
作者:天数智芯
「FlagPerf是智源联合各大AI软硬件厂商建立的开源、开放、灵活、公正、客观的面向多种AI硬件的一体化评测引擎,可快速高效地对AI软硬件进行适配和评测,解决当前AI软硬件所面临的兼容性差、技术栈异构程度高、应用场景复杂多变等挑战。目前FlagPerf已经适配了涵盖CV、NLP、语音、大模型等领域的近20个经典模型,支持评测AI硬件的训练和推理能力,未来还将持续拓展支持模型数量和评测领域,包括不限于AI服务器、图计算等各个场景,期望全面、立体地刻画厂商的的软硬件实力,并通过不断迭代评测体系,紧跟AI产业发展浪潮。」
1. 天数智芯产品介绍
1.1 公司介绍
上海天数智芯半导体有限公司(简称“天数智芯”)是中国第一家通用GPU高端芯片及超级算力系统提供商。公司致力于开发国产化、国际领先的高性能通用GPU产品,探索通用GPU赶超发展道路,加快建设自主产业生态,已先后发布并量产了用于云端训练的“天垓100芯片”和用于云边推理的“智铠100芯片”,实现了国内通用GPU芯片从0到1的突破,打破了国外厂商对通用GPU产品的垄断,为全产业提供高端算力解决方案。
1.2 产品介绍
2020年12月,天数智芯全自研云端训练通用GPU芯片——“天垓100芯片”成功点亮,这标志着国内第一款全自研、GPU架构下的云端训练芯片正式问世,并于与2021年9月份正式商用量产。 2022年5月,天数智芯再次成功点亮7纳米通用GPU推理芯片——智铠100,自此天数智芯成为国内唯一同时拥有GPU架构下云端训练+推理完整解决方案的硬科技公司。 2022年9月,天数智芯发布了国内首个通用计算应用开发及评测平台——DeepSpark,通过分享与落地应用深度耦合的百大算法,并针对行业需求构建多维度测评体系,广泛支持各类落地场景,助力我国计算产业生态打造。
天数智芯通用GPU芯片产品具有应用覆盖广、性能可预期、开发易迁移以及全栈可定制的产品特点。实现了多维度技术创新,具备自主可控、高性能、通用性、灵活性等特点,其系统架构、指令集、核心算子、软件栈均为自主研发,不走购买国外GPU IP的捷径,可独立发展演进。适配主流CPU、操作系统和服务器厂商,能够支持国内外主流AI生态和各种深度学习框架,并通过标准化的软硬件生态接口为行业解决产品使用难、开发平台迁移成本大等痛点,大幅缩短适配验证周期,使客户业务系统几乎无感知地适用天数智芯通用GPU产品。天数智芯的通用GPU训练产品已支撑百余个客户在人工智能领域进行超过两百个不同种类模型训练,广泛支持传统机器学习、数学运算、加解密及数字信号处理等领域。
天垓100芯片采用通用GPU架构,7纳米制程及2.5D COWOS封装技术,容纳240亿晶体管,支持FP32,FP16,INT8等多精度数据混合训练。兼容多种主流服务器和主流软件生态,可助力客户实现无痛系统迁移。天数智芯加速卡的产品可提供灵活的编程能力,超强的性能及富有吸引力的性价比,可广泛应用于人工智能,通用计算,新算法研究等场景,服务于智算中心,互联网,金融,教育,医疗及安防等各相关行业,赋能AI智能社会。智铠100芯片基于天数智芯第二代通用GPU架构,实现了指令集增强、算力密度提升、计算存储再平衡,支持多种视频规格解码、国内外主流深度学习开发框架,拥有丰富编程接口拓展和高性能函数库,可以灵活支持各种算法模型,便于客户自定义开发。相较于市场上现有主流产品,可提供2-3倍的实际使用性能。
2. 实践详细步骤
2.1 ResNet50模型概述
图像分类是最基础的计算机视觉应用,属于有监督学习类别,如给定一张图像(猫、狗、飞机、汽车等等),判断图像所属的类别。
ResNet 残差网络 (Residual Network)是一种特定类型的卷积神经网络 (CNN),由何凯明、张翔宇、任少卿和孙剑在 2015 年的论文《Deep Residual Learning for Image Recognition》中提出。 ResNet网络提出了残差网络结构(Residual Network)来减轻退化问题,使用ResNet网络可以实现搭建较深的网络结构。
ResNet50作为ResNet的一个典型代表, 是一个 50 层的卷积神经网络(48 个卷积层、一个 MaxPool 层和一个平均池化层),在工业界应用相当广泛。
2.2 具体步骤
step1 软件栈安装
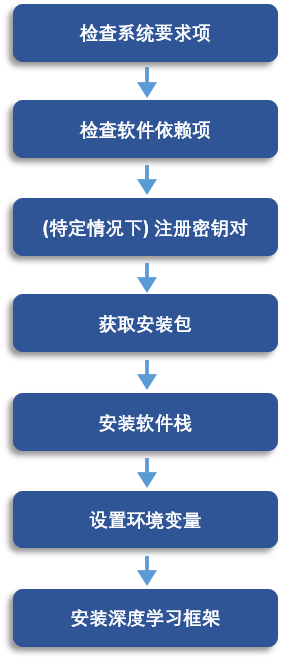
图1: 在宿主机上安装天数软件栈流程
在宿主机上安装天数软件栈流程如上图所示,首先联系您的应用工程师获取x86版本SDK安装包,在宿主机上使用corex installer安装包安装软件栈,该软件栈包含包括天数智芯加速卡驱动、函数库、 编译器、ixSMI、ixPROF、ixKN、 ixSYS、ixGDB等工具。
再使用*.whl包安装天数智芯适配版torch深度学习框架、相关领域库和加速库。
安装完成后,执行 ixsmi 可以看到加速卡型号BI-V100、SDK软件栈版本等GPU相关信息,执行pip list可以看到torch和相关领域库。
如果有不清楚之处,如前置条件、ubuntu/centos系统版本等软件栈安装细节信息可进一步参考天数官网文档(https://support.iluvatar.com/#/DocumentCentre?id=1&nameCenter=1&productId=381380977957597184)
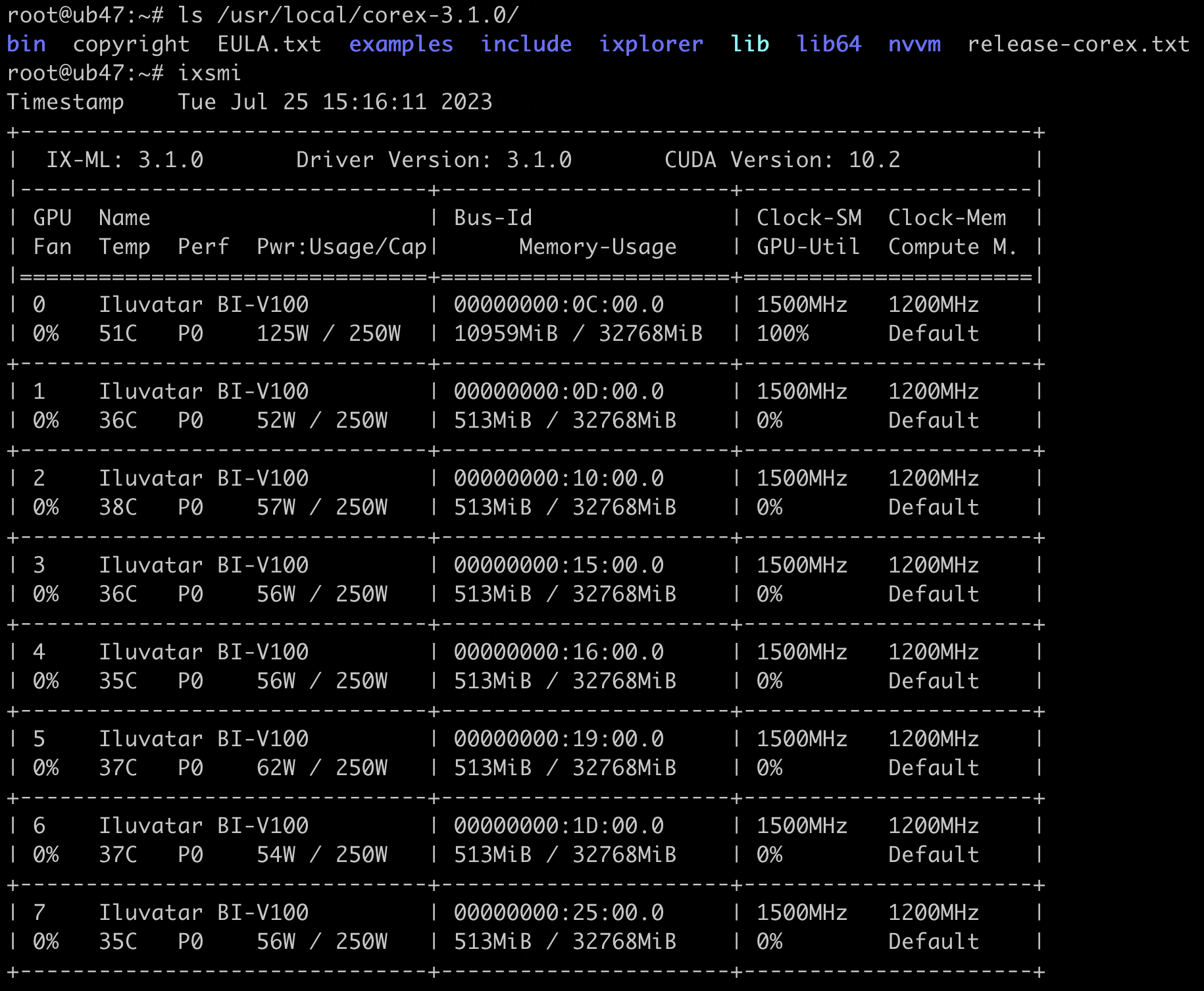
图2: 天数BI-V100 GPU信息
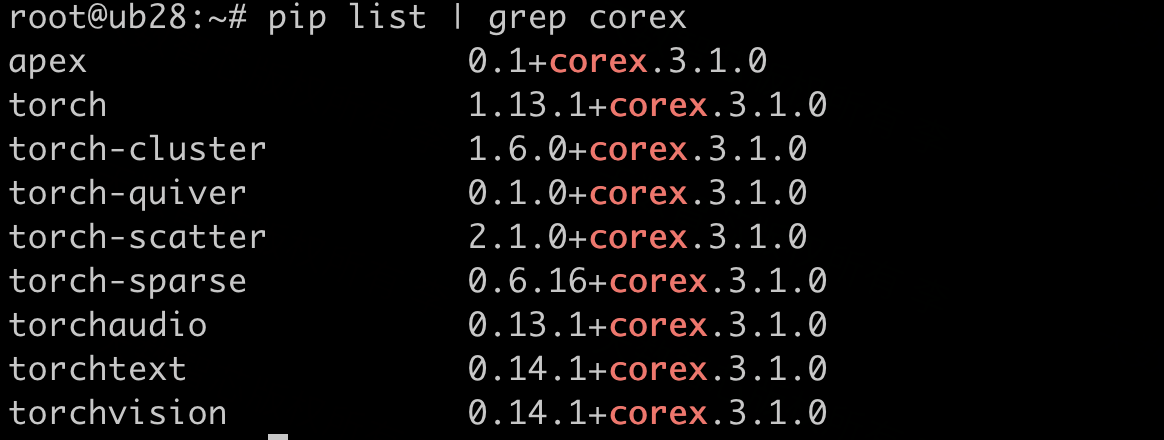
图3: torch及相关领域库
step2 添加天数适配case配置代码
可以在源码中看到标准benchmark中已经实现了dataloader、model等关键模块:
resnet50/pytorch/
├── config
├── dataloaders
├── model
├── optimizers
├── run_pretraining.py
├── schedulers
└── train适配需要新增目录training/iluvatar/resnet50-pytorch,在其中新增config、extern目录,csrc目录作用是放厂商扩展程序,天数适配的resnet50目前没有用到这个文件夹。resnet50 训练的主要参数配置在training/benchmarks/resnet50/pytorch/config/_base.py中已经指定,同目录下mutable_params.py中列出了厂商可替换参数,适配时仅需在training/iluvatar/resnet50-pytorch文件夹下创建配置文件:
1)新增单机8卡训练配置文件training/iluvatar/resnet50-pytorch/config/config_BI-V100x1x8.py,指定训练学习率 lr、train_batch_size、eval_batch_size等关键参数。

2)单机单卡配置config_BI-V100x1x1.py、2 机16 卡配置config_BI-V100x2x8.py同上。
step3 调整天数case测试配置文件
切换到目录run_benchmarks/config,修改训练测试配置信息:
VENDOR = "iluvatar"
ACCE_CONTAINER_OPT = " -v /lib/modules:/lib/modules "
FLAGPERF_PATH = "/path/to/your/flagperf/training"修改CASE内容,指定配置文件、训练框架_版本、GPU型号、节点数以及训练数据目录,例如:
CASES = {
"resnet50:pytorch_1.8:BI-V100:1:8:1": "/data/workspace/datasets/mobilenetv2/imagenet",
}step4 新增性能监控脚本,启动训练
在training/iluvatar目录下新增监控脚本iluvatar_monitor.py,用以在测试的过程中去监控系统和天数BI-V100的各项性能指标,包括cpu info、memory、power、GPU info等,成功启动训练后,在results对应的目录中可以看到监控的log日志文件。
── cpu_monitor.log
├── iluvatar_monitor.log
├── mem_monitor.log
├── pwr_monitor.log
├── rank0.out.log
├── rank1.out.log
├── rank_n.out.log......
└── start_pytorch_task.log按照上述步骤,准备好ImageNet数据集和相应的软硬件环境之后,切换到FlagPerf/training目录,启动训练 nohup python3 run_benchmarks/run.py & ,在training/results目录下观察日志输出是否正常。
step5 记录训练结果信息
可以在result对应目录下的日志中看到框架对应镜像的构建,容器启动、环境准备的过程,run_pretraining.py被启动执行并输出日志,训练完成后,根据rank0.out.log中的输出结果信息,在README.md填写性能测试数据,至此就完成了Flagperf框架下天数适配版ResNet50的训练流程。
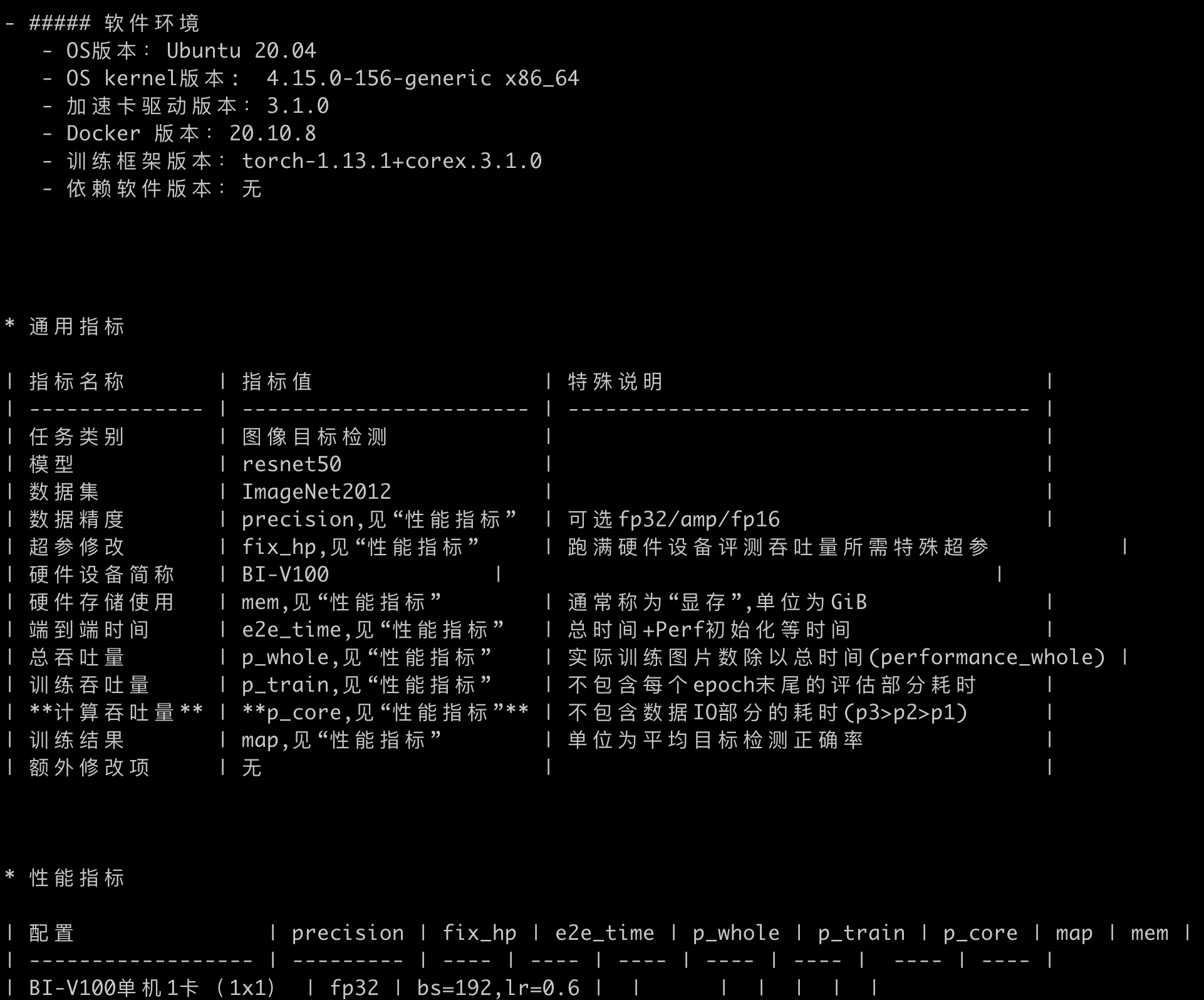
目前,天数智芯已经基于FlagPerf完成了多个模型的训练适配工作,随着 FlagPerf框架的逐渐完善和迭代升级,厂商适配过程更加顺畅,开发工作量更小,易用性也更强。
适配完成之后,通过 FlagPerf 这一公平、实用的平台,得到的模型评测结果是可复测的,除了向客户提供性能参考数据,也能给天数进行产品把控提供数据支撑,帮助天数这类 GPGPU 厂商明确产品优势和未来迭代方向,助力国产芯片蓬勃发展。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢