
前言 本文作者提出一种聚焦线性注意力机制 (Focused Linear Attention),力求实现高效率和高表达力。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题,群文件里也有很多计算机视觉入门的电子版资料,想要领取的朋友请加群自行下载。
本文目录
1 Flatten Attention:聚焦的线性注意力机制构建视觉 Transformer
(来自清华,黄高老师团队)
1 Flatten Attention 论文解读
1.1 背景:现有线性注意力机制的不足之处
1.2 线性注意力机制的聚焦能力不够及其解决方案
1.3 线性注意力机制的特征丰富度不够及其解决方案
1.4 聚焦线性注意力机制
1.5 实验结果
太长不看版
在将 Transformer 模型应用于视觉任务时,自注意力机制 (Self-Attention) 的计算复杂度随序列长度的大小呈二次方关系,给视觉任务的应用带来了挑战。各种各样的线性注意力机制 (Linear Attention) 的计算复杂度随序列长度的大小呈线性关系,可以提供一种更有效的替代方案。线性注意力机制通过精心设计的映射函数来替代 Self-Attention 中的 Softmax 操作,但是这种技术路线要么会面临比较严重的性能下降,要么从映射函数中引入额外的计算开销。
本文作者提出一种聚焦线性注意力机制 (Focused Linear Attention),力求实现高效率和高表达力。作者首先分析了是什么导致了线性注意力机制性能的下降?然后归结为了两个方面:聚焦能力 (Focus Ability) 和特征丰富度 (Feature Diversity),然后提出一个简单而有效的映射函数和一个高效的秩恢复模块来增强自我注意的表达能力,同时保持较低的计算复杂度。
1 Flatten Attention:聚焦的线性注意力机制构建视觉 Transformer
论文名称:FLatten Transformer: Vision Transformer using Focused Linear Attention (ICCV 2023)
论文地址:
http://arxiv.org/pdf/2308.00442.pdf
1.1 背景:现有线性注意力机制的不足之处
在将 Transformer 模型应用于视觉任务时,自注意力机制 (Self-Attention) 的计算复杂度随序列长度的大小呈二次方关系, 的计算复杂度在使用具有全局感受野的注意力机制时会导致较高的计算成本。
各种各样的线性注意力机制 (Linear Attention) 可以把计算复杂度从 降低到,使之随序列长度的大小呈线性关系,可以提供一种更有效的替代方案。Self-Attention 中的 Softmax 函数迫使所有的 Query 和 Key 之间成对计算,才导致了 的计算复杂度。
为了解决这个问题,之前的工作有一些尝试和探索:Performer [1]通过精心设计的核函数,使用正交随机特征逼近 Softmax 操作;SOFT[2]和 Nyströmformer [3]通过矩阵分解逼近完整的 Attention 矩阵。以上方法会引入额外的计算量。Efficient Attention[4]分别对 Query 和 Key 使用 Softmax 操作,自然确保了 的每一行总和为 1。
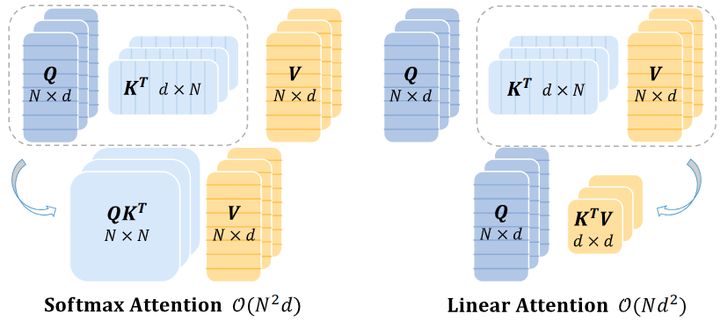
如下图1所示是标准的带 Softmax 的 Self-Attention 和 Linear Attention 的区别,其实最大的区别在于注意力机制的计算顺序上面,设输入 token 是 ,标准的带 Softmax 的 Self-Attention 的表达式可以写成:
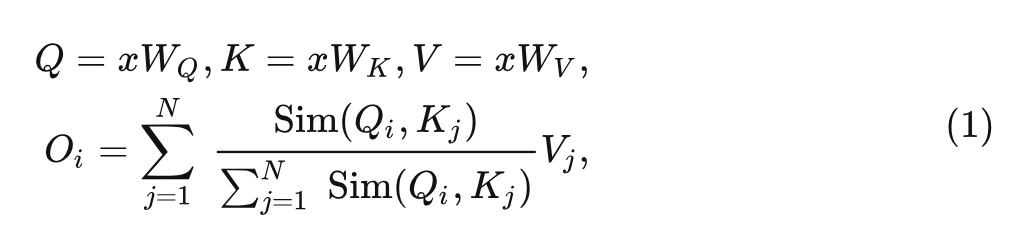
式中, 是投影矩阵, 是相似度计算的公式, Softmax Attention 机制使用的是 , 计算顺序是: (Query Key) Value, 这两步的计算复杂度都是 。因此, 简单地使用全局感受野的自我注意变得难以处理, 通常会导致计算成本过高。
Linear Attention 机制使用的相似度计算方法是:
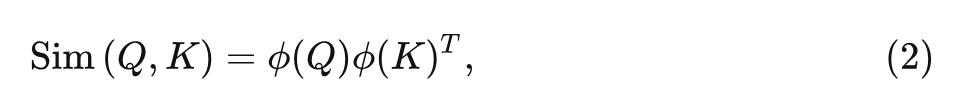
Self-Attention 就可以重写为:
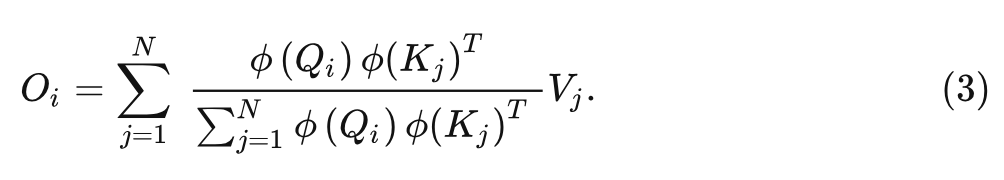
这样我们就可以把计算顺序从 (Query Key) Value 转化为 Query (Key Value):
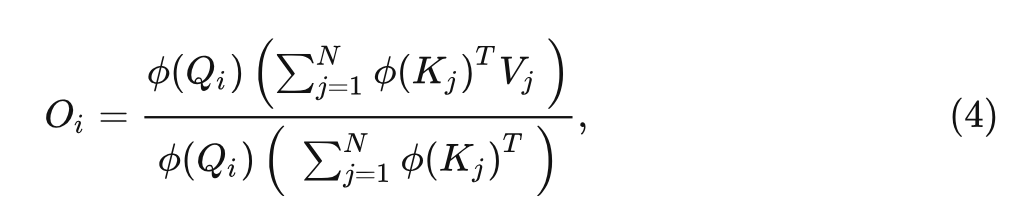
上式的计算复杂度是 。
但是,与 Softmax 注意力相比,当前的 Linear Attention 方法仍然存在严重的性能下降,并且可能涉及映射函数的额外计算开销,限制了它们的实际应用。
作者从两个角度分析了线性注意力的性能下降的原因,并提出了相应的解决方案。
Linear Attention 的注意力分布相对平滑,缺乏解决信息量最大的特征的聚焦能力。 Linear Attention 矩阵的秩相对较低,限制了特征多样性。
1.2 线性注意力机制的聚焦能力不够及其解决方案
Softmax Attention 实际上提供了一种非线性重新加权机制,这使得很容易聚焦于重要的特征。如下图1所示,可以看到 Softmax 注意力图的分布在某些区域 (如前景对象) 上比较集中,但是线性注意力图的分布却比较平滑,未能对包含更多信息的区域提供更有效的关注。

如何为线性注意力机制带来更多的聚焦能力?作者提出了一种聚焦线性注意力机制 (Focused Linear Attention),保留3式的计算方法,同时映射函数写成:
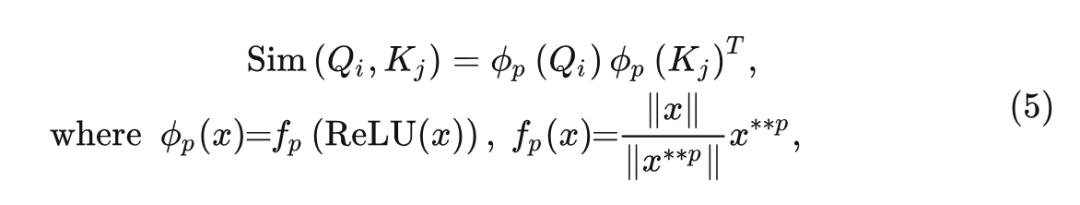
式中, 代表 的 次方, 作者遵循之前的线性注意模块首先使用 ReLU 函数来保证分母的输 入和有效性的非负性。映射之后不改变模长, 只改变向量的方向: 。
接下来通过下面的命题1展示出映射函数 实际上会影响注意力的分布:
命题1 ( 对注意力分布的影响)
令 ,假设 和 分别具有单个最大值 和 。对于一对 的特征 有:
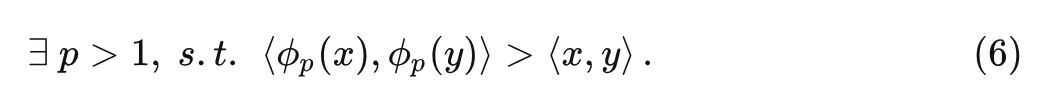
对于一对 的特征 有:
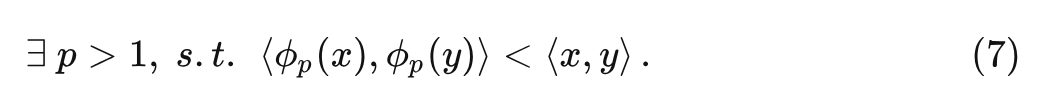
这个命题设计得很巧妙,它的意思是存在合适的 pp 值,满足:当两个向量的最大值在相同位置的时候, 可以让其相似性更高。当两个向量的最大值在不同位置的时候, 可以让其相似性更低。
具体的证明细节大家可以去参考原论文,这个命题希望满足: 当两个向量 Query 和 Key 比较相似时,可以让其相似性更高。当两个向量 Query 和 Key 不很相似时,可以让其相似性更低。
作者这里还给出了可视化的例子,如图2所示。黑色的向量代表 Query,其他几个彩色的向量代表不同的 Key。左图是 作用之前,有图是 作用之后的结果。可以看出,将每个向量朝着其最近的轴上拽了一段,提高每个组内的相似性,同时减少组之间的相似性。
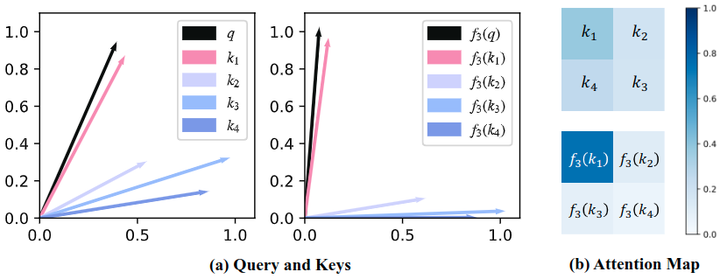
命题结论和可视化结果基本一致。
1.3 线性注意力机制的特征丰富度不够及其解决方案
除了焦点能力之外,特征多样性也是对线性注意力表达能力造成限制的因素之一。如下图3所示,以 DeiT-Tiny 中的一个 Transformer 层为例,可以看到 Self-Attention 是满秩矩阵,特征的多样性比较丰富。
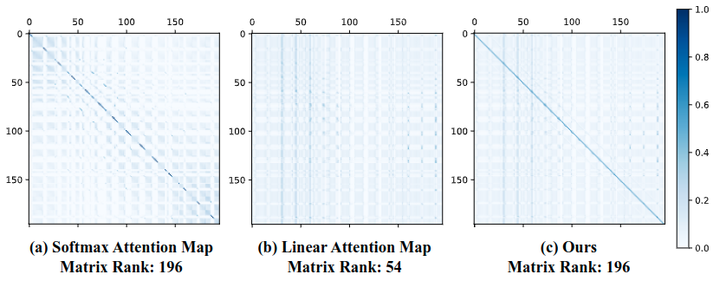
但是,在线性注意的情况下,满秩矩阵很难实现。因为 Linear Attention 的秩受下式的制约:
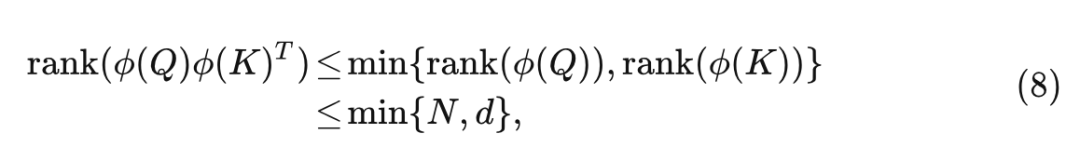
其中 通常小于 ,例如 DeiT 中的 ,这使得线性注意力矩阵被同质化。注意力权重的均匀化不可避免地导致聚合特征之间的相似性。
作为补偿,本文提出一种简单而有效的解决方案来解决线性注意的这种限制。具体来说,在注意力矩阵中添加了一个深度卷积 (Depth-Wise Convolution, DWC) 模块,输出可以表示为:
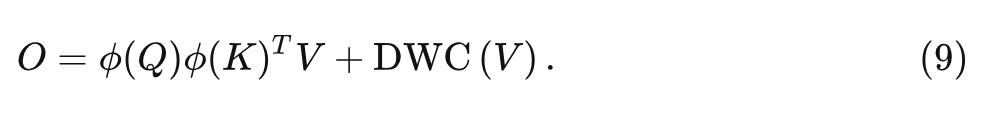
这个 DWC 模块可以被视为是一种补偿的注意力机制,其中的每个 Query 只会关注空间中的几个相邻特征,而不是所有特征 Value。即使当对于某个 Query 的 Key 值差不多的情况下,仍然可以从不同的局部特征中获得不同输出,从而保持特征的多样性。DWC 的效果也可以从矩阵秩的角度来解释:
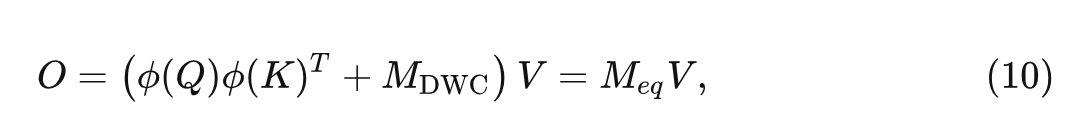
式中, 为与深度卷积函数对应的稀疏矩阵, 为等效的全注意图。由于 有可能是一个满秩矩阵, 所以实际上相当于是增加了等效注意力矩阵的秩上限, 且导致计算开销很小, 同时可以大大提高线性注意力的性能。
如上图3所示,使用额外的 DWC 模块,线性注意力中注意力图的排名可以恢复到满秩 196,提升了特征的多样性。
1.4 聚焦线性注意力机制
基于上面两节的分析,本文提出一种聚焦线性注意力机制,在保持表达能力的同时降低了计算复杂度,可以表述为:
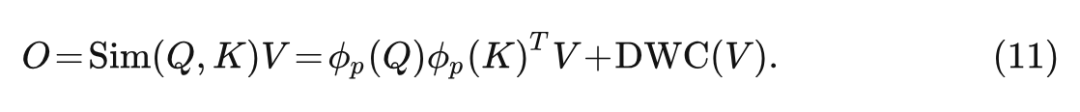
它有2个主要的优点:
计算复杂度很低,和线性注意力机制相当。
与前任设计的复杂核函数的线性注意模块相比,本文提出的聚焦函数只采用了简单的算子,以最小的计算开销实现了近似。
较高的表达能力,和 Softmax 注意力一致。
前人的基于核函数的线性注意力设计通常不如 Softmax Attention。通过本文所提出的聚焦函数和深度卷积,聚焦线性注意力机制可以实现比 Softmax Attention 更好的性能。
1.5 实验结果
ImageNet-1K 图像分类
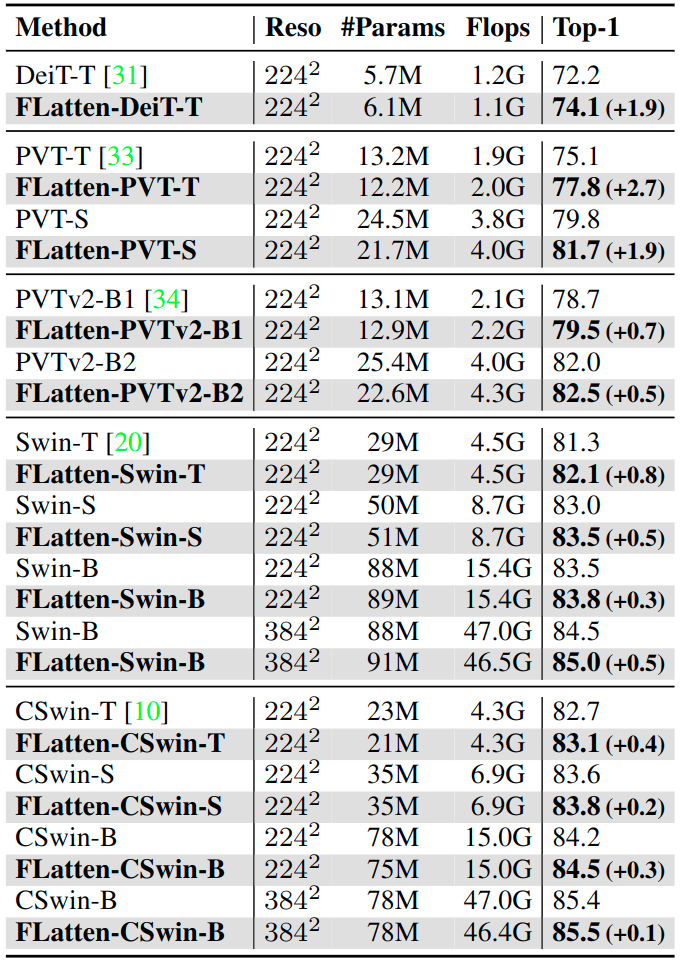
实验结果如下图4所示,本文方法在差不多的 FLOP 或 Params 下与基线模型实现了一致的改进。比如,FLatten-PVT-T/S 在相似的 FLOP 下分别比 PVT-T/S 高出 2.7% 和 1.9%。基于 Swin,本文模型实现了与 60% FLOPs 相当的性能。这些结果说明 Flatten 方法对不同模型具有泛化能力。
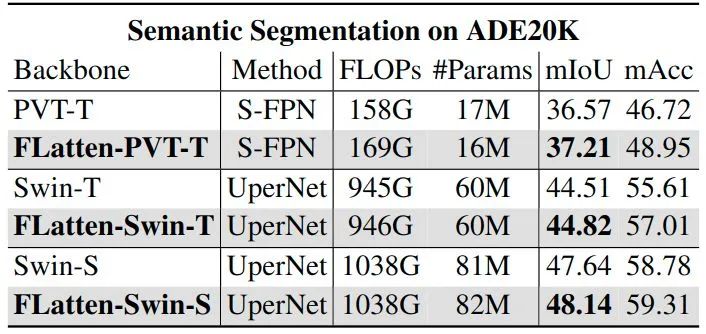
ADE20K 语义分割
实验结果如下图5所示,本文在两个具有代表性的分割模型 SemanticFPN 和 UperNet 上使用 Flatten 方法。如表中所示。如图 1 所示,我们的模型在所有设置下都取得了始终更好的结果。具体来说,我们可以看到 0.5 ∼ 1% mIoU 的改进,计算成本和参数相当。mAcc 的改进更加显著。
COCO 目标检测
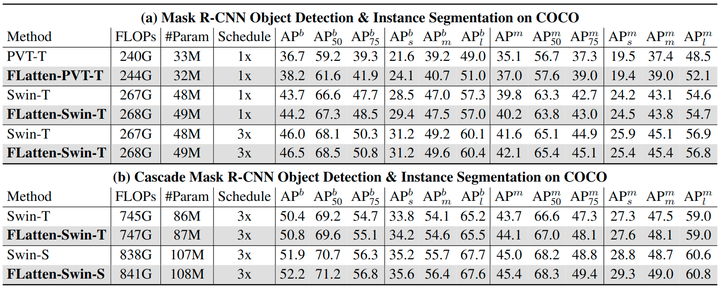
实验结果如下图6所示,作者使用 ImageNet 预训练模型和 Mask R-CNN 和 Cascade Mask R-CNN 检测头框来评估有效性,在不同检测头的 1x 和 3x schedule 设置下进行了实验。结果显示,利用更大的感受野,带有 Flattened Attention 的模型在所有设置下都显示出更好的结果。
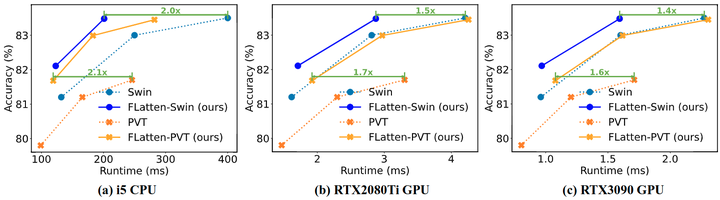
推理时间
作者进一步评估了模型的实际效率,并将其与两个竞争 Baseline 进行比较,结果如图7所示。作者测试了多个硬件平台上的推理延迟,包括桌面 CPU (Intel i5-8265U) 和两个服务器 GPU (RTX2080Ti 和 RTX3090)。可以看到,带有 Flattened Attention 的模型在 CPU 和 GPU 的运行时和准确性之间实现了更好的权衡,推理速度高达 2.1 倍,性能相当甚至更好。
参考
^Rethinking Attention with Performers ^SOFT: Softmax-free Transformer with Linear Complexity ^Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention ^Efficient Attention: Attention with Linear Complexities
其它文章
入门必读系列(十六)经典CNN设计演变的关键总结:从VGGNet到EfficientNet
从零搭建Pytorch模型教程(三)搭建Transformer网络
从零搭建Pytorch模型教程(四)编写训练过程--参数解析
从零搭建Pytorch模型教程(五)编写训练过程--一些基本的配置
从零搭建pytorch模型教程(八)实践部分(一)微调、冻结网络
从零搭建pytorch模型教程(八)实践部分(二)目标检测数据集格式转换
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢