【新智元导读】参数高效的微调方法SUR-adapter,可以增强text-to-image扩散模型理解关键词的能力。
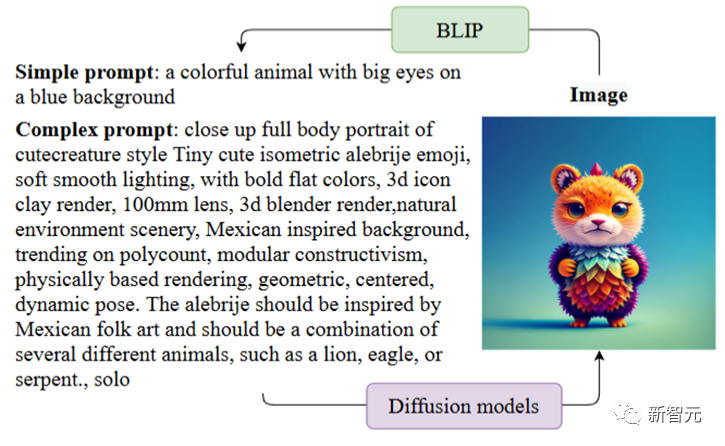
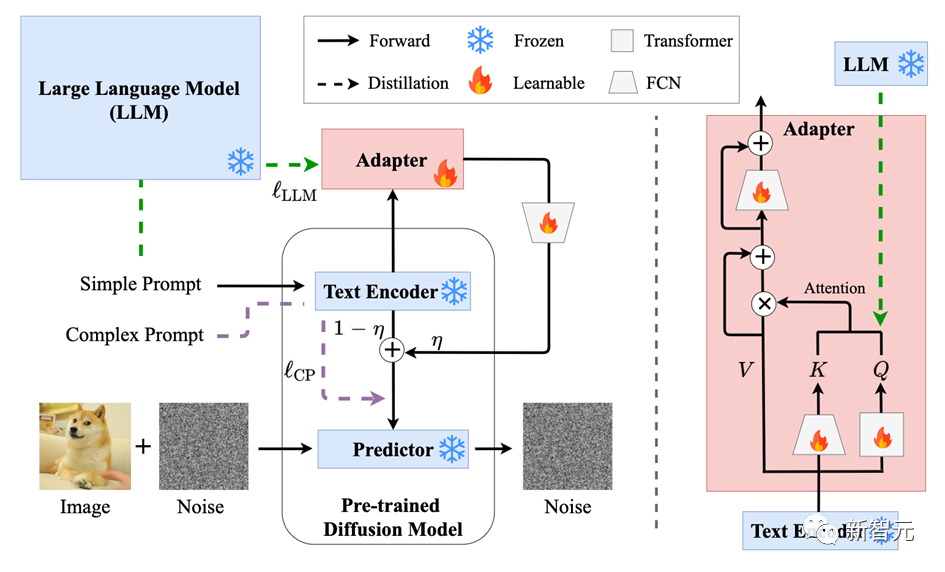
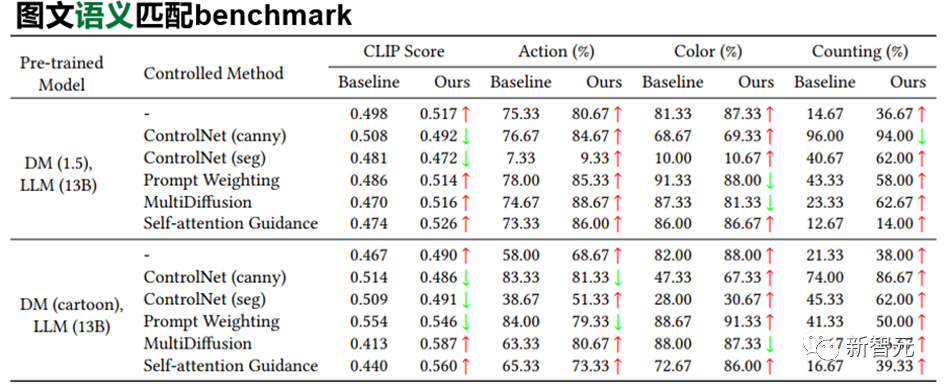
扩散模型已经成为了主流的文本到图像生成模型,可以基于文本提示的引导,生成高质量且内容丰富的图像。但如果输入的提示过于简洁,现有的模型在语义理解和常识推理方面都存在局限,导致生成的图像质量下降明显。为了提高模型理解叙述性提示的能力,中山大学HCP实验室林倞团队提出了一种简单而有效的参数高效的微调方法SUR-adapter,即语义理解和推理适配器,可应用于预训练的扩散模型。论文地址:https://arxiv.org/abs/2305.05189开源地址:https://github.com/Qrange-group/SUR-adapter为了实现该目标,研究人员首先收集并标注了一个数据集SURD,包含超过5.7万个语义校正的多模态样本,每个样本都包含一个简单的叙述性提示、一个复杂的基于关键字的提示和一个高质量的图像。 然后,研究人员将叙事提示的语义表示与复杂提示对齐,并通过知识蒸馏将大型语言模型(LLM)的知识迁移到SUR适配器,以便能够获得强大的语义理解和推理能力来构建高质量的文本语义表征用于文本到图像生成。通过集成多个LLM和预训练扩散模型来进行实验,结果展现了该方法可以有效地使扩散模型理解和推理简洁的自然语言描述,并且不会降低图像质量。该方法可以使文本到图像的扩散模型更容易使用,具有更好的用户体验,可以进一步推进用户友好的文本到图像生成模型的发展,弥补简单的叙事提示和复杂的基于关键字的提示之间的语义差距。目前,以Stable diffusion为代表的文生图 (text-to-image)预训练扩散模型已经成为目前AIGC领域最重要的基础模型之一,在包括图像编辑、视频生成、3D对象生成等任务当中发挥着巨大的作用。然而目前的这些预训练扩散模型的语义能力主要依赖于CLIP等文本编码器 (text encoder),其语义理解能力关系到扩散模型的生成效果。本文首先以视觉问答任务(VQA)中常用问题类别的"Counting (计数)", "Color (颜色)"以及"Action (动作)"构造相应的本文提示来人工统计并测试Stable diffusion的图文匹配准确度。结果如下表所示,文章揭示了目前文生图预训练扩散模型有严重的语义理解问题,大量问题的图文匹配准确度不足50%,甚至在一些问题下,准确度只有0%。因此,需要想办法增强预训练扩散模型中本文编码器的语义能力以获得符合文本生成条件的图像。首先从常用的扩散模型在线网站lexica.art,civitai.com,stablediffusionweb中大量获取图片文本对,并清洗筛选获得超过57000张高质量 (complex prompt, simple prompt, image) 三元组数据,并构成SURD数据集。如图所示,complex prompt是指生成image时扩散模型所需要的文本提示条件,一般这些文本提示带有复杂的格式和描述。simple prompt是通过BLIP对image生成的文本描述,是一种符合人类描述的语言格式。一般来说符合正常人类语言描述的simple prompt很难让扩散模型生成足够符合语义的图像,而complex prompt(对此用户也戏称之为扩散模型的“咒语”)则可以达到令人满意的效果。本文引入一个transformer结构的Adapter在特定隐含层中蒸馏大语言模型的语义特征,并将Adapter引导的大语言模型信息和原来文本编码器输出的语义特征做线性组合获得最终的语义特征。其中大语言模型选用的是不同大小的LLaMA模型。扩散模型的UNet部分在整个训练过程中的参数都是冻结的。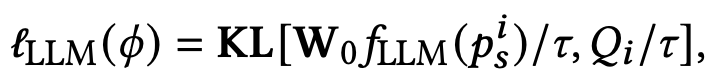
由于本文结构在预训练大模型推理过程引入了可学习模块,一定程度破坏了预训练模型的原图生成质量,因此需要将图像生成的质量拉回原预训练模型的生成质量水平。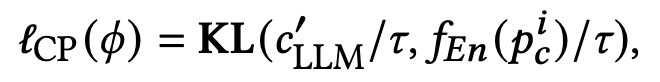
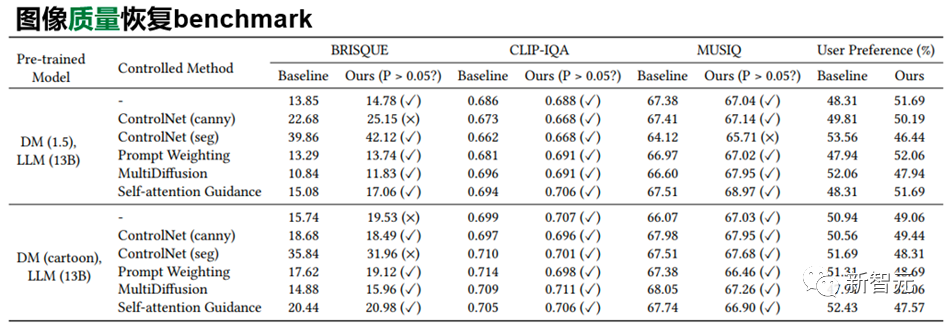
本文利用SURD数据集中的三元组在训练中引入相应的质量损失函数以恢复图像生成质量,具体地,本文希望simple prompt通过新模块后获得的语义特征可以和complex prompt的语义特征尽可能地对齐。下图展示了SUR-adapter对预训练扩散模型的fine-tuning框架。右侧为Adapter的网络结构。 本文从语义匹配和图像质量两个角度来看SUR-adapter的性能。一方面,如下表所示,SUR-adapter可以有效地在不同的实验设置下缓解了文生图扩散模型中常见的语义不匹配问题。在不同类别的语义准则下,准确度有一定的提升。另一方面,本文利用常用的BRISQUE等常用的图像质量评价指标下,对原始pretrain扩散模型和使用了SUR-adapter后的扩散模型所生成图片的质量进行统计检验,我们可以发现两者没有显著的差异。以上分析说明,所提出的方法可以在保持图像生成质量的同时,缓解固有的预训练text-to-image固有的图文不匹配问题。另外我们还可以定性地展示如下图所示的图像生成的例子,更详细的分析和细节请参见本文文章和开源仓库。中山大学人机物智能融合实验室 (HCP Lab) 由林倞教授于 2010 年创办,近年来在多模态内容理解、因果及认知推理、具身智能等方面取得丰富学术成果,数次获得国内外科技奖项及最佳论文奖,并致力于打造产品级的AI技术及平台。
https://arxiv.org/abs/2305.05189
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
经典GAN不得不读:StyleGAN
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!
内容中包含的图片若涉及版权问题,请及时与我们联系删除








 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
评论
沙发等你来抢