
导读
 图:OpenAI官网宣布开始构建超级对齐系统
图:OpenAI官网宣布开始构建超级对齐系统什么是超级对齐
1.1 超级对齐的目标
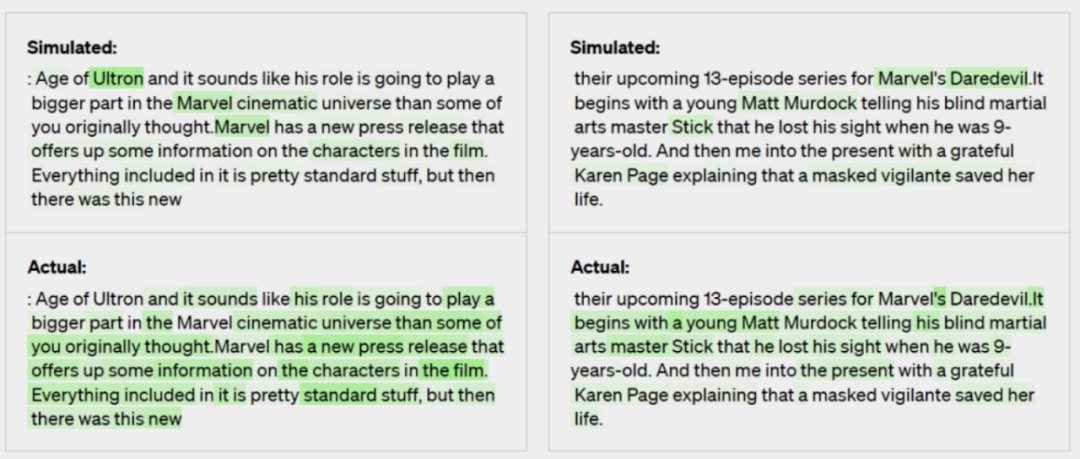 图:GPT-4模拟输出从而提供可扩展监督的能力示例
图:GPT-4模拟输出从而提供可扩展监督的能力示例1.2 超级对齐的能力
为什么要实现超级对齐
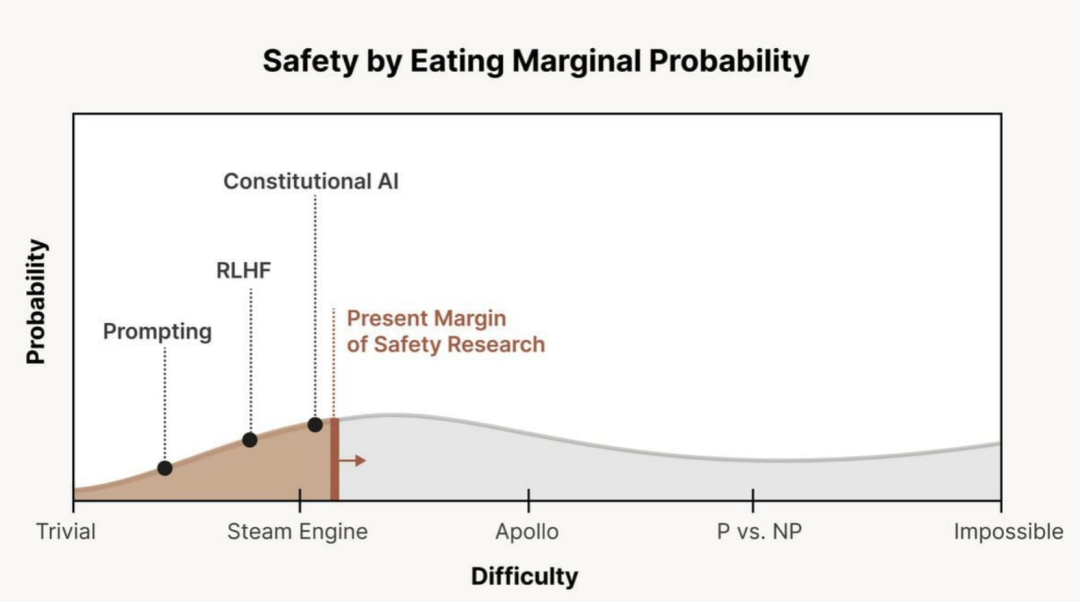 图:不同难度层次的超级对齐
图:不同难度层次的超级对齐2.1 简单场景
2.2 中等场景
2.3 困难场景
如何实现超级对齐
3.1 可扩展的训练方法
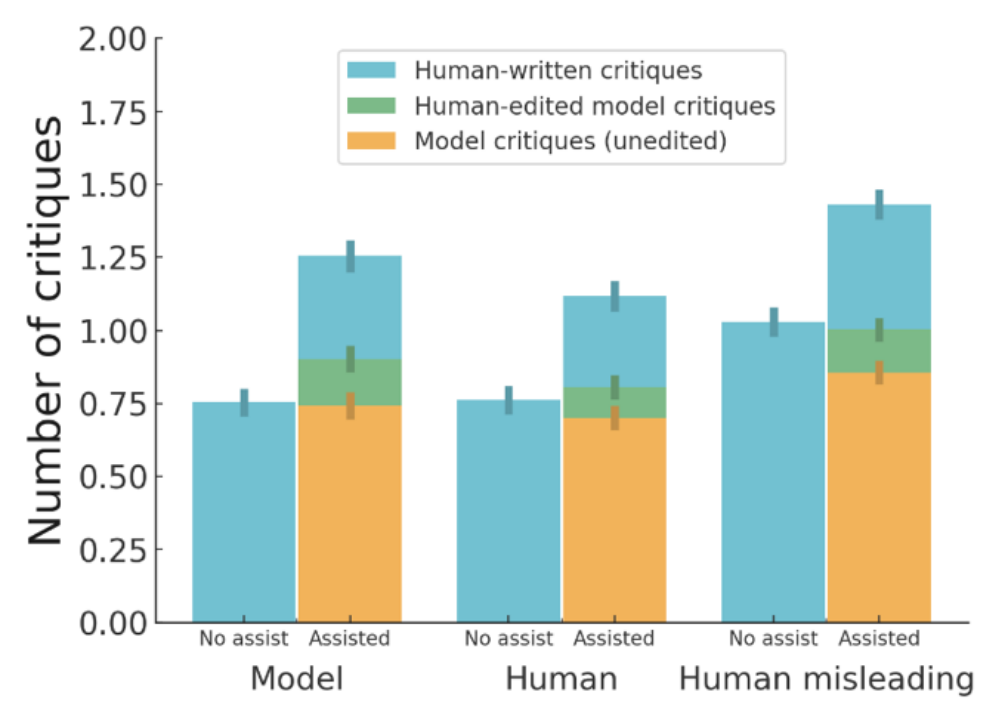 图:模型自我评估对人类监督的提升
图:模型自我评估对人类监督的提升3.2 验证系统
 图:GPT-4自动生成解释
图:GPT-4自动生成解释3.3 压力测试
四、总结
更多内容 尽在智源社区
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢