
导语:作为人工智能「行为主义」学派的代表性技术,强化学习近年来被成功应用于学术研究和工业实践。然而,相较于传统的监督学习,强化学习的训练仍然面临着诸多挑战。近期,伯克利人工智能实验室(BAIR)研究人员从优化和动态规划的角度回顾了传统强化学习的研究方法,并讨论了如何从监督学习的角度改进强化学习的训练过程。作者分别为卡内基梅隆大学博士生Ben Eysenbach、加州大学伯克利分校伯克利人工智能研究实验室博士生Aviral Kumar以及加州大学伯克利分校博士生Abhishek Gupta。
编译:智源社区 熊宇轩
「优化」和「动态规划」是强化学习(RL)研究中最常见的研究视角。通常,将计算不可微的期望奖励目标函数的方法(例如,「REINFORCE」技巧)归类到优化角度,将采用「时间差分学习」(TD-learning)或「Q 学习」的方法归为动态规划方法。尽管这些方法在近年来取得了很大的成功,但将这些方法应用于新问题仍非常具有挑战性。相反,深度监督学习的发展则非常成功,因此,我们不禁要问:能否将监督学习用于执行强化学习?
本文基于强化学习可被视为对「优质数据」进行监督学习的思想,讨论了强化学习的思维模型。
强化学习之所以面临着较大的挑战,是因为除非我们采用的是「模仿学习」,否则获取「优质数据」实际上是非常具有挑战性的。因此,强化学习可被视为对策略和数据的联合优化问题。从这种「监督学习」的视角来看,许多强化学习算法可以被视为寻找优质数据与对该数据进行监督学习之间的交替。这使得在多任务的情况下,或者其它可以被转化为易于获取「优质数据」的问题中,寻找「优质数据」要容易得多。事实上,本文重在讨论如何将「hindsight relabeling」和「逆强化学习」等技术视为优化数据。
首先,我们将回顾关于强化学习的两种常见观点,即优化和动态规划。之后,我们将深入探讨强化学习的监督学习视角的正式定义。
常见的强化学习研究视角
两种最主要的强化学习研究视角。
视角1:优化
从优化的视角来看,我们可以将强化学习看作优化不可微函数的一种特例。不妨回想一下,奖励的期望是策略 π_θ关于参数 θ 的函数:
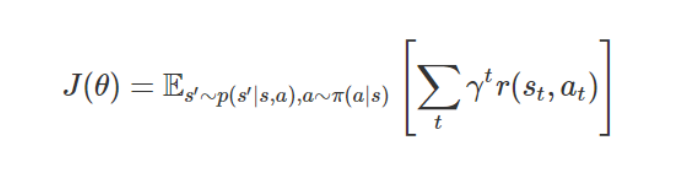
该函数十分复杂,并且由于它同时取决于策略选取的动作和环境的动力学条件,它通常是不可微且未知的。尽管我们可以使用「REINFORCE」技巧来估算梯度,但该梯度取决于策略参数和策略数据,是通过运行当前策略从模拟器生成的。
视角 2:动态规划
从动态规划的角度来看,最优控制是在每一步上选取正确动作的问题。在已知动力学条件的离散情况下,我们可以精确地解决此动态规划问题。例如,「Q-学习」通过迭代以下更新来估计「状态-动作」值 Q(s, a):
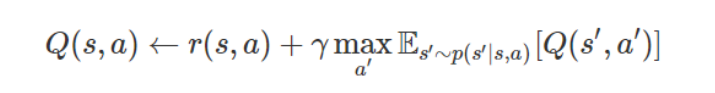
在连续空间或具有大量状态空间和动作空间的情况下,可以通过使用一种函数近似器(例如,一种神经网络)表征 Q 函数并且最小化时间差分误差(TD error,上述公式中左右两侧部分的平方差),从而近似动态规划:
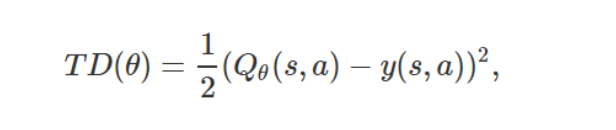
其中,时间差分目标(TD target)为
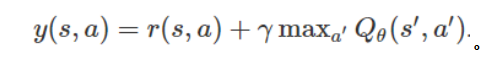 请注意,这是 Q 函数的一种损失函数,而不是策略的损失函数。这种方法可以使我们使用任何类型的数据来优化Q函数,从而避免了对「优质数据」的需求,但是该方法也存在一些困难的优化问题,并且可能会分散或收敛到较差的的解上,并且很难被应用到新的问题上。
请注意,这是 Q 函数的一种损失函数,而不是策略的损失函数。这种方法可以使我们使用任何类型的数据来优化Q函数,从而避免了对「优质数据」的需求,但是该方法也存在一些困难的优化问题,并且可能会分散或收敛到较差的的解上,并且很难被应用到新的问题上。
这种方法可以使我们使用任何类型的数据来优化Q函数,从而避免了对「优质数据」的需求,但是该方法也存在一些困难的优化问题,并且可能会分散或收敛到较差的的解上,并且很难被应用到新的问题上。
监督学习视角的强化学习
下面,我们将讨论另一种强化学习的思维模型,其主要思想是,将强化学习视为策略和经验上的联合优化问题:同时找到「优质数据」和「优质策略」。 直观地说,我们希望「优质数据」具备以下性质:
(1)获得高的奖励 (2)充分探索环境 (3)至少对我们的策略有表征能力。
我们可以简单地将「优质策略」定义为可能产生「优质数据」的策略。
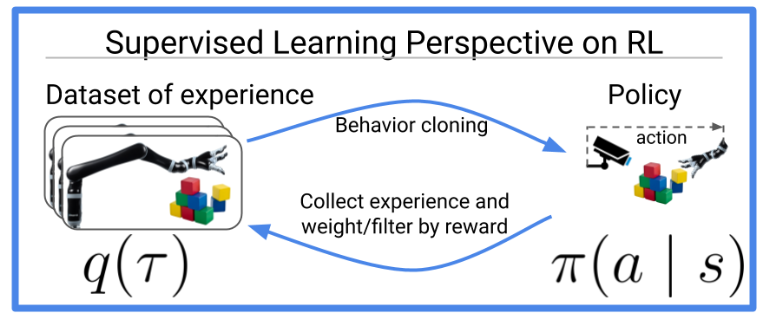 图1:许多以前的强化学习算法和新的强化学习算法可以被认为在优化后的数据上进行「行为克隆」(即监督学习)。本文将这一思路拓展到多任务视角下的工作展开讨论,在该环境下,我们实际上可以更容易地优化数据。
图1:许多以前的强化学习算法和新的强化学习算法可以被认为在优化后的数据上进行「行为克隆」(即监督学习)。本文将这一思路拓展到多任务视角下的工作展开讨论,在该环境下,我们实际上可以更容易地优化数据。
将「优质数据」转化为「优质策略」较为容易,只需要进行监督学习!反过来,将「优质策略」转化为「优质数据」则稍微困难,接下来将讨论一些相关方法。结果表明,在多任务的情况下,或者通过人为对问题定义进行稍微修改后,「优质策略」转化为「优质数据」就会容易很多。最后,本文讨论了「目标重标记」(goal relabeling,一种修改后的问题定义)以及「逆强化学习」如何在多任务环境下抽取「优质数据」,并给出结论。
一种将策略从数据中解耦的强化学习目标

下界的用处在于,它可以使我们使用采样自不同的策略数据来优化当前策略。该下界明显的表明:强化学习是针对策略和经验的联合优化问题。下图是对监督学习、优化和动态规划三种视角进行了对比:
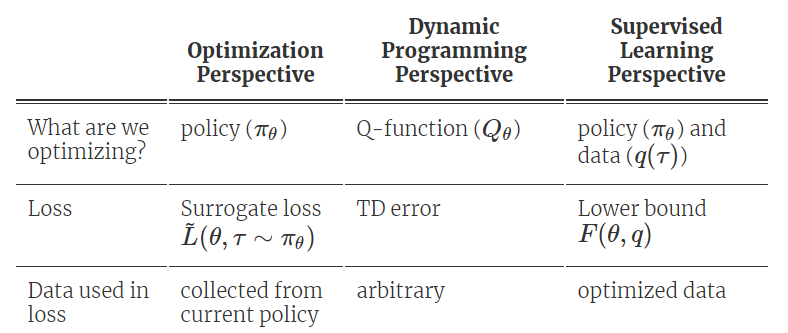
寻找「优质数据」和「优质策略」与优化关于策略参数和经验的下界 F(θ,q) 相对应。为了优化该下界,一种常用的方法是:对参数执行坐标上升(EM 算法),交替优化数据分布和策略。
策略优化
当优化关于策略的下界时,目标函数相当于监督学习(又称「行为克隆」),仅相差一个常数。
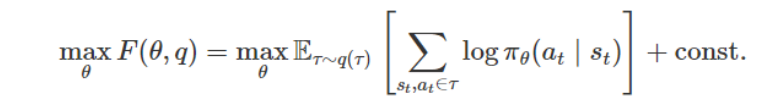
该结论十分令人激动,这是因为监督学习通常要比强化学习算法稳定得多。此外,该结论说明,之前将监督学习用作子程序的强化学习方法可能实际上是在优化期望奖励的下限。
优化数据分配
数据分发的目的是在不偏离当前政策的前提下最大化回报。
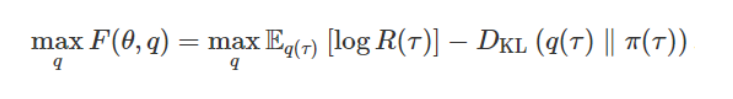
上式中的 KL 约束使得数据分布的优化较为保守,优化过程更易于以略低的奖励为代价,收敛到离当前策略较近的地方。优化预期对数奖励,而不是直接优化期望奖励,进一步使此优化问题规避了一些难题(对数函数是一种凹函数)。
我们可以使用多种方法优化数据分布。一种简单(但不高效)的策略是,通过一种带噪声的当前策略收集经验,并保留获得最高奖励的10% 的经验。另一种策略是进行轨迹优化,沿单个轨迹优化状态。第三种策略是,不收集更多的数据,而是根据奖励重新赋予之前收集到的经验轨迹以新的权重。此外,数据分布q( )可以通过多种方式来表示,即可以通过先前观察的轨迹进行非参数离散分布,或通过对单个状态-动作对进行分解后分布,或通过由一个参数化模型生成的额外的「虚假」经验扩展经验的半参数化模型。
从监督学习的角度审视前人的工作
许多算法都隐含地执行了这些步骤。例如,通过对加权的奖励数据进行行为克隆,将奖励加权回归和优势加权回归两个部分结合起来。自模仿学习根据观测到的经验轨迹的奖励对它们进行排序,以及选取 top-k 个经验的均匀分布来构造数据分布。MPO 方法通过从策略中采样动作、对这些动作重新赋权(旨在得到高额奖励)来构造数据集,然后对这些重新赋权的动作上进行行为克隆。
监督学习视角的多任务
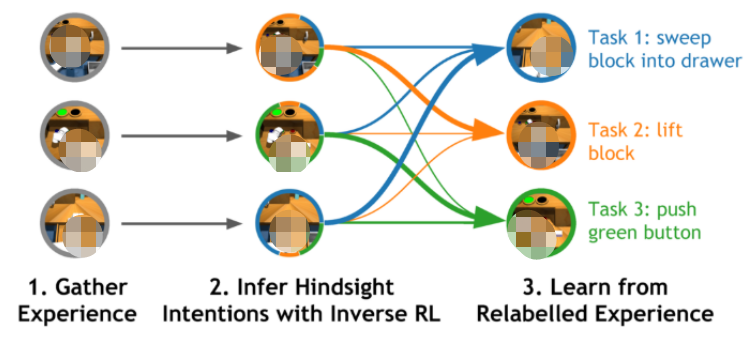 图2.许多近期的多任务强化学习算法根据每条经验解决的任务来组织经验。这种事后组织的过程与「hindsight relabeling」和「逆强化学习」关系密切,它们都是近期基于监督学习的多任务强化学习算法研究的核心。
图2.许多近期的多任务强化学习算法根据每条经验解决的任务来组织经验。这种事后组织的过程与「hindsight relabeling」和「逆强化学习」关系密切,它们都是近期基于监督学习的多任务强化学习算法研究的核心。
最近的许多算法体现了这一思路,不同之处在于,在多任务环境下,找到优质数据变得更加容易。通常而言,这些工作要么在多任务情况下直接进行操作,要么修改单任务设置,使其看起来像一个任务。当任务数量增加时,所有使用的经验对于某些任务来说都可能是最优的。
以下为从这一视角展开研究的最近发表的三篇文章:
以目标为条件的模仿学习:
在基于目标(显式设置学习目标)的任务中,我们的数据分布同时包含状态、动作以及想要达到的目标。尽管机器人可能无法达到指定的目标,但是对于它实际上达到的目标来说,它还是成功了,我们可以通过将原始的制定目标替换成实际达成的目标来优化数据分布。因此,通过以目标为条件的模仿学习和事后经验回放(HER,hindersight experience replay)实现「hindsight relabeling」可以被视为优化非参数数据分布。此外,以目标为条件的模仿可以被看作在优化后的数据上直接进行监督学习(即「行为克隆」)。值得一提的是,当带有重标记操作的以目标为条件的模仿过程迭代进行时,可以证明,即使完全没有使用专家数据,这个从头开始的学习策略也会收敛。这个结论十分令人振奋,这是因为它实际上为我们提供了一种与策略无关的强化学习技术,且不需要显式地使用任何自助采样(bootstrapping)或值函数学习技术,可以显著地简化算法和调优的过程。
以奖励为条件的策略:
有趣的是,如果我们可以在某些任务中,将从局部最优策略中收集到的非专家经验轨迹用作最优监督信号,那么也就可以将上面讨论的观点拓展到单任务强化学习设定下。当然,这些局部最优经验轨迹可能并没有最大化奖励,但是它们在匹配最优轨迹的奖励时是最优的。因此,我们可以对策略进行修改,使其以某种长程奖励的预期值(即累积回报)为条件,并且遵循与「以目标为条件的模仿学习」相类似的策略:通过指定一个累积回报的预期值,使用这种以奖励为条件的策略执行「rollout」算法;将指定的回报值重新标记为观测到的回报值,这一过程以非参数化的方式给出了优化后的数据;最后,在优化后的数据上执行监督学习。Kumar 等人通过简单的重新赋权的方案,以非参数化的方式直接优化数据(https://arxiv.org/pdf/1912.13465),实现了一种可以保证收敛到最优策略的强化学习方法。由于 Kumar 等人提出的方案不需要参数化的回报估计器(可能难以调优),因此它比大多数的强化学习方法都要简单。
通过事后推断实现改进策略:
尽管基于目标的算法与数据集优化之间的关系十分清晰,但直到最近,人们仍不清楚如何将类似的思路应用到更加一般的多任务情况下(例如,使用一个离散的奖励函数集合或一组根据变化的奖励或惩罚项的线性组合定义的奖励)。为了解决这个开放性问题,首先,我们根据直觉认为,优化数据分布与回答下列问题相对应:「若假设经验是最优的,我们将试图解决什么任务呢?」有趣的是,这也正是逆强化学习试图回答的问题。这意味着,我们可以直接使用逆强化学习在任意的多任务情况下重新标记数据:逆强化学习为跨任务经验分享提供了一种理论上的实现机制。这一结论十分振奋人心,理由如下:
1.这一结论告诉我们,如何将类似的重标记思想应用到更加一般的多任务情况下。实验表明:通过使用逆强化学习重新标记经验,可以在广泛的多任务情况下加速学习过程,甚至在基于目标的任务上性能优于先前的目标重标记方法。
2.实验结果表明,用实际达到的目标进行重标记其实相当于执行使用某种稀疏奖励函数的逆强化学习。这一结论使我们可以将之前的目标重标记技术解释为逆强化学习,从而为这类方法提供了更坚实的理论基础。
未来的研究方向
本文讨论了如何将强化学习视为使用优化的(重新标记的)数据来解决一系列标准监督学习问题。深度监督学习在过去十年的成功可能表明,将这种方法应用于强化学习,实际上可能使强化学习更容易被使用。虽然目前人们取得了不错的研究进展,但仍然存在几个悬而未决的问题。首先,是否有更好的方式可以获得优化后的数据?重新赋权或重新组合现有经验是否会在学习过程中产生偏置(bias)?强化学习算法应该如何执行探索操作,从而获得更好的数据?在这方面取得进展的方法和分析也可能为从强化学习的不同角度衍生的算法提供深刻的见解。其次,这些方法可能提供了一种简单的将深度学习领域的实践技术和理论分析迁移到强化学习领域的方式,否则由于非凸的目标(如策略梯度)或优化和测试时目标不匹配的问题(例如,贝尔曼误差和策略回报不匹配)而难以实现。这些方法的未来发展前景令人振奋:改进的实用的强化学习算法,增强了对强化学习方法的理解,等等。
参考文献: 1.Ghosh, D., Gupta, A., Fu, J., Reddy, A., Devin, C., Eysenbach, B., & Levine, S. (2019). Learning to Reach Goals via Iterated Supervised Learning arXiv:1912.06088. 2.Eysenbach, B., Geng, X., Levine, S., & Salakhutdinov, R. (2020). Rewriting History with Inverse RL: Hindsight Inference for Policy Improvement. NeurIPS 2020 (oral). 3.Kumar, A., Peng, X. B., & Levine, S. (2019). Reward-Conditioned Policies. arXiv:1912.13465.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢