
LoRA是一种轻量化的模型微调训练技术,它既加速了大模型训练,同时也降低了显存占用。LoRA的全称是Low-Rank Adaptation, 意思是降低训练过程中权重矩阵的秩来起到优化的效果。具体来说,全参数微调会训练attention里的QKV权重矩阵,这些矩阵通常来说很大,导致了巨量的训练成本。而LoRA会冻结这些权重,转而训练一个仅包含少量参数的LoRA模块,如下图橙色部分所示。其原理是在中间插入一个维度低的瓶颈层,这样可训练的参数从dd变为了dr+rd。 因为r相对于d很小,所以可训练的参数量也大幅降低。![]()
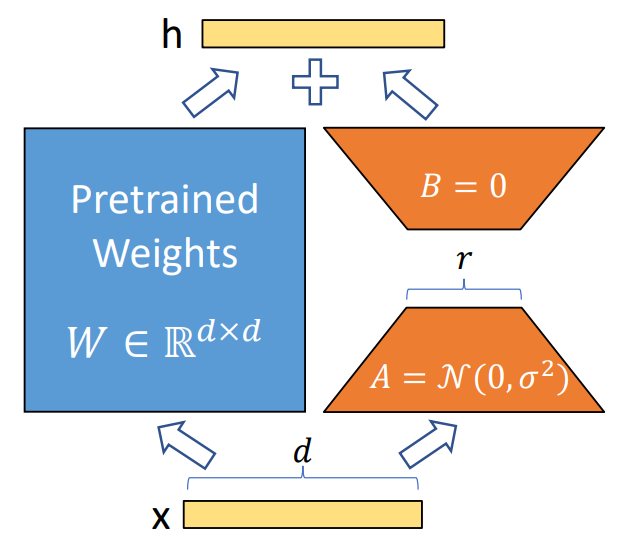
经过实测,在Aquila-7B模型的Lora 微调中,设置r=8的情况下,训练参数从73亿降到了420万,仅为之前的0.057%。
在英伟达A100*80G4卡且batch_size=1的配置下,相比于全量SFT训练,LoRA所占用的显存降低了67.5%,训练速度增加了25.0%。LoRA的另一个优点是训练的参数量少而且可以独立保存,使得保存权重和转移权重更加方便。
操作指南
注:以下操作步骤适用于 Aquila-7B 基座模型及 SFT模型(AquilaChat-7B)的微调过程。
第一步 安装FlagAI
git clone git@github.com:FlagAI-Open/FlagAI.git
cd FlagAI
pip install -e .第二步 训练(适用于aquila-7b或aquilachat-7b模型)
- 进入./examples/Aquila/Aquila-chat目录
- 在Aquila-chat-lora里调整训练参数,以及数据集位置
- 配置hostfile文件,需要将替换本机ip, 以及决定使用多少张卡训练
其中本机ip可通过如下指令获取(说明:需根据自身网卡配置进行调整)
ifconfig eth0 | grep "inet " | awk '{print $2}'- 准备好用来微调的模型,放在./checkpoints_in里
- 运行如下指令一键开启lora训练
bash [启动脚本文件] [hostfile文件] [配置文件] [模型名称] [实验名称]例如
bash local_trigger_docker.sh hostfile Aquila-chat-lora.yaml aquila-7b aquila_experiment- Aquila-chat-lora.yaml配置参考:
batch_size: 1
epochs: 10
gradient_accumulation_steps: 1
lr: 4.0e-5
warm_up: 0.01
warm_up_iters: 200
lora_r: 8
lora_alpha: 32
save_interval: 500
log_interval: 10
bmt_cpu_offload: False
bmt_pre_load: True
bmt_lr_decay_style: 'cosine'
save_optim: True
save_rng: True
enable_flash_attn_models: False
eps: 1.0e-8
lora: True
enable_sft_dataset_dir: '/data2/yzd/data/'
enable_sft_dataset_file: 'sft_v0.9.10_train.jsonl'
其中Lora有如下可调整参数,可在Aquila-chat-lora.yaml中设置
| 名称 | 简介 | 范围 |
| lora_r | LoRA的秩,lora_r越低代表可训练的参数越少,显存和速度的优化效果更好, 但有可能会损失训练效果 | 一般在8到64之间 |
| lora_alpha | lora训练的时候一般会增加学习率, 系数为 lora_alpha/lora_r | 大于lora_r |
| lora_dropout | 停掉一部分神经元,来避免过拟合 | 默认0.05,一般在0.05左右 |
| lora_target_modules | 模型attention层里需要进行LoRA优化的模块名称列表 | 默认是["wq","wv], 可增加更多模块名称 |
悟道·天鹰Aquila系列模型是智源研究院推出的开源大语言模型,支持免费商用许可。
- 使用方式一(推荐):通过 FlagAI 加载 Aquila 系列模型 https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
- 使用方式二:通过 FlagOpen 模型仓库单独下载权重 https://model.baai.ac.cn/
- 使用方式三:通过 Hugging Face 加载 Aquila 系列模型 https://huggingface.co/BAAI



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢