


ICML 2023会议于7月25日-7月27日在Hawaii召开。大会于共收到 6538 份投稿,有1827 份被接收,录用率为27.9%。本文介绍一篇给大语言模型添加水印的论文,该论文荣获ICML 2023 Outstanding Paper。
1. 绪论
1.1.研究目标
水印可以通过算法检测,而不需要任何模型参数的知识或访问语言模型API。此属性允许检测算法是开源的,即使模型不是。这也使得检测既便宜又快速,因为LLMs不需要加载或运行。 水印文本可以使用标准语言模型生成,无需重新训练。 水印只能从生成文本的连续部分检测到。这样,当只使用生成的一部分来创建更大的文档时,水印仍然是可检测的。 如果不修改生绝大部分的生成文本,就无法删除水印。 可以计算水印已被检测到的置信度的严格统计度量。
1.2.低熵序列水印的困难
考虑以下两个token序列,其中红色为prompts:
The quick brown fox jumps over the lazy dog
for(i=0;i<n;i++) sum+=array[i]
它们是由人类还是由语言模型产生的?确定这一点是很困难的,因为这些序列具有低熵的性质;前几个token决定了后面的tokens。低熵文本给水印带来了两个问题。首先,人类和机器都为低熵prompt提供了相似但不完全相同的补全,二者很难区分。其次,prompt token的任何变化都可能导致后续token的高困惑度,以及难以预料的token的出现,从而降低文本的质量,所以很难对低熵文本进行水印。
2.概念的简单证明
2.1 水印检测
虽然生成带水印的文本需要访问语言模型,但检测水印则不需要。了解哈希函数和随机数生成器的第三方可以为每个token重新生成红名单,并计算违反红名单规则的次数。

我们可以通过测试以下零假设H0来检测水印:
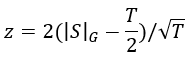
2.2. 移除水印有多困难?
one proportion z-test的使用使得水印的去除变得困难。考虑长度T=1000的带水印序列的情况。假设有人修改了序列中的200个token以添加红名单中的单词来试图擦除水印。在位置t处的修改的token可以违反在位置t的红名单规则。此外,st的值确定了st+1的红名单,并且st的最大对抗性选择也将使st+1违反红名单规则的。因此,200次token翻转最多可以造成400次违反红名单规则的行为。不幸的是,对于攻击者来说,这个剩余600个绿名单token的最大对抗性序列仍然产生2(600−1000/2)/√1000≈6.3的z-statistic和≈10-10的p值,使水印很容易被检测到,具有极高的可信度。通常,删除长序列的水印需要修改大约四分之一或更多的token。
2.3硬红名单规则的缺点
硬红名单规则以一种简单的方式处理低熵序列;它阻止语言模型生成它们。例如,在许多文本数据集中,“Barack”后面几乎是“Obama”,但“Obama”可能会被红名单所禁止。
一种更好的行为是使用“软”水印规则,该规则仅对可以被不可察觉地加水印的高熵文本有效。但只要低熵序列被包裹在具有足够总熵的段落中,该段落仍然很容易触发水印检测器,从而解决第1.2节中描述的问题。此外,可以将水印与波束搜索解码器相结合,该波束搜索解码器“熨烫”水印。通过搜索可能的token序列的假设空间,找到了具有高密度绿名单token的候选序列,从而产生了具有最小困惑成本的高强度水印。
3. 更复杂的水印
3.1软水印
为了推导这个水印,我们检查了在语言模型生成概率向量之前发生的事情。语言模型的最后一层输出logits l(t)的向量。使用softmax将这些logits转换为概率向量p(t)。如算法2所示,该算法没有严格禁止红名单token,而是向绿名单token的logits添加了一个常数δ。

在对质量影响不大的情况下,软红名单规则会自适应地强制执行水印,而在低熵情况下,几乎忽略水印规则,因为在这种情况下,句子序列有明确而唯一的最佳选择。P(t)≈1的极大概率单词的k logit比其他候选单词大得多,无论它是否在红名单中,它都将保持最大。但当熵高时,有许多相对较大的logit可供选择,并且δ规则对采样分布有很大影响,使输出强烈偏向绿名单。
3.2软水印检测
检测软水印的过程与检测硬水印的过程相同。我们假设零假设H0,并使用下面的公式来计算z-statistic。如果z大于阈值,我们拒绝零假设并检测水印。
H0:
The text sequence is generated with no knowledge of the red list rule.
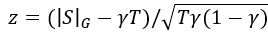
再次考虑我们检测z>4的水印的情况。就像在硬水印的情况下一样,我们得到的假阳性率为3×10-5。在硬水印的情况下,无论文本的属性如何,我们都可以检测到长度为16个或更多token的任何带水印序列。然而,在软水印的情况下,我们检测合成文本的能力取决于序列的熵。高熵序列是用相对较少的token来检测的,而低熵序列需要更多的token来进行检测。下面,我们严格分析了软水印的检测灵敏度及其对熵的依赖性。
4.软水印分析
在本节中,我们检查了带水印的语言模型所使用的绿名单token的预期数量,并分析了该数量对生成的文本片段的熵的依赖性。我们的分析假设红名单是随机抽取的。这与实践中使用的方法有所不同,实践中使用以先前token为种子的伪随机数生成器生成红名单。第5节探讨了伪随机采样的后果。我们分析了通过多项式随机抽样生成文本的情况。在我们的实验中,我们考虑了另外两种采样方案,贪婪解码和波束搜索。
我们需要一个适合我们分析的熵的定义。当token上的分布集中在一个或多个token上时,我们的水印强度较弱。我们定义了以下类型的熵来量化这种现象。
定义4.1:给定一个离散概率向量p和一个标量z,我们定义了模为z的p的尖峰熵(spike entropy)为
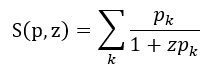
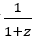 ,当p的质量均匀分布时,其最大值为
,当p的质量均匀分布时,其最大值为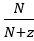 。
。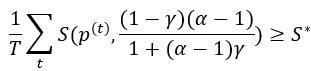
则序列中的绿名单token的数量至少具有期望值:
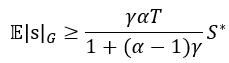
此外,绿名单token的数量方差最大为:

4.1水印测试的灵敏度
软水印的灵敏度可以使用标准的II型误差分析来计算。为了便于说明,我们估计了γ=.5和δ=2的软水印的II型(假阴性)错误率。我们假设使用OPT-1.3B使用C4数据集的RealNewsLike子集中的提示生成200个token。我们还假设检测阈值z=4(发生在~128.2/100个tokens时),这给了我们3×10-5的I型错误(假阳性)率。
理论边界。定理4.2表明,每一代绿名单token的预期数量至少为142.2。事实上,经验平均值为159.5。对于熵等于平均值(S=0.807)的序列,使用绿名单计数的标准高斯近似,我们得到σ≤6.41个tokens和98.6%的灵敏度(1.4%的II型错误率)。注意,这是这个特定熵的灵敏度的下限。如果我们使用159.5的真实经验平均值而不是理论边界,我们得到了5.3×10-7的II型误差率,这是一个现实的近似值,但不是严格的下限。
经验敏感性。根据经验,当使用多项式采样时,98.4%的模型在z=4(128个token)阈值下被检测到。当使用贪婪解码上的4向波束搜索时,我们获得了99.6%的经验灵敏度。与理论边界不同,这些边界是在所有模型中计算的,他们具有相同的长度,但各自的熵不同。这里,II型误差的主要来源是低熵序列,因为上面的计算表明,当熵接近平均值时,我们预计误差率非常低。
当语言模型产生的分布是均匀的(最大熵)时,绿名单的随机性导致token被均匀采样,并且复杂性保持不变。相反,在最小熵的情况下,所有概率质量都集中在单个token上,软水印规则没有效果,并且再次对困惑度没有影响。然而,对于中等熵的表征,水印规则确实影响了困惑度。
5. 实验
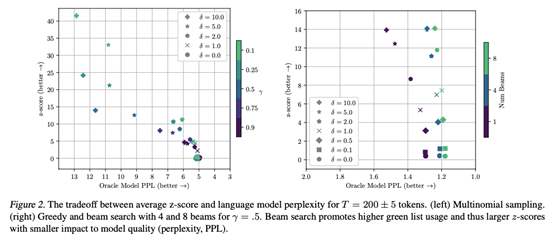
除了这些定量结果外,我们在表1中显示了真实prompt和带水印输出的测试结果,为测试统计和质量测量在不同类型prompt上的行为提供了定性意义。

图2(右)显示了使用波束搜索时水印强度和准确性之间的trade-off。波束搜索与软水印规则具有协同作用。特别是当使用8个波束时,图2中的点形成了一条几乎垂直的线,显示出实现强水印的非常小的困惑成本。
5.3 水印强度与token数量
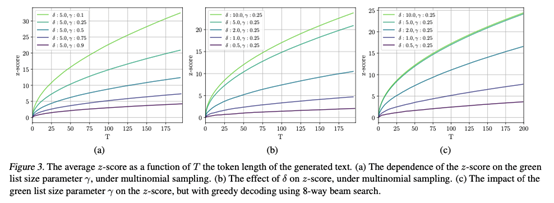
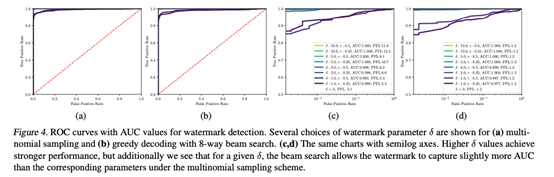
5.4 多项式采样的性能和灵敏度
为了显示基于观察到的z分数的结果假设检验的灵敏度,我们在表2中提供了各种水印参数的错误率表。图4报告了ROC图表中的一系列阈值。我们在论文附录中进一步报告了各种截止值的检测性能和错误率,并提供了经验z分数和理论预测之间的比较。请注意,对于错误表中显示的任何运行,都没有观察到I型(假阳性)错误(请参见0.0的列)。
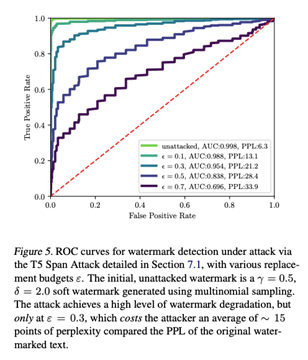
6. 攻击水印
攻击下的降级:使用LM进行span替换
T5 span攻击的详细信息:
我们使用T5tokenizer来处理水印文本。然后,当执行的成功替换少于εT或达到最大迭代次数时:
1.用<mask>随机替换token中的一个单词。
2.将掩码token周围的文本区域传递给T5,以通过50向波束搜索获得k=20个候选替换token序列的列表,相关联的分数对应于它们的可能性。
3.每个候选被解码成一个字符串。如果模型返回的k个候选中有一个不等于屏蔽span对应的原始字符串,则攻击成功,并用新文本替换span。
7. 结论
关于水印,仍然有许多悬而未决的问题。例如,在流媒体环境中测试水印的最佳方法是什么,或者在一个短的带水印文本位于较长的无水印文本中的环境中测试?我们希望我们目前的研究结果足以让读者相信,水印可以成为一种实用的工具,用于打击生成模型的恶意使用,我们将这些额外的问题留给未来的研究。
代码链接:https://www.github.com/jwkirchenbauer/lm-watermarking
论文链接:https://arxiv.org/abs/2301.10226
助手微信

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢