

以下文章来源于微信公众号:小白学视觉
作者:小白学视觉
链接:https://mp.weixin.qq.com/s/S7LaeCdkJgScG7LLWNs-dA
本文仅用于学术分享,如有侵权,请联系后台作删文处理


paper:https://arxiv.org/pdf/2307.12101.pdf
code:https://github.com/ucas-vg/PointTinyBenchmark/tree/SSD-Det
导读:
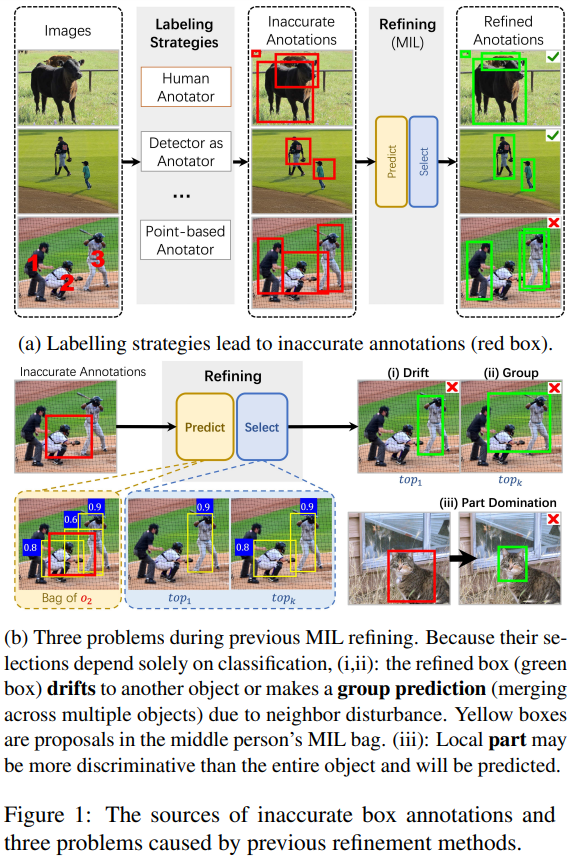
获取精确的bounding box标注代价高昂且具有挑战性。 直接使用不精确的bounding box会导致目标漂移、组预测和局部关键区域预测等问题。 以往的方法通常依赖类别信息进行框的选择和调整,没有充分利用空间信息。
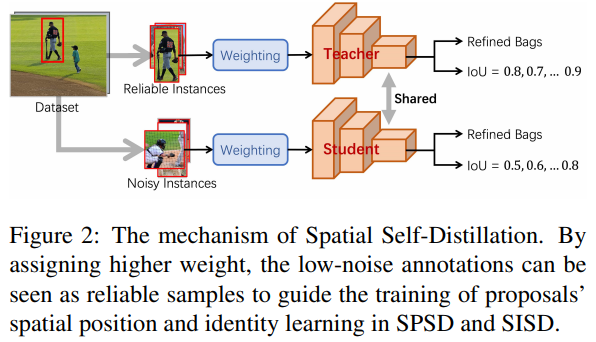
提出了SPSD( Spatial Position Self-Distillation)模块,利用空间信息生成更高质量的候选框。
提出了SISD( Spatial Identity Self-Distillation)模块,预测每个候选框与目标的空间IoU,辅助选择最佳框。
SPSD和SISD模块相结合,有效利用了空间信息和类别信息,显著提升基于不精确box的目标检测性能。
在MS-COCO和VOC数据集上进行实验表明,该方法优于其它state-of-the-art方法。
方法
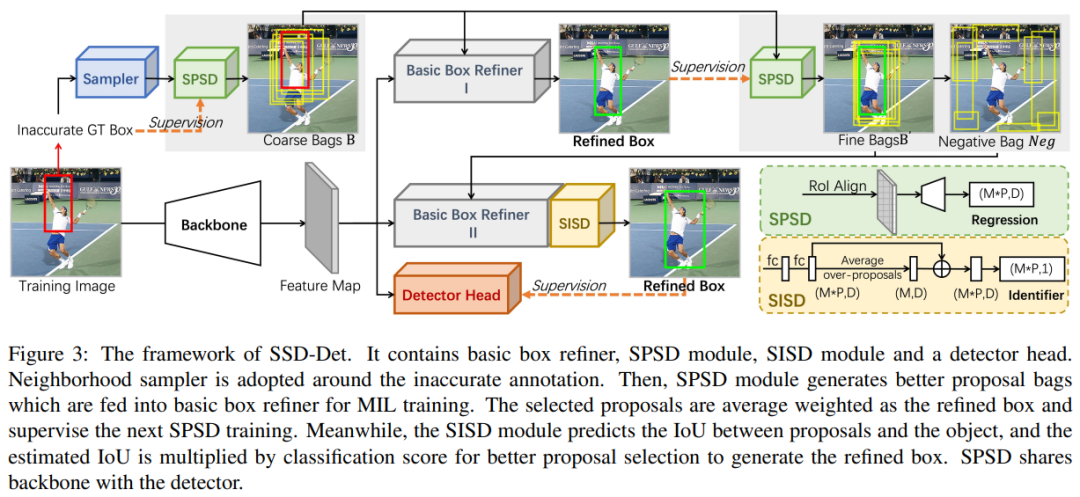
本文目标是用不精确的边界框学习一个稳健的检测器。本文设计一个分支来细化不精确的边界框,然后用细化的框训练检测器头或检测器。最重要的部分是如何设计细化策略。本文首先设计了一个基本的两阶段框细化器(图3中的灰色区域),作为原始解决方案。然后,提出SPSD和SISD并添加到其中,以进一步利用空间线索进行框细化,产生SSD-Det。总体损失函数公式化为:
主要创新模块
Basic Box Refiner
对每个物体生成候选框组成bag 使用分类分支预测每个框属于各类别的概率 使用实例分支预测每个框被选中的概率 计算分类概率和实例概率的乘积作为框的得分 选择得分最高的前k个框,计算其加权平均作为精炼结果
SPSD
输入:Basic Box Refiner产生的候选框 输出:更高质量的候选框 预测更准确的框来优化候选框的生成 使用回归网络学习候选框之间的空间对应关系 监督信号是不精确的ground truth框 预测框与ground truth框的空间偏差 利用学习到的空间知识纠正基础框生成模块的误差 迭代优化,产生更准确接近ground truth的候选框
SISD
对每个候选框预测其与目标的空间IoU IoU与分类概率相结合作为新得分进行选择
引入空间信息,缓解目标漂移、组预测等问题 选择更准确框进行精炼
三者关系与联系
实验
实验设置
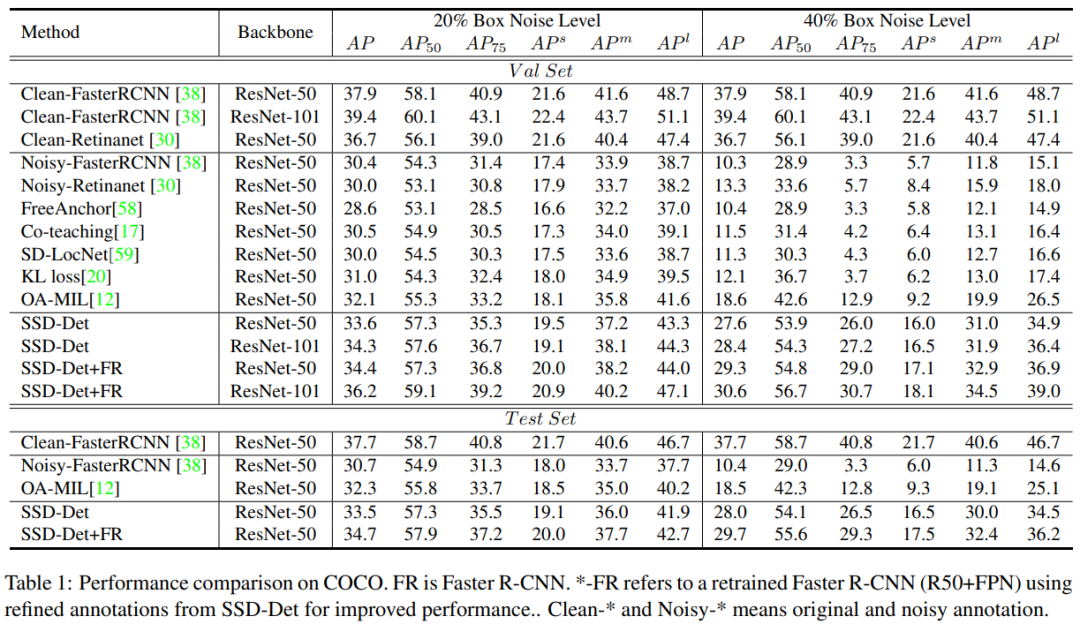
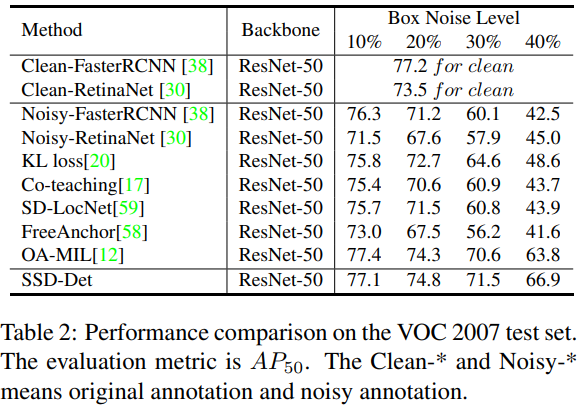
与SOTA的比较
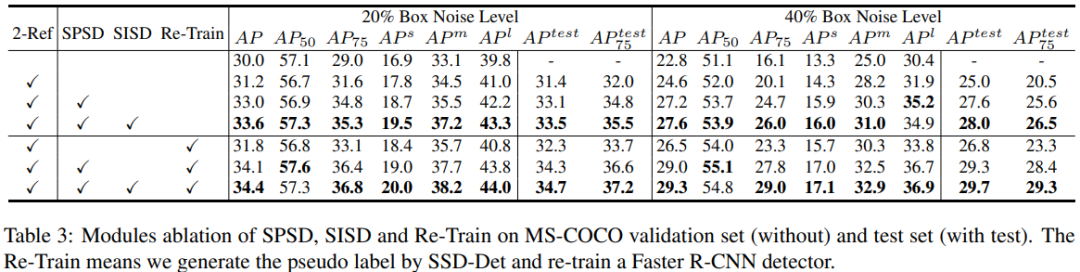
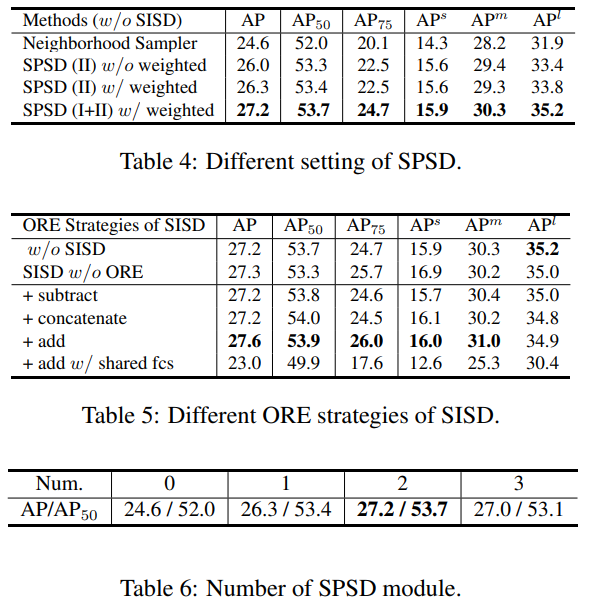
消融实验分析

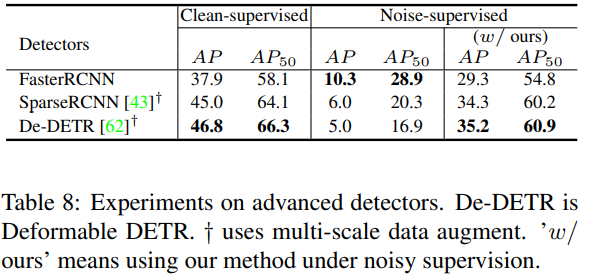

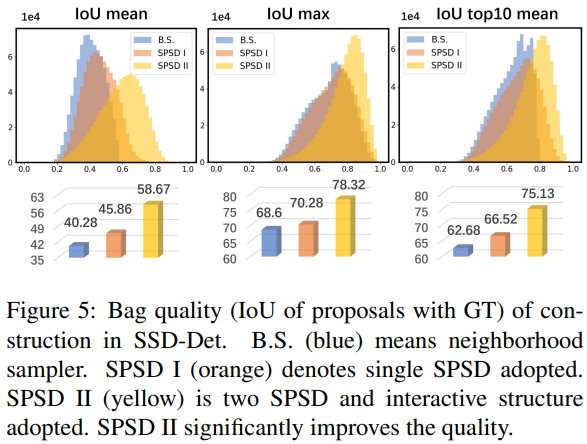
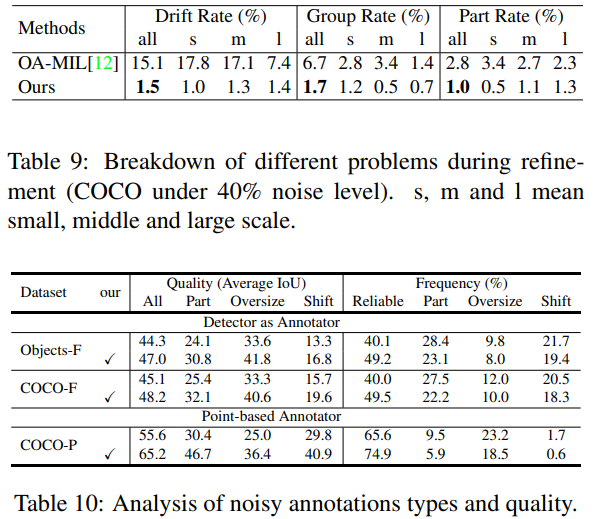
结论
推荐阅读

AIHIA | AI人才创新发展联盟2023年盟友招募
AIHIA | AI人才创新发展联盟2023年盟友招募

AI融资 | 智能物联网公司阿加犀获得高通5000W融资
AI融资 | 智能物联网公司阿加犀获得高通5000W融资

Yolov5应用 | 家庭安防告警系统全流程及代码讲解

江大白 | 这些年从0转行AI行业的一些感悟
Yolov5应用 | 家庭安防告警系统全流程及代码讲解
江大白 | 这些年从0转行AI行业的一些感悟

《AI未来星球》陪伴你在AI行业成长的社群,各项福利重磅开放:
(1)198元《31节课入门人工智能》视频课程;
(2)大白花费近万元购买的各类数据集;
(3)每月自习活动,每月17日星球会员日,各类奖品送不停;
(4)加入《AI未来星球》内部微信群;
还有各类直播时分享的文件、研究报告,一起扫码加入吧!


大家一起加油! 
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢