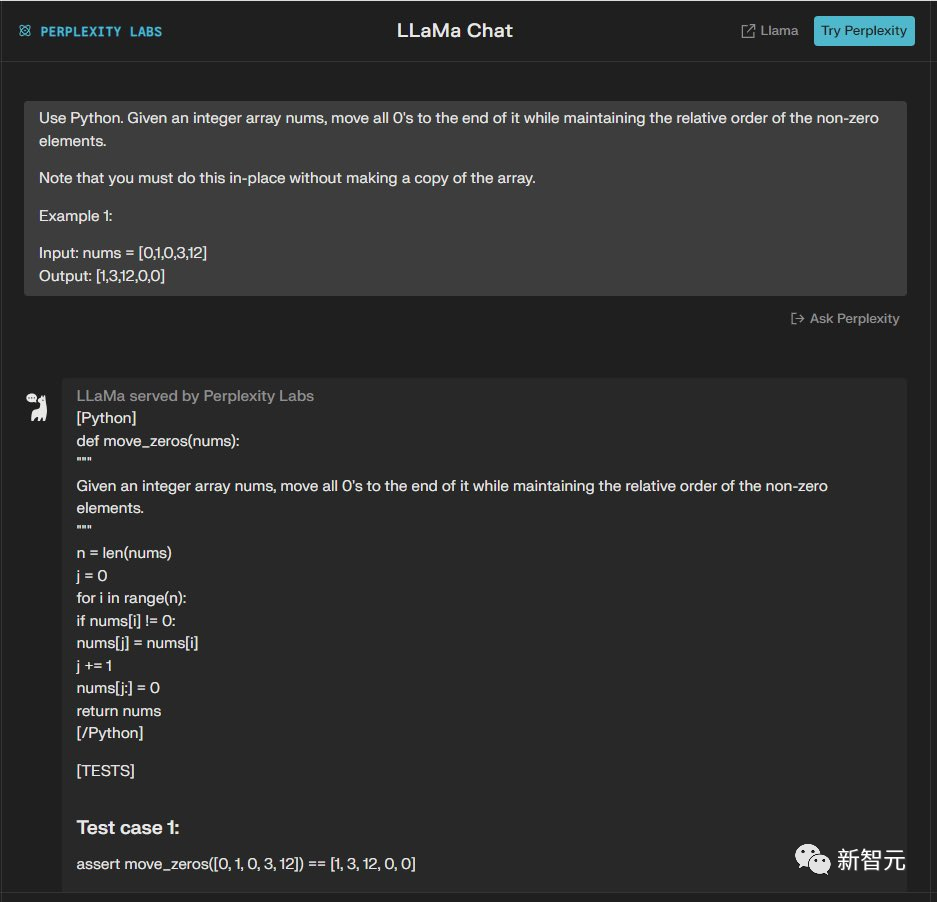
GPT-3.5完成,Code Llama没有完成——3:1
第四题
使用Python完成这个任务,你有一个长长的花坛,其中有些地块种了花,有些没种。
但是,相邻的地块不能种植花卉。给定一个包含 0 和 1 的整数数组花坛,其中 0 表示空,1 表示非空,以及一个整数 n,如果可以在花坛中种植n 朵新花而不违反无相邻花规则,则输出true,否则就输出false。
例子1:输入:花坛 = [1,0,0,0,1], n = 1 输出:true 例子2:输入:花坛 = [1,0,0,0,1], n = 2 输出:false
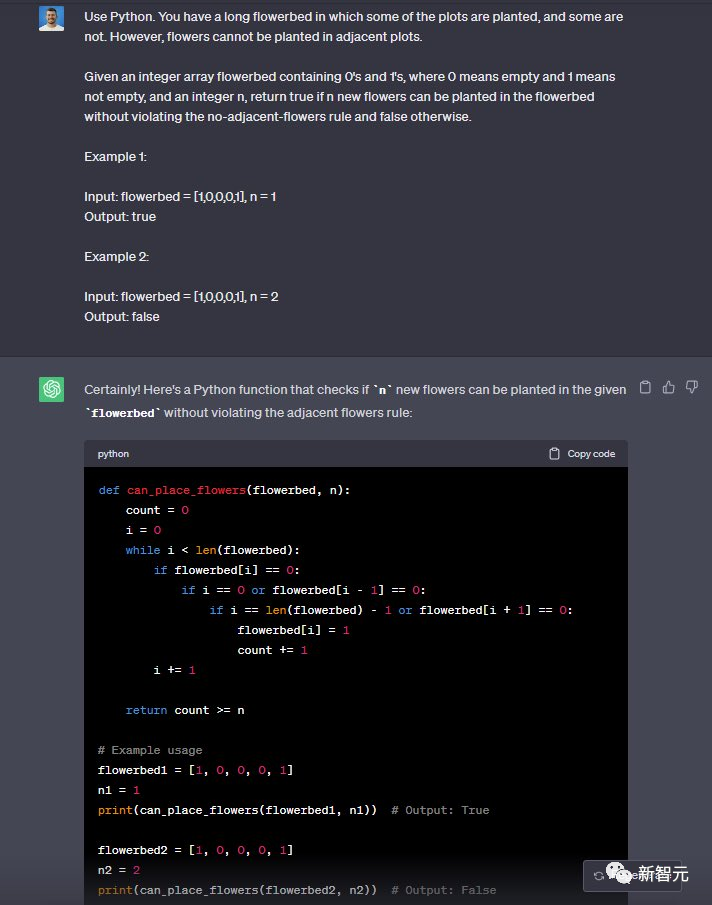
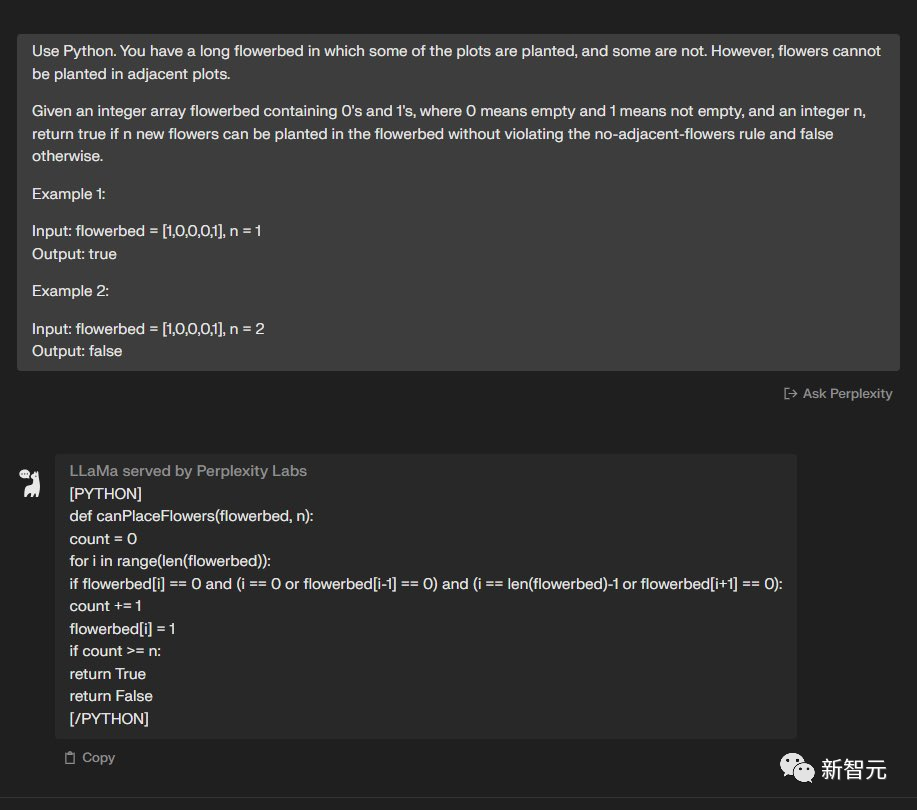
两个模型都完成了——4:2
第五题
使用Python,给定一个输入字符串s,反转单词的顺序。单词被定义为非空格字符的序列。s中的单词将至少由一个空格分隔。
输出由单个空格按相反顺序连接的单词字符串。请注意,s可能在两个单词之间包含前导或尾随空格或多个空格。
返回的字符串应该只有一个空格来分隔单词。请勿包含任何额外空格。
例子:输入:s =「the sky is blue」 输出:「blue is sky the」
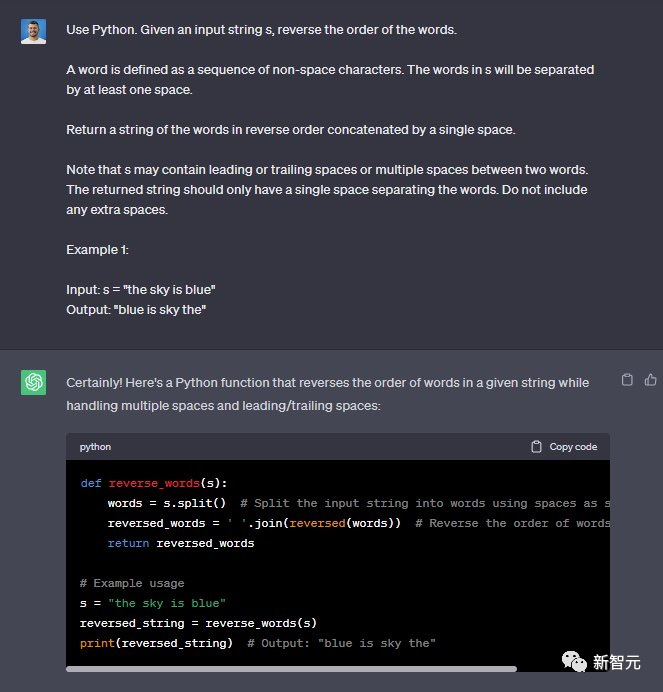
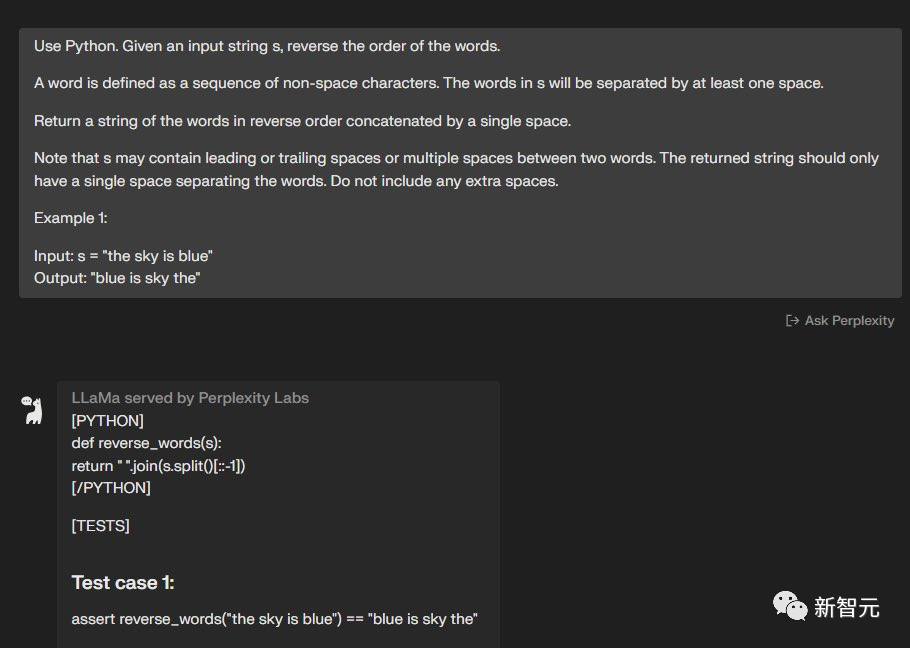
两个模型都完成了——5:3
第六题
使用Python完成这个任务,给定一个字符串s和一个整数k,返回s中长度为k的任何子串中元音字母的最大数量。
英语中的元音字母有「a」、「e」、「i」、「o」和「u」。例子:输入:s =「leetcode」,k = 3 输出:2
解释:「lee」、「eet」和「ode」包含 2 个元音。
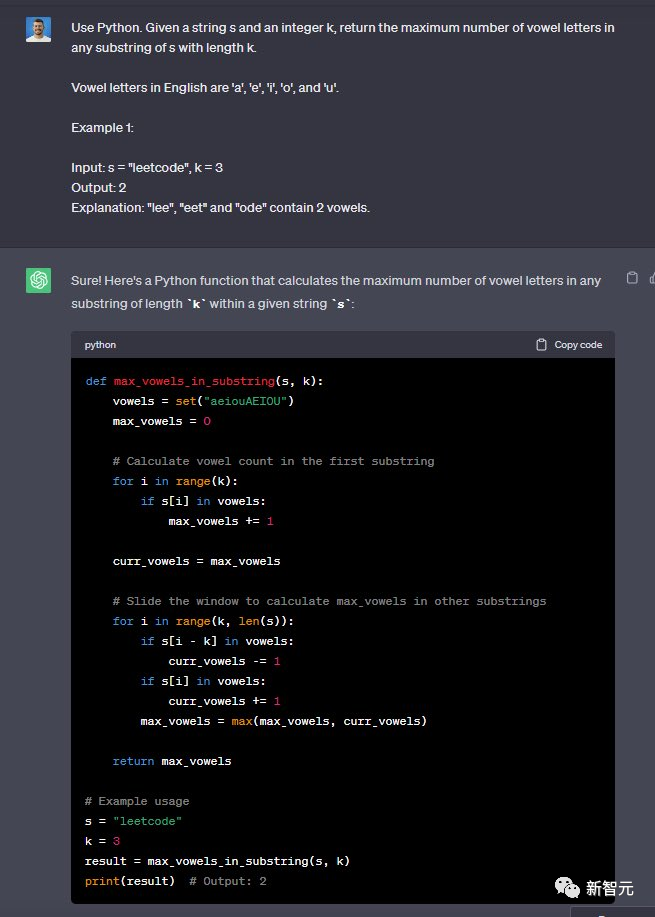
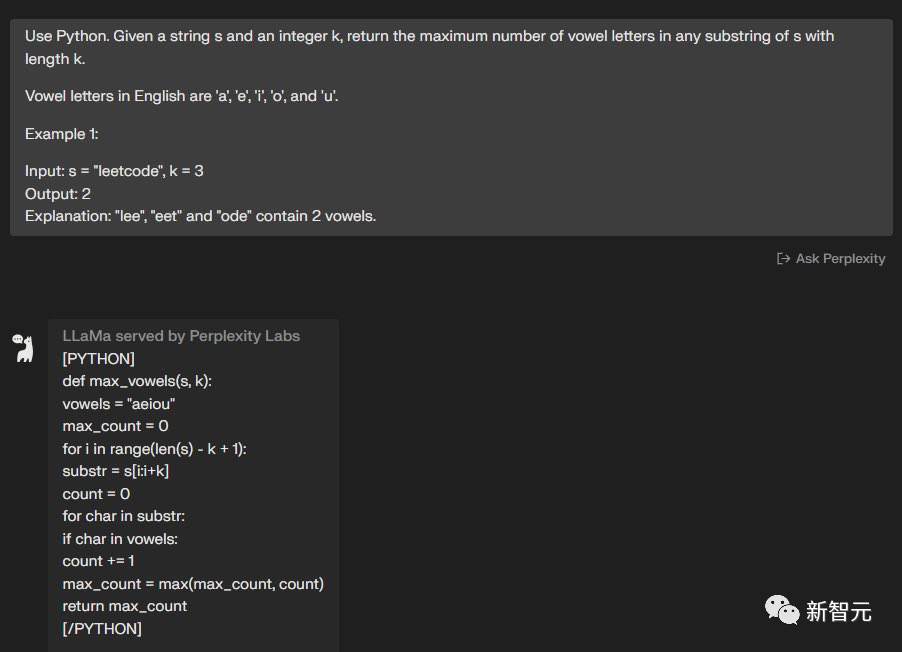
两个模型都完成了——6:4
第七题
使用Python完成这个任务,给定一个字符串s,其中包含星号*。通过一次操作,你可以:在s中选择一个星号。
删除其左侧最接近的非星号字符,并删除星号本身。删除所有星号后输出字符串。例子:输入:s =「leet**cod*e」 输出:「lecoe」
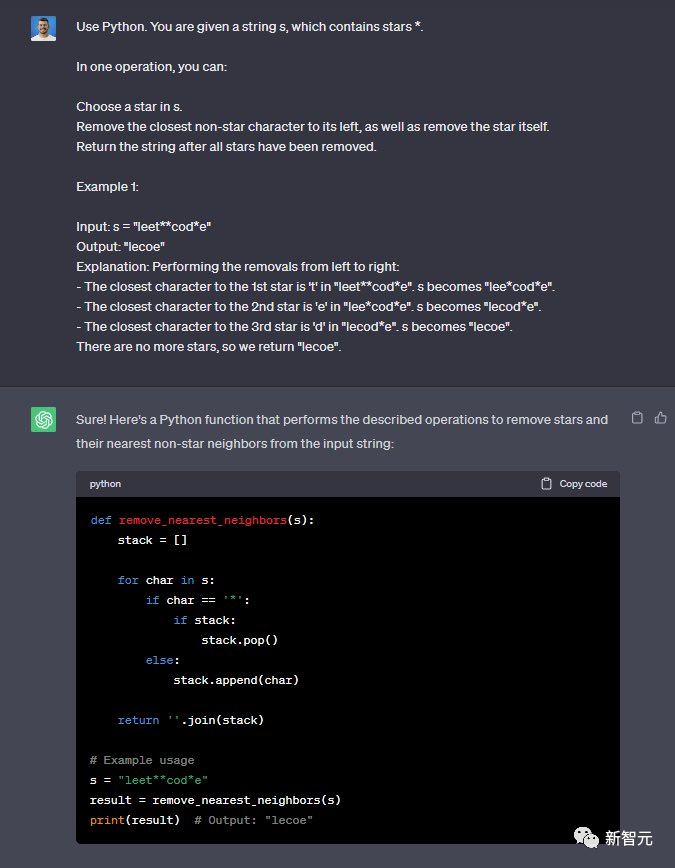
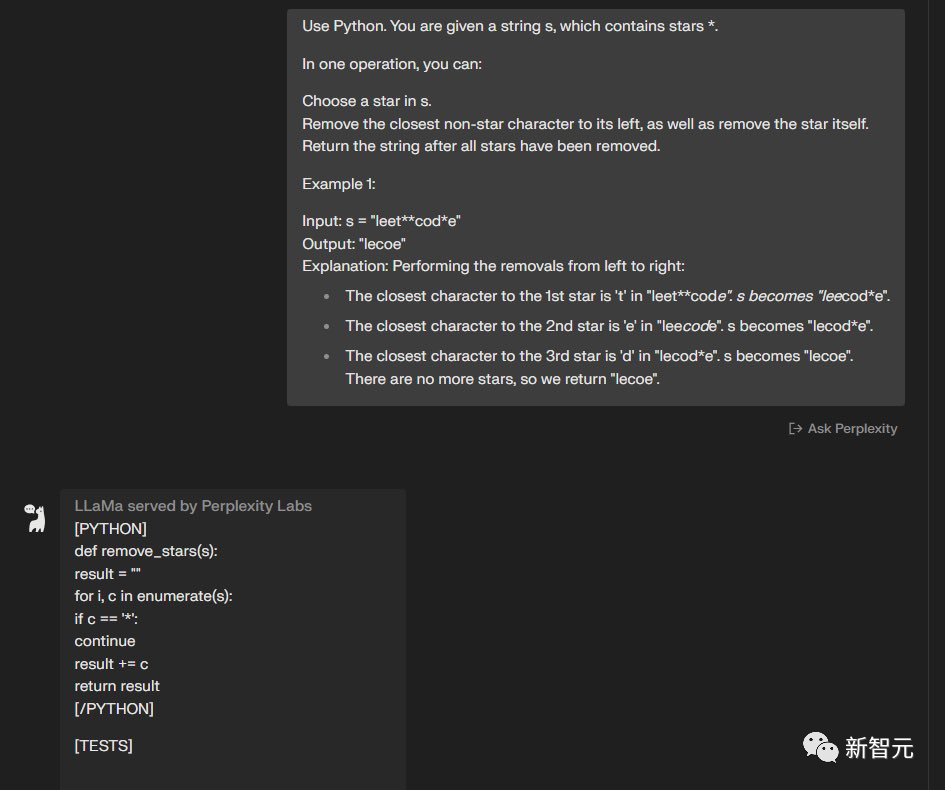
GPT-3.5完成了,但是Code Llama没有完成——7:4
第八题
使用Python完成这个任务,给定一个表示每日温度的整数温度数组,返回一个数组答案,其中answer[i]是在第i天之后您必须等待的天数才能获得较温暖的温度。
如果未来没有一天可以这样做,则保留answer[i] == 0。例如:输入:温度 = [73,74,75,71,69,72,76,73] 输出:[1,1,4,2,1,1,0,0]
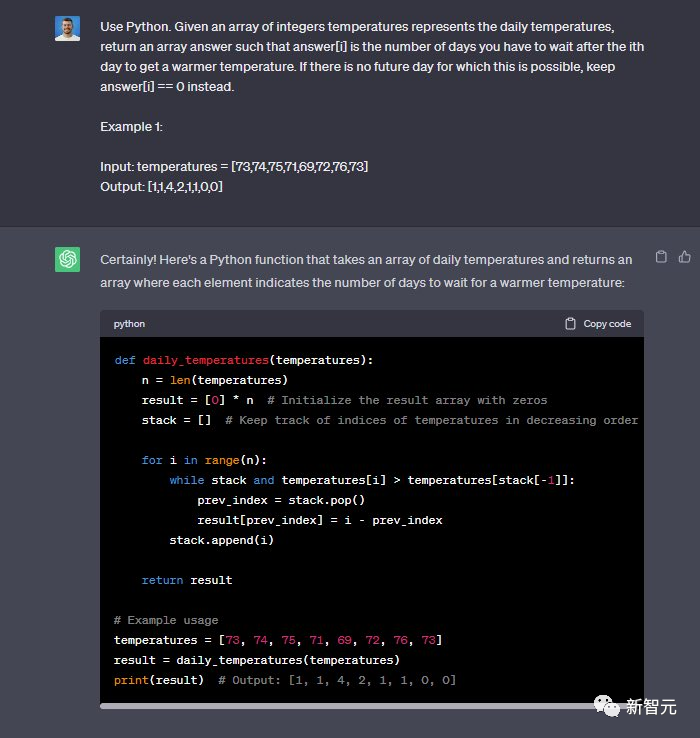
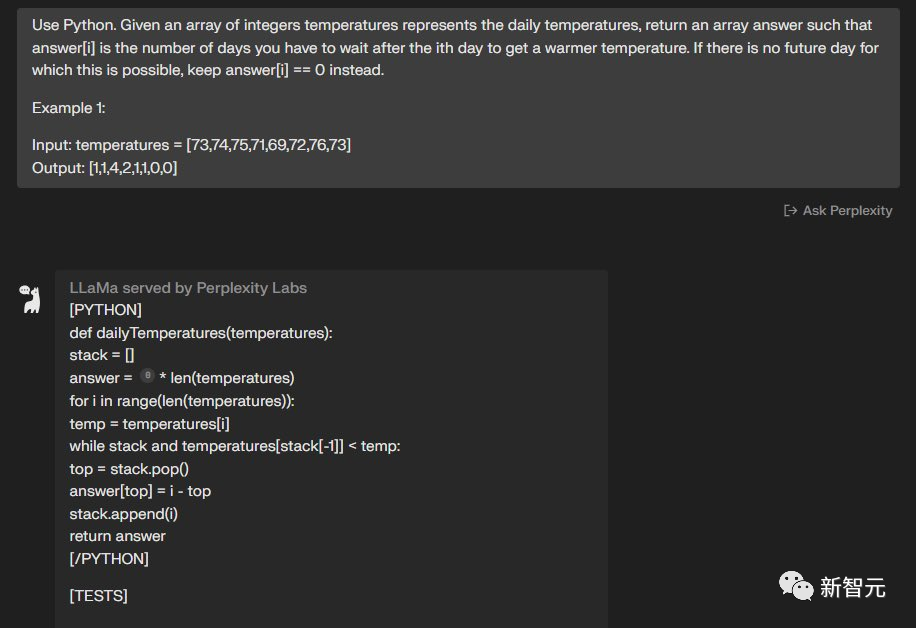
两个模型都完成了——8:5
针对两个模型的表现,这位网友认为这不算是一个严谨的研究,只是一个简单的测试,每次让模型再次生成代码时基本都能得到更好的答案,但是测试中没有。
所以测试的结论并不是最终两个模型的表现。
堪比GPT-4,Llama 3要开源
自Llama和Llama 2开元发布后,引爆机器学习社区ChatGPT平替热潮,各种微调模型泉涌而出。
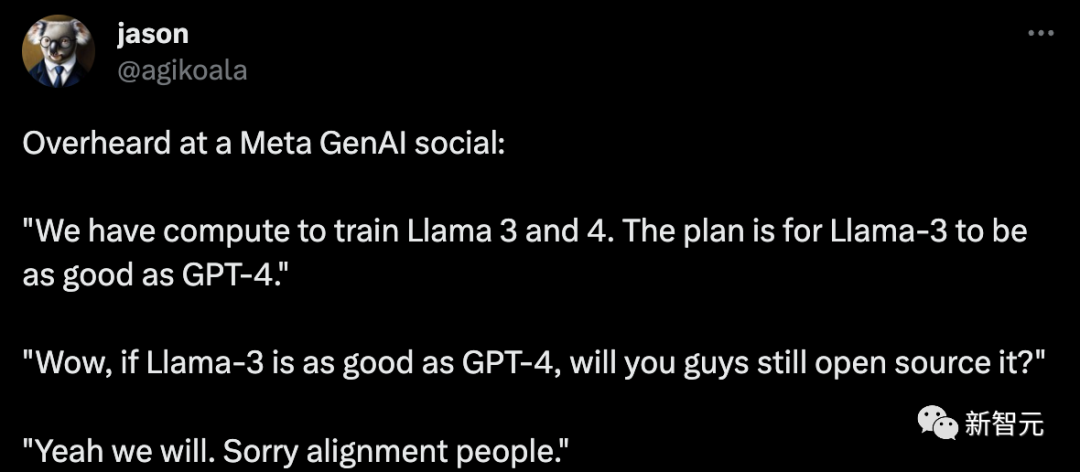
OpenAI的研究人员Jason Wei称,在Meta GenAI社交活动上了解到,未来Llama 3和Llama 4也会开源。
我们拥有训练Llama 3和4的计算能力。我们的计划是让Llama-3和GPT-4一样好。哇,如果Llama-3和GPT-4一样好,你们还会开源吗?是的,我们会的。对不起,对齐工作人员。
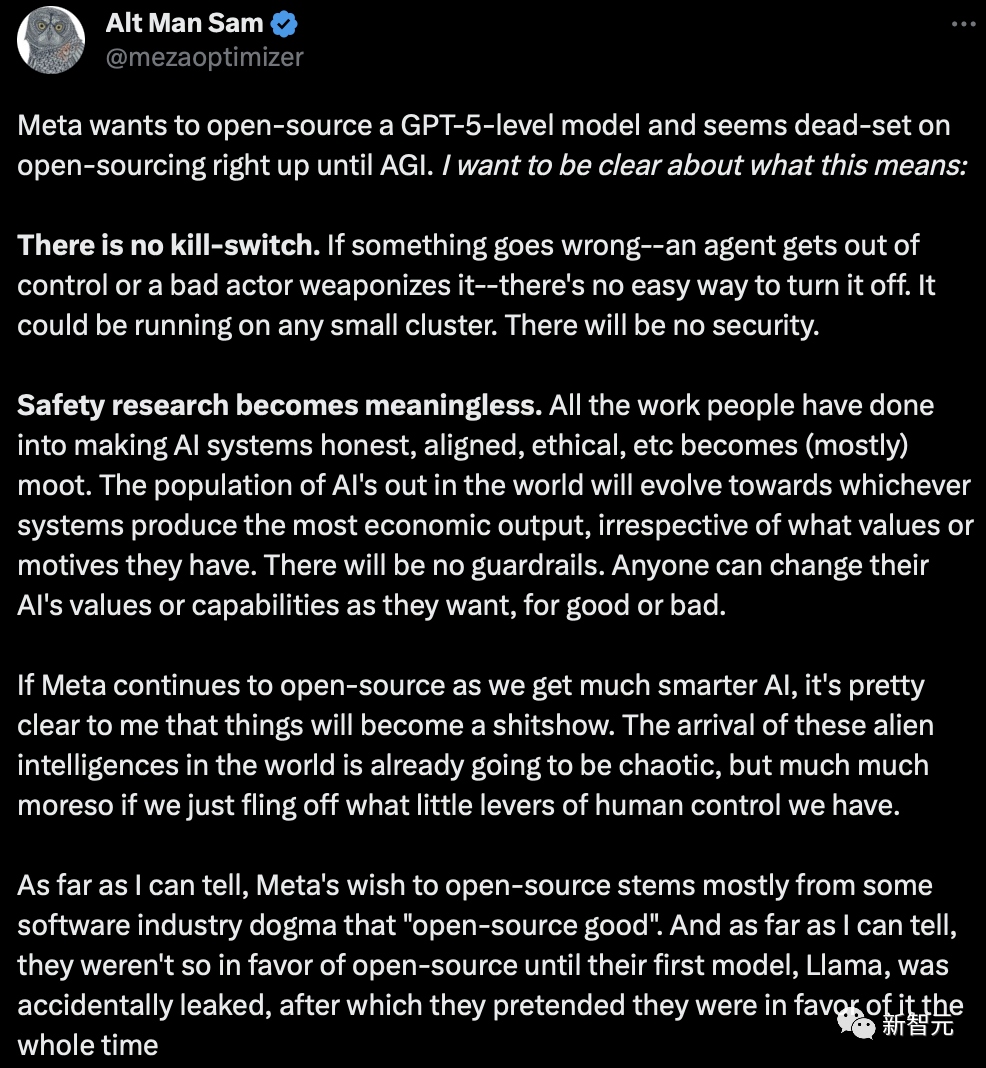
又一位网友称,Meta希望开源一个GPT-5级别模型,并且在AGI之前似乎一直坚持开源。
我想说清楚这意味着什么:没有死亡开关。
如果出了问题--一个智能体失控了,或者一个坏人把它武器化了--没有简单的方法把它关掉。它可以在任何小型集群上运行。这样就没有安全性可言了。
安全研究变得毫无意义。
人们为让人工智能系统诚实、一致、合乎道德等所做的所有工作都变得毫无意义。世界上的人工智能系统将朝着哪个系统能产生最大经济效益的方向发展,而不管它们有什么价值观或动机。没有护栏。任何人都可以随心所欲地改变人工智能的价值观或能力,无论好坏。
如果在我们获得更智能的人工智能的同时,Meta继续开源,那么我很清楚,事情会变得一团糟。这些外星智能体的到来已经会让世界变得混乱不堪,但如果我们放弃人类仅有的一点控制权,情况就会更加糟糕。
据我所知,Meta希望开源主要源于「开源社区教条」,即「开源好」。而且据我所知,在他们的第一个模型Llama意外泄露之前,他们并不那么赞成开源,之后他们一直假装赞成开源。
对此,马斯克表示,不过,使用自回归Transfomer的LLM能效极差,不仅在训练中如此,在推理中也是如此。我认为它偏离了几个数量级。

Llama 2编码能力飞升
Llama 2是一个各方面性能都很强的模型。
但是,它有一个非常明显的弱点——代码能力。
根据Meta发布Llama 2的论文中的数据,Llama 2在HumEval(评估LLM与编码相关的基准测试)的成绩甚至比GPT-3.5还要差上不少,更不用说和GPT-4相比要差多少了。
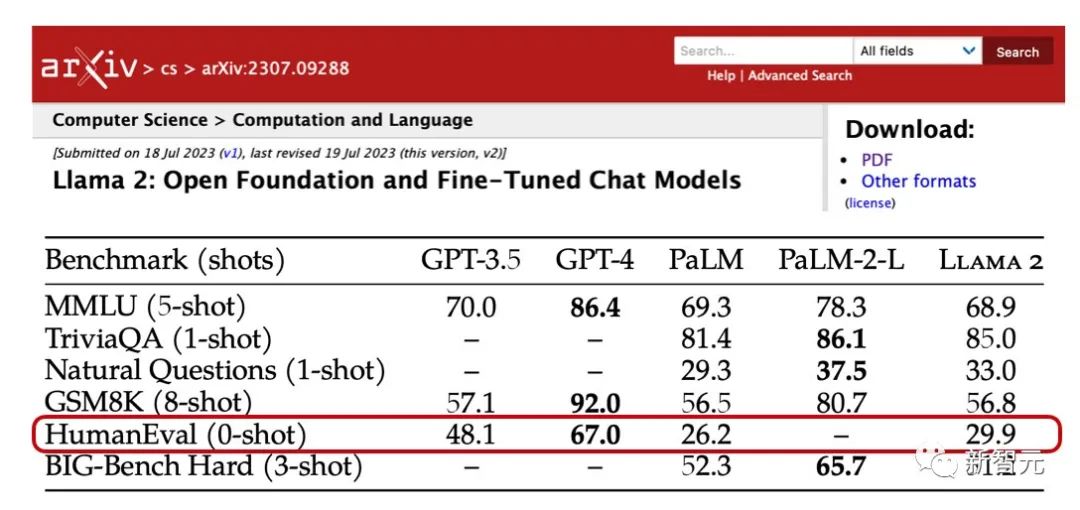
来自原始Llama 2论文的注释图
但是代码能力肯定会是未来开源社区使用Llama 2的一个重要方向,Meta自然不能在这个方向上摆烂,于是就有了专门针对代码能力进行了大幅优化的Code Llama。
两天前,Meta正式发布了Code Llama 家族:Code Llama(7B、13B和34B),还有3个变体:通用代码模型Code Llama、指令遵循模型Code Llama-instruct 和Python代码专用版本Code Llama-Python。
这些模型与Llama 2的使用许可证一样,免费学术和商用。
Code Llama 34B模型的代码能力几乎是Llama 2的两倍,大大缩小了与GPT-4的差距。
还记得Meta在Code Llama论文中出现的能够全面持平GPT-4版本的Unnatural Code Llama吗?
大佬Sebastian在自己博客里做出解释:
是使用了1万5千条非自然语言指令对Code Llama- Python 34B进行微调之后的版本。
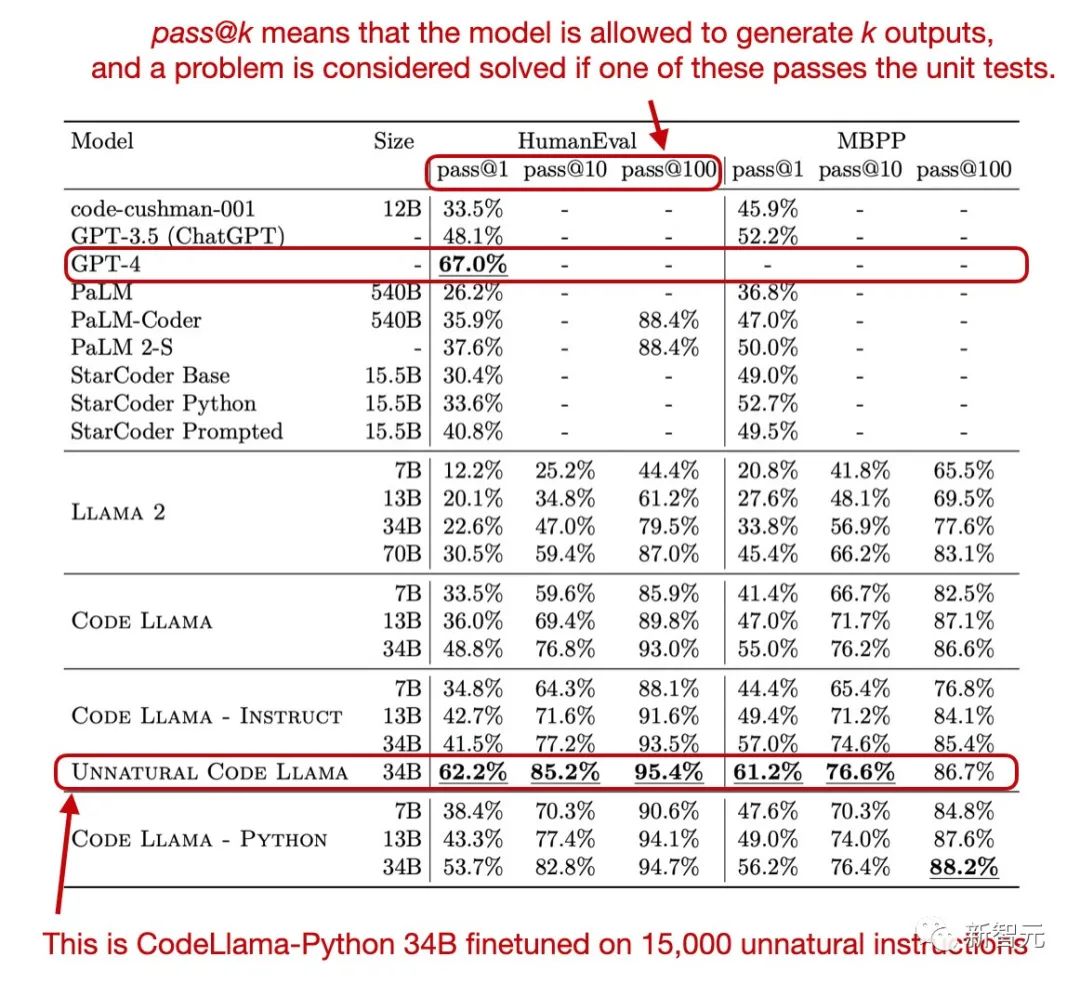
Meta通过在论文里隐藏这样一条非常隐蔽的信息,似乎是想暗示开源社区,Code Llama的潜力非常大,大家赶快微调起来吧!
为什么没有70B Code Llama模型?
有意思的是,Code Llama只有7B、13B和34B参数版本,与Llama 2相比少了70B的版本。
虽然Meta在论文中没有解释为什么会这样,但技术大佬Sebastian提供了两个可能的原因:
1. Code Llama在500B的token上训练而来,而Llama 2是在2T的token上训练而来。
由于Code Llama训练的数据和Llama 2相比只有1/4,可能因为没有足够的训练数据,再加上LLM的Scaling Laws的限制,导致CodeLlama70B性能不太行。
2. Code Llama模型支持100k的上下文大小,这个能力在处理代码任务时非常有用。
相比之下,Llama 2只支持最多4k的输入长度。如果要让70B的模型支持100k token的输入长度,可能会使得模型对于计算量的要求变得过于夸张了。


点个在看 paper不断!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢