

Firefly项目链接:
https://github.com/yangjianxin1/Firefly
firefly-internlm-7b模型权重:
https://huggingface.co/YeungNLP/firefly-internlm-7b
01
书生·浦语InternLM
InternLM ,即书生·浦语大模型,是由上海人工智能实验室开发的,包含面向实用场景的70亿参数基础模型与对话模型 (InternLM-7B)。
https://github.com/InternLM/InternLM
模型具有以下特点:
使用上万亿高质量语料,建立模型超强知识体系;
支持8k语境窗口长度,实现更长输入与更强推理体验;
通用工具调用能力,支持用户灵活自助搭建流程;
该团队还开源了大模型评测工具OpenCompass,并且有OpenCompass大模型排行榜,可以从学科综合能力、语言能力、知识能力、推理能力、理解能力五大能力维度对模型进行评测。
https://github.com/InternLM/opencompass
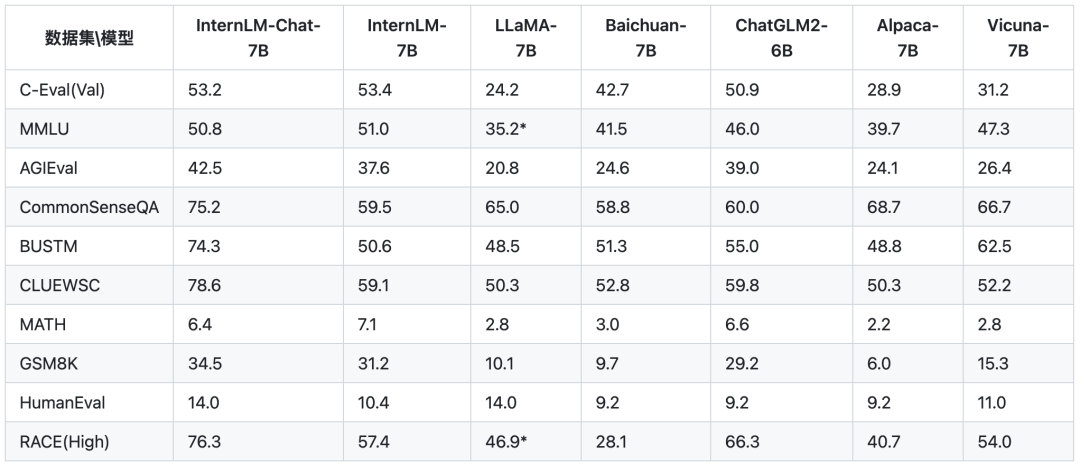
对于InternLM模型,官方提供的评测结果如下图所示,就该评测结果而言,InternLM-7B相比Baichuan-7B存在一定的优势。
OpenCompass排行榜上有更丰富的模型评测结果,该榜单从学科综合能力、语言能力、知识能力、理解能力、推理能力等多种维度对模型进行评测。我们摘录了部分模型在中文数据集上的综合评分,其中InternLM-7B的表现不俗,超越了XVERSE-13B、Baichuan-7B,逼近Baichuan-13B-Base。
| 模型 | 中文综合评分 |
| GPT-4 | 73.3 |
| ChatGPT | 63.5 |
| Qwen-7B | 56.5 |
| LLaMA-2-13B | 49 |
| Baichaun-13B-Base | 46.9 |
| InternLM-7B | 46.5 |
| LLaMA-2-7B | 42.9 |
| XVERSE-13B | 40.8 |
| LLaMA-7B | 39.6 |
| Baichuan-7B | 38.1 |
上述表格中,除了GPT-4与ChatGPT外,我们只列出了预训练模型,也就是未经过指令微调的模型,各个预训练模型之间的差距还是非常大的。
榜单中出现了几个比较有意思的评测现象,在此抛出来和大家一起分享讨论:
Qwen-7B碾压一众中文模型,在所有中文预训练模型中排名第一,并且拉开了非常大的差距。
InternLM-7B优于XVERSE-13B,逼近Baichaun-13B-Base。
在中文榜单上,部分英文模型优于中文模型。例如LLaMA-7B优于Baichuan-7B,LLaMA-2-13B优于Baichaun-13B-Base。
在英文榜单上,Qwen-7B以57.9分,InternLM以53.4分,Baichuan-13B-Base以50.5分,击败LLaMA-2-70B的49.7分。
对于上述现象,在此抛砖引玉,欢迎讨论,一家之言,仅供参考。
Qwen-7B碾压一众中文模型,大概率可以归功于其2.2万亿的预训练token。在OpenCompass的英文榜单上,Llama-13B与Llama-2-7B的综合评分分别为36.3和36.8,也出现了以小胜大的情况。这说明通过堆数据,在榜单上以小胜大也是合理的现象。
在中文榜单上,LLaMA优于Baichuan;在英文榜单上,一系列13B以下的小模型击败了LLaMA-2-70B。比较反直觉,也许需要深入到综合评分的构成,以及评测方法。
如今大模型预训练,大家恨不得把整个互联网的数据都塞进模型里,无可避免,或多或少会有一部分榜单数据,或者类榜单的数据参与训练,造成数据泄露。这也是当前各种开源榜单的局限性。
当前很多大模型榜单,很大部分评测集是客观题、常识题,还是以做题的思路评测大模型,对于评测大模型的能力,也许还不够全面。不过也是能够从某一角度,为大模型的能力提供依据。
总而言之,言而总之,大模型的评测工作很困难,目前开源的评测榜单或多或少存在一些局限性。开源评测榜单可以作为参考,但需要结合具体业务进行更加全面的评测工作。
期待国产开源大模型百花齐放,百家争鸣,共同进步。
更多模型的评测结果可以查看OpenCompass排行榜:
https://opencompass.org.cn/leaderboard-llm
02
微调InternLM
<s>input1</s>target1</s>input2</s>target2</s>...对于QLoRA,除了embedding和lm_head外,我们在所有全连接层都插入adapter,其中lora_rank为64,lora_alpha为16,lora_dropout为0.05。最终参与训练的参数量约为1.6亿。global batch size为64,为防止过拟合,仅训练一个epoch。
{"output_dir": "output/firefly-internlm-7b","model_name_or_path": "internlm/internlm-7b","train_file": "./data/dummy_data.jsonl","num_train_epochs": 1,"per_device_train_batch_size": 8,"gradient_accumulation_steps": 2,"learning_rate": 2e-4,"max_seq_length": 1024,"logging_steps": 300,"save_steps": 500,"save_total_limit": 1,"lr_scheduler_type": "constant_with_warmup","warmup_steps": 3000,"lora_rank": 64,"lora_alpha": 16,"lora_dropout": 0.05,"gradient_checkpointing": true,"disable_tqdm": false,"optim": "paged_adamw_32bit","seed": 42,"fp16": true,"report_to": "tensorboard","dataloader_num_workers": 0,"save_strategy": "steps","weight_decay": 0,"max_grad_norm": 0.3,"remove_unused_columns": false}
torchrun --nproc_per_node={num_gpus} train_qlora.py --train_args_file train_args/qlora/internlm-7b-sft-qlora.json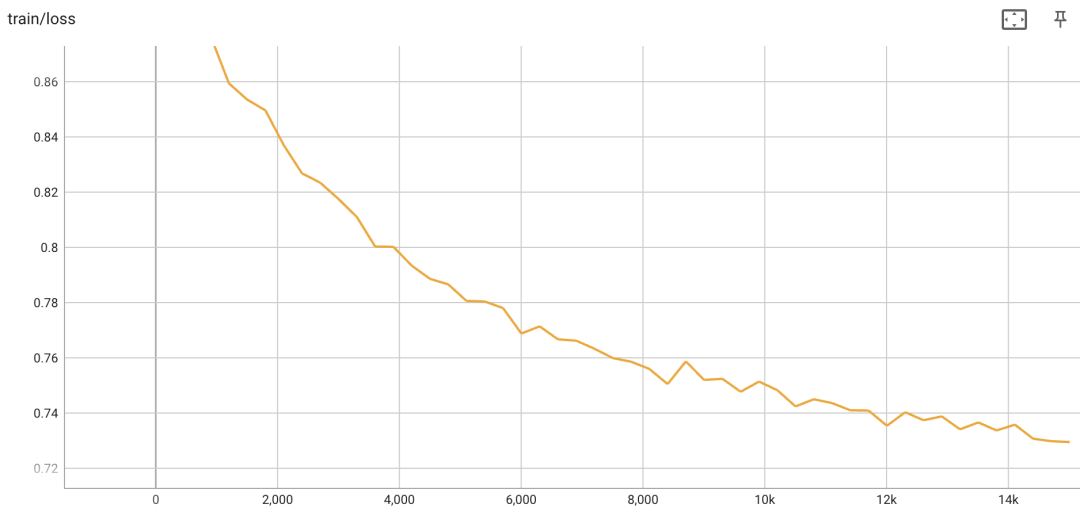
03
模型效果
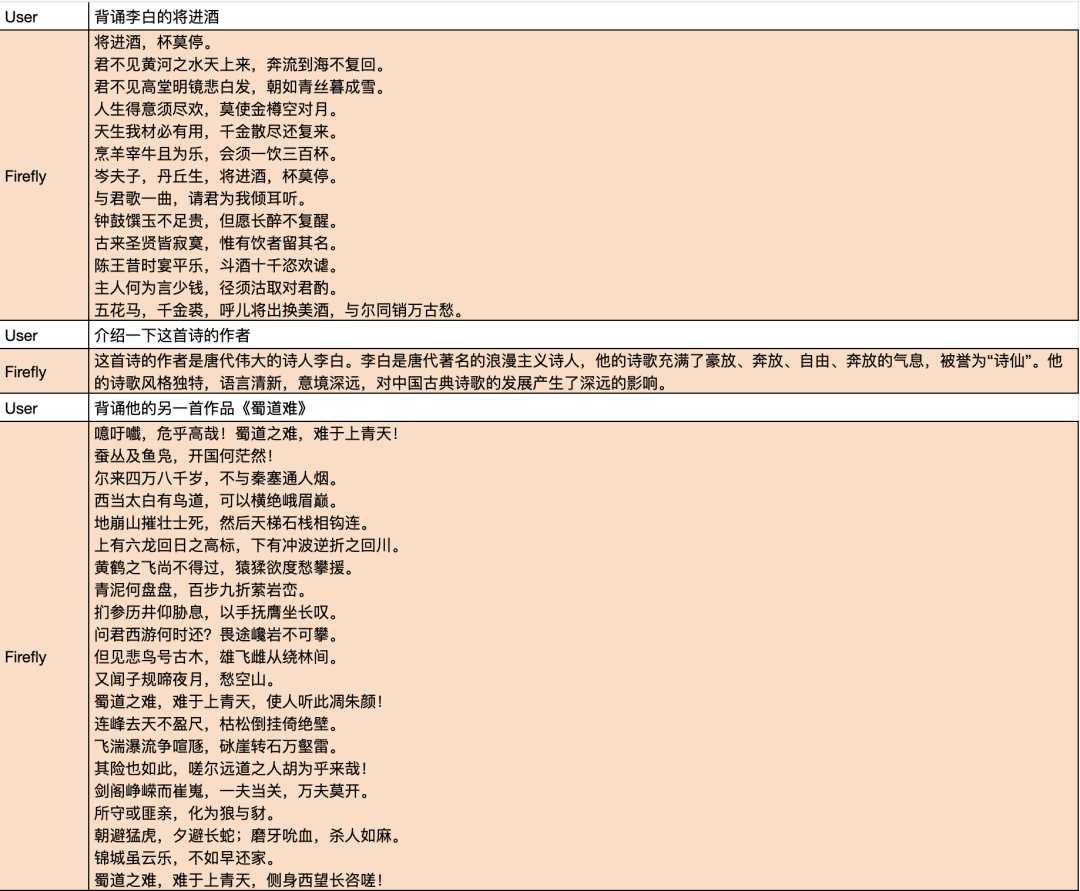












更多生成示例,请扫描二维码,或者打开文档链接,查看共享文档的内容:
https://docs.qq.com/sheet/DU3JIcHJlSVZHS2Zl?tab=c5vlid

04
结语
本文主要对书生·浦语InternLM模型进行了介绍,分享了Firefly对InternLM-7B模型进行微调的效果,并且分享了OpenCompass排行榜上一些评测结果。总体而言,书生·浦语InternLM是一个优秀的中文基座模型。
最后期待国产开源大模型百花齐放,百家争鸣。
2023-08-26

2023-08-25





点击下方“阅读原文”直达 InternLM
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢