
人脸识别是计算机视觉社区长期以来的活跃课题。之前的研究者主要关注人脸特征提取网络所用的损失函数,尤其是基于softmax的损失函数大幅提升了人脸识别的性能。然而,飞速增加的人脸图像数量和GPU内存不足之间的矛盾逐渐变得不可调和。
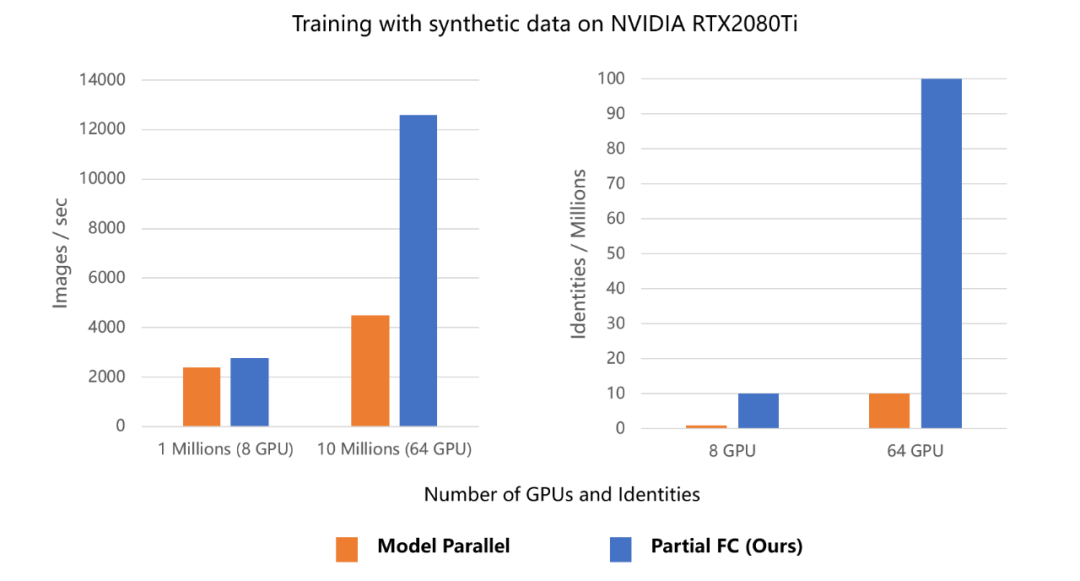
最近,格灵深瞳、北京邮电大学、湘潭大学和北京理工大学的研究者深入分析了基于softmax的损失函数的优化目标,以及训练大规模人脸数据的困难。研究发现,softmax函数的负类在人脸表示学习中的重要性并不像我们之前认为的那样高。实验表明,在主流基准上,与使用全部类别训练的SOTA模型相比,使用10%随机采样类别训练softmax函数后模型准确率未出现损失。
该研究还实现了一个高效的分布式采样算法,兼顾模型准确率和训练效率,而且只用八块英伟达 RTX2080Ti 显卡就完成了数千万人脸图像的分类任务。为了验证该算法的效果和稳健性,研究人员清洗和合并了现有的公共人脸数据集,得到目前最大的公共人脸识别训练数据集Glint360K。
论文地址:https://arxiv.org/pdf/2010.05222.pdf 代码地址:https://github.com/deepinsight/insightface/tree/master/recognition/partial_fc
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢