
今天是8月30日,中元节,北京,天气晴。
在小时候,中元节这天的晚上,抬头看月亮,会有小鬼划船经过月亮的一幕,所以,各家各户都会在河边寄快递,很有意境的回忆。
我们今天继续来看看大模型实践过程中地一些有趣的工作。
本文将讲述两个话题,一个是对torch显存分析,并探索如何在不关闭进程的情况下释放显存地方法。另一个是通过几种策略来使用Llama-2进行中文对话。
里面的思路都很有参考意义,供大家一起参考。
一、几种策略使用原生Llama-2进行中文对话
现有的很多项目,在开源的Llama-2基础上,进行了中文场景的训练,然而Llama-2本身就具有多语种的能力,理论上是可以直接运用于中文场景的。
本文所举例使用的模型为Llama-2-7b-chat-hf。
1、利用prompt
首先可以想到的是,使用prompt。可是即便是在prompt中添加了要求模型回答中文的提示,模型仍然回答的是英文。
从对话内容可以看到,模型可以理解用户的问题,却没有输出中文:
>> '你好'
>> "Hello! 😊 I'm here to help answer any questions you may have. Is there something specific you'd like to know or discuss? Please feel free to ask, and I'll do my best to assist you. 🤖"
2、利用Logit Processor
在之前的文章中我们有介绍过,在生成模型中使用自定义LogitsProcessor中怎样使用logits processor来改变生成过程中的概率,进而改变生成的结果。
那么可以直接想到的是,把tokenizer中所有中文字符的概率调大一些,就可以强行要求模型生成中文了。
首先利用unicode范围获取常见的汉字:
import re
def is_chinese(word):
"""
判断一个字符串是否为汉字
"""
if re.match('[\u4e00-\u9fff]', word):
return True
else:
return False
CHINESE_TOKEN_IDS = [token_id for token, token_id in tokenizer.vocab.items() if is_chinese(token)]
然后就可以实现一个processor来提高这些token对应的概率:
rom transformers.generation.logits_process import LogitsProcessor, LogitsProcessorList
class ChineseLogitsProcessor(LogitsProcessor):
"""
生成中文字符
---------------
ver: 2023-08-02
by: changhongyu
"""
def __init__(self,
chinese_token_id_list: List[int] = None,
alpha: float = 5):
"""
:param chinese_token_id_list: 中文token的token的id列表
:param alpha: 放大倍数
"""
self.chinese_token_id_list = chinese_token_id_list
self.alpha = alpha
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
for id_ in self.chinese_token_id_list:
scores[:, id_] *= self.alpha
return scores
在生成之前,创建processor:
logits_processor = LogitsProcessorList()
logits_processor.append(ChineseLogitsProcessor(CHINESE_TOKEN_IDS))
然而,模型却生成起来停不下了。这是因为没有将EOS token的概率也做相应的放大,我们改之。
CHINESE_TOKEN_IDS.append(tokenizer.eos_token_id)
这下,模型可以输出中文了:
>> '你好'
>> '好的好的大家好的我是一个智能问题机器人我可以回应你的问题请问你有任何问题或需要我的服务'
可是看起来好像哪里怪怪的,原来是没有标点。既然没有标点,那我们再把标点符号的概率也放大就好了:
puncs = [',', '。', '?', '!', '“', '”', ':', ',', '.', '?', '!', '"', "'", ':']
CHINESE_TOKEN_IDS = [token_id for token, token_id in tokenizer.vocab.items() if is_chinese(token)]
CHINESE_TOKEN_IDS.extend(tokenizer.convert_tokens_to_ids(puncs))
CHINESE_TOKEN_IDS.append(tokenizer.eos_token_id)
现在,eos也有了,标点符号也有了,然而还是出意外了:
>> '你好'
>> '::你好!我是一个智能问题机器人,我的任务是回应用户的问题。请问你有任何问题?'
现在模型倒是可以说中文,也带标点了,但标点出现在了最开头。这样的话,我们可以再添加一个processor,不让这些标点出现在最开始就可以了。
class SuppressSpecificBOSTokenLogitsProcessor(LogitsProcessor):
"""
防止生成的第一个token是某些特定的token
---------------
ver: 2023-08-02
by: changhongyu
"""
def __init__(self, bad_bos_token_id_list: List[int] = None):
"""
:param bad_bos_token_id_list: 不可以作为第一个token的token的id列表
"""
self.bad_bos_token_id_list = bad_bos_token_id_list
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
new_token_len = input_ids.shape[-1] - current_token_len
if new_token_len == 0:
for id_ in self.bad_bos_token_id_list:
scores[:, id_] = -float('inf')
return scores
将两个processor放在一起:
logits_processor = LogitsProcessorList()
logits_processor.append(ChineseLogitsProcessor(CHINESE_TOKEN_IDS))
logits_processor.append(SuppressSpecificBOSTokenLogitsProcessor([tokenizer.convert_tokens_to_ids(punc) for punc in puncs]))
终于,可以让模型实现中文对话了:
>> '你好'
>> '好的,好的!你好!对不起,我不知道你问的问题,请问你想问些事情?'
虽然回答的还是有点奇怪,但使用中文与模型进行对话的目的,也的的确确是达到了。
二、如何在不关闭进程的情况下释放显存
一直以来,对于torch的显存管理,我都没有特别注意,只是大概了解到,显存主要分为几个部分(cuda context、模型占用、数据占用),然而在接触大模型之后,遇到越来越多的显存合理利用的问题,尤其是利用大模型进行推理时,怎样规划好一个进程的显存占用,是一件非常重要的事情。
本文就近期针对torch显存管理的工作进行整理总结,主要目的就是解决一个问题——如何在不关闭进程的情况下释放显存。
1、 基本概念——allocator和block
首先需要了解两个基本概念,allocator与block。
Allocator是torch用来管理显存的工具,以下是chatgpt的解释:
在PyTorch中,allocator是用于动态分配内存的抽象接口。 PyTorch使用allocator来分配张量所需的内存,并使用该内存来存储张量的数据和元数据。 这使得PyTorch能够管理内存的使用,避免内存泄漏和浪费,并最大化系统的使用效率。
而block可以理解为显存中的若干分区,这些分区有大有小,torch将tensor从cpu移动到gpu上,实际上是将tensor移动到某个block上。
根据我的理解,可以将相关的要点总结如下:
从功能上讲,allocator是torch用来获取和管理block的工具,torch通过allocator从gpu获取到所需要的block,然后将所有获取到的block放在一个block pool中; 当需要将某个tensor放到gpu上时,会将其放在其中一个block上; tensor不能分割开,放在不同的block,例如一个6Mb的tensor,会要求一个大于等于6Mb的block,而无法将其分散在2个4Mb的block上;
一般情况下,torch不会主动去释放掉block,当一个tensor不再使用时,其所占用的block仍然处在block pool中,此时查看进程所占用显存,不会出现下降; 当又有一个tensor需要放在gpu上时,会优先检查block pool中,是否存在可以放得下这个tensor的block,如果有,则有限使用这个block,如果没有,则allocator会再尝试向显卡申请其他block,如果显卡上也没有符合条件的空闲block,则程序就会报OOM; 可以利用torch.cuda.empty_cache方法,手动释放掉未被占用的block,但是会造成程序运行变慢。
2、torch.cuda的三大常用方法
我在学习torch的显存管理时,参考了这篇文章,其中很具体的介绍了torch显存管理的三个常用的方法,这里不再重复详细的介绍,仅将其作用简单介绍如下:
torch.cuda.memory_allocated():查看当前tensor占用的显存
torch.cuda.memory_reserved():查看进程占用的总共的显存
torch.cuda.empty_cache():释放掉未使用的缓存
除了参考文章中所介绍的三个常用方法,这里再补充另一个比较实用的方法,查看显存占用的方法:torch.cuda.memory_stats(),可以查看当前显存的更加具体的占用情况。
具体说明可以参考:https://pytorch.org/docs/1.13/generated/torch.cuda.memory_stats.html#torch.cuda.memory_stats
看起来一切都很合理,当我需要释放block pool中没有被使用到的block,还给gpu时,就调用torch.cuda.empty_cache()方法即可。但问题偏偏就出在这里,当我们执行这一行指令的时候,显存真的会像所想的那样被释放吗?
3、可以释放的显存
为了分析和验证显存占用情况的机制,我做了一个简单的实验。
实验只考虑推理阶段,所以所有的代码是在torch.no_grad()模式下进行的,这种模式下不会保存中间变量和梯度,所以显存的占用=模型参数占用+输入数据占用+输出结果占用。
完成这个实验,只需要一个for循环即可,通过逐渐增加输入的长度,来观察显存的变换情况:
以chatGLM-6B为代表进行实验,用一个列表来存储每一个时刻的显存信息
points = []
for cur_len in tqdm(range(0, 6000, 10)):
# 输入序列的长度从0,10,20,...,一直增长到OOM为止
real_inputs = inputs['input_ids'][..., : cur_len, ...].to(model.device)
# 开始阶段记录两个数值,分别是将inputs放在卡上之后的当前tensor占用,和总占用,单位是Mb
points.append([cur_len, torch.cuda.memory_allocated() / 1024 / 1024, torch.cuda.memory_reserved() / 1024 / 1024])
# 开始推理
with torch.no_grad():
# 计算logits,tail是chatGLM的tokenizer中的特殊token 150001和150004
logits = model(torch.cat([real_inputs, tail], 1))
# 推理结束后记录此时的显存状态
points[-1].extend([torch.cuda.memory_allocated() / 1024 / 1024, torch.cuda.memory_reserved() / 1024 / 1024])
根据前文的分析,显存的占用总量,应当是以阶梯式的情况进行增长的,当当前的block pool中的block不足以满足使用时,torch通过allocator获取到新的block,此时显存占用的总值上升一个阶梯,如下图:
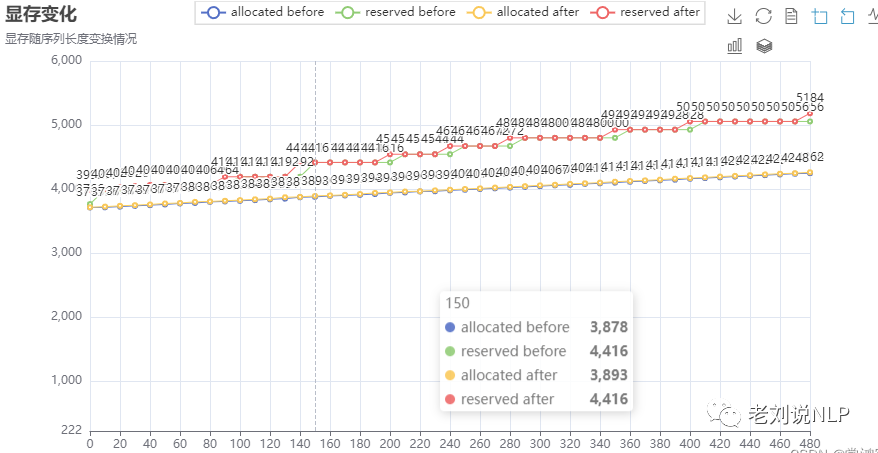
然而,实际情况是,随着序列长度的增加,显存的累计占用出现了激增,并且反复震荡,直到收敛到OOM的界值,程序报错退出:
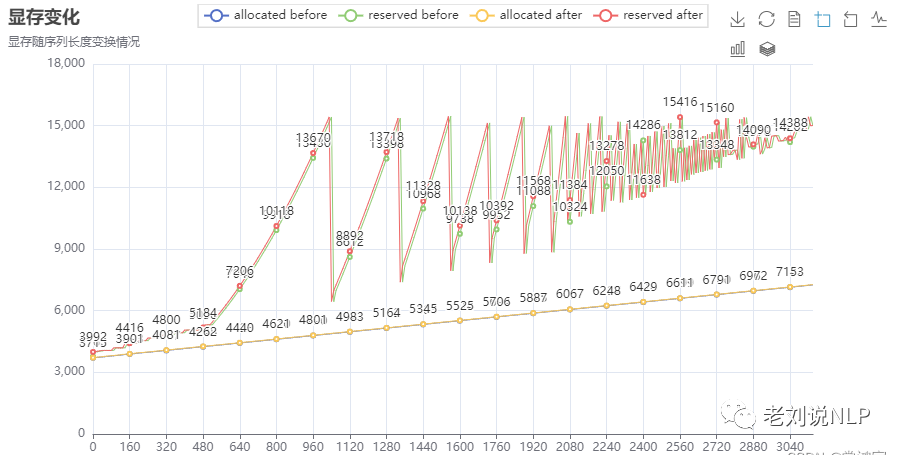
造成这种现象的原因我并不清楚,或许是torch本身就是设计了这样的机制。
那么,如果我们每次执行完一次计算,都利用torch.cuda.empty_cache()将缓存释放掉呢?于是在上面代码的基础上,我做了简单的修改:
for cur_len in tqdm(range(0, 6000, 10)):
real_inputs = inputs['input_ids'][..., : cur_len, ...].to(model.device)
points.append([cur_len, torch.cuda.memory_allocated() / 1024 / 1024, torch.cuda.memory_reserved() / 1024 / 1024])
with torch.no_grad():
logits = model(torch.cat([real_inputs, tail], 1))
points[-1].extend([torch.cuda.memory_allocated() / 1024 / 1024, torch.cuda.memory_reserved() / 1024 / 1024])
# 加了这一句
torch.cuda.empty_cache()
也就是说,每次计算完一次logits后,把缓存区清空,这样一来,在进入到下一轮次循环的时候,记录下来的累计占用显存(绿色曲线),就是清空缓存之后的情况。于是得到了这样的结果:
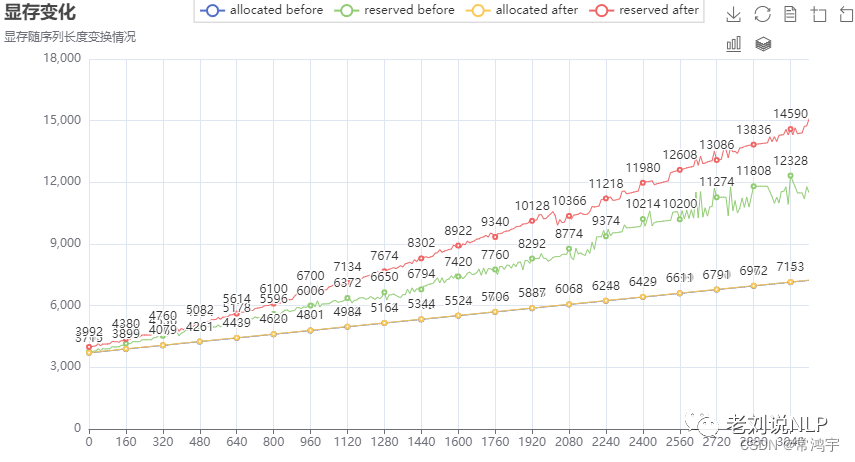
从图中可以看到,此时的显存占用曲线,基本是呈线性增长的,而红色曲线和绿色曲线之间的差值,就是在计算logits的过程中,allocator额外向gpu申请的block中,没有被利用的部分,换句话说,allocator取多了的部分。
所以,从图中可以很直观地看出,这部分显存,的的确确是可以通过利用torch.cuda.empyt_cache()来释放掉的。
对比上面的两张图,可以发现,在没有手动释放显存之前的曲线,将其各个“极小值点”相连,大概是可以跟手动释放显存之后的曲线相重合的。
此外,通过拟合后图中的红色曲线,可以预估显存占用随序列长度变化的规律大概为: M e m C o s t = 1.13 ∗ S e q L e n + 3717 MemCost = 1.13 * SeqLen + 3717 MemCost=1.13∗SeqLen+3717
单位为Mb。
而3717就是模型参数与CUDA context占用显存的总和。
4、无法释放的显存?
截止上一节,好像一切都朝着预想的角度发展了,如果觉得这样就可以随意清空没用的缓存,那还是高兴的太早了。
假设有这样一种情况:
我的进程占用了很大的显存,即将超出安全值,我希望将已有变量占用的显存彻底清空,那应该怎么做呢?
按照上文的分析和实验,我直观地想到,我把占用显存的变量都删掉,然后再empty_cache不就可以了吗。于是信心满满的写下:
del inputs
del logits
torch.cuda.empty_cache()
执行之后却发现,根本没有效果,显存占用还是维持在原来的数值,压根就没有变化。
经过搜索之后,我看到有的文章中写道,需要多执行几次torch.cuda.empty_cache(),但仍然是没有效果的。
那既然无法通过torch.cuda.empty_cache()将显存释放,那是不是只能通过将进程杀死,才能释放显存了呢?
显然这是不合理的,明明变量都已经清除了,凭什么它还占着显存不放呢?
5、清理“显存钉子户”
好消息是,面对这种困境,我们并非束手无策。
由于torch官方的说明手册对显存管理部分写的过于简略,我只能去代码中寻找一些蛛丝马迹。而torch的python源码是没有将显存释放暴露出来的,所以只好去找C++的源码,最终找到这样一段比较关键的代码,allocator释放显存的方法:
void raw_deallocate(void* ptr) {
auto d = raw_deleter();
AT_ASSERT(d);
d(ptr);
}
通过这个简短的代码逻辑,我们可以看出,显存的释放,是对指针进行操作的。基于这个现象,可以猜想,释放的是某个指针所指向的内存地址所对应的block。
那么再根据这个逻辑,如果我们要释放出一个block,那就应该确保,这个block是没有被tensor占用的。
理想情况下,我们del 了希望释放的变量,其对应的block也应该不再被占用,但现实真的如此吗?不妨再做一个简单的小实验:
a = torch.ones(1)
print(id(a))
# >> 140232734608176
b = a
print(id(b))
# >> 140232734608176
del a
print(id(b))
# >> 140232734608176
可以看到,即便是我们将变量a删除了,变量b指向的地址,仍然是原地址,而在大模型的建模过程中,难免还有其他变量指向原来地址,所以allocator无法将其释放。
如何解决这个问题也很简单,我们只需要做一个很小的哑变量,例如seq_len为2的一个输入变量,然后让模型执行一遍,再去释放它,就可以顺利地释放绝大部分显存了。
real_inputs = inputs['input_ids'][..., : 2, ...].to(model.device)
with torch.no_grad():
logits = model(torch.cat([real_inputs, tail], 1))
del real_inputs
del logits
torch.cuda.empty_cache()
执行完之后,显存成功从14612M下降到3792M
但是在实际使用中,这种方法还是不能够完全清空所有显存,仍然会存在部分泄露的情况,要想弄清楚其中的原理,就需要更底层更深入的研究了。
总结
本文主要介绍了两个话题,一个是对torch显存分析,并探索如何在不关闭进程的情况下释放显存地方法,另一个是通过几种策略来使用Llama-2进行中文对话。
里面的思路都很有参考意义,通过对在生成模型中使用自定义LogitsProcessor中怎样使用logits processor来改变生成过程中的概率,进而改变生成的结果,这其实是受控生成的范畴,在去敏感等方面也能用的到。
总结一下,当我们需要释放掉被数据所占用的显存时,仅仅通过torch.cuda.empty_cache()有时是不够的,一个简单的处理方法是,用一个小的输入,覆盖掉原来的变量,整个模型跑一遍,这样一来所有的中间变量,也就变成与那个小的输入所对应的了。最后再将输入输出都清理掉,就可以顺利地释放显存了。
参考文献
1、https://blog.csdn.net/weixin_44826203/article/details/130401177
2、https://blog.csdn.net/weixin_44826203/article/details/132123946
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢