

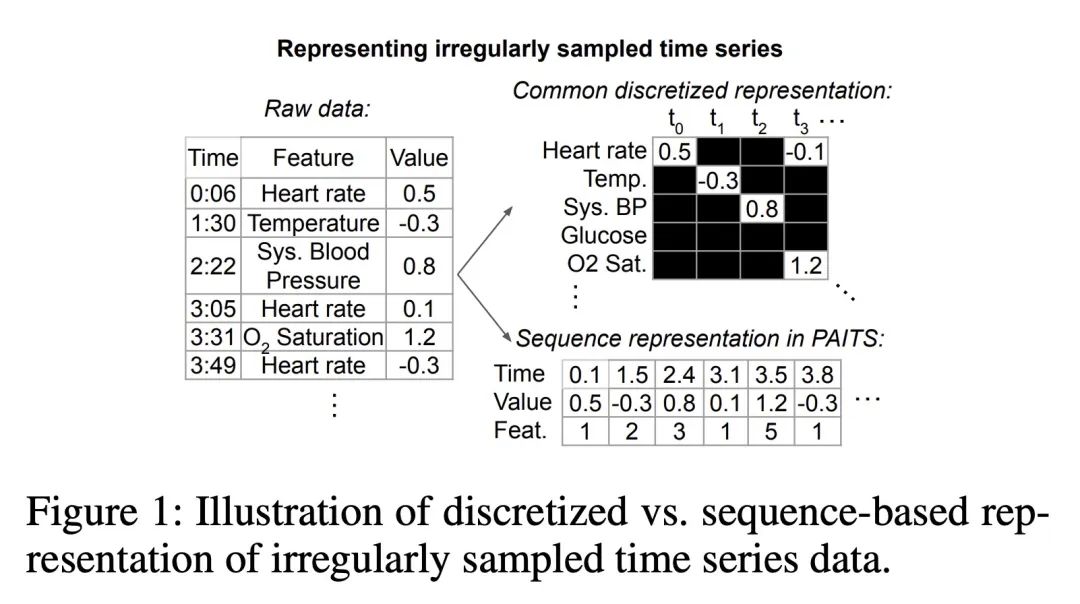
PAITS: Pretraining and Augmentation for Irregularly-Sampled Time Series
N Beebe-Wang, S Ebrahimi, J Yoon, S O. Arik, T Pfister
[Google Cloud AI Research]
PAITS:针对不规则采样时间序列的预训练和增强方法
-
提出PAITS,一种对不规则采样的多变量时间序列数据进行预训练和数据增强的框架。 -
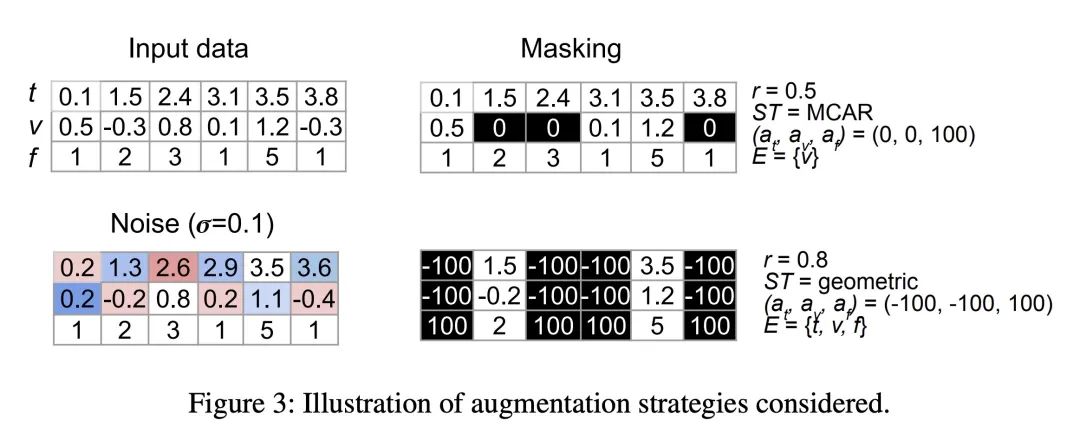
结合了NLP领域启发的预训练任务,如预测和序列重建,以及噪音和掩码等数据增强。 -
用随机搜索来识别不同数据集的有效预训练策略。 -
实验表明,PAITS在多个医疗和零售数据集上始终优于之前的预训练方法,如STraTS、TST、TS-TCC。 -
分析表明,不同的数据集受益于PAITS搜索空间中的不同策略。预测任务往往比重建任务更有用。 -
PAITS选择了能改善不规则稀疏时间序列表示学习的噪音和掩码增强。 -
限制是PAITS仍需要在策略上进行搜索,缺乏全自动选择最佳方法的方式。
动机:现有的时间序列预训练和增强方法并不适用于不规则采样的时间序列数据,因此需要开发一种针对稀疏和不规则采样时间序列数据的预训练策略。
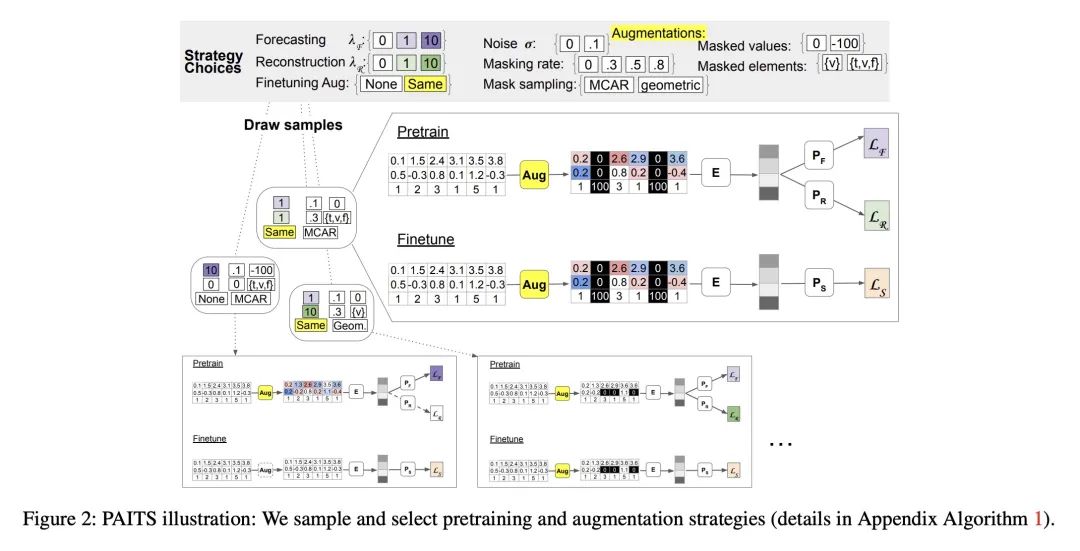
方法:提出一种名为PAITS的框架,通过结合受自然语言处理(NLP)启发的预训练任务和增强方法,并使用随机搜索来确定适合给定数据集的预训练策略。
优势:与现有方法相比,PAITS能在多个数据集和领域中持续改进预训练效果。
PAITS是一种针对稀疏和不规则采样时间序列数据的预训练和增强方法的框架,通过结合NLP启发的任务和增强方法,并使用随机搜索来确定最佳预训练策略。
Real-world time series data that commonly reflect sequential human behavior are often uniquely irregularly sampled and sparse, with highly nonuniform sampling over time and entities. Yet, commonly-used pretraining and augmentation methods for time series are not specifically designed for such scenarios. In this paper, we present PAITS (Pretraining and Augmentation for Irregularly-sampled Time Series), a framework for identifying suitable pretraining strategies for sparse and irregularly sampled time series datasets. PAITS leverages a novel combination of NLP-inspired pretraining tasks and augmentations, and a random search to identify an effective strategy for a given dataset. We demonstrate that different datasets benefit from different pretraining choices. Compared with prior methods, our approach is better able to consistently improve pretraining across multiple datasets and domains. Our code is available at https://github.com/google-research/ google-research/tree/master/irregular timeseries pretraining
https://arxiv.org/abs/2308.13703
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢