
📎 直接上手体验:https://scenex.jinaai.cn/
哪些行业可以从 Hearth 算法中受益?
Hearth 算法具有广泛的应用前景,以下几个行业可能尤为受益,下面让我们感受几个实际应用案例:
更多维度的内容创作方式
用一张图生成完整的睡前故事音频
更具代入感的视频内容制作
互动性更强的营销与广告
用一张图为电影院做一个脑洞大开宣传视频
结合听觉视觉的教育讲述
让平面教学插图更加生动
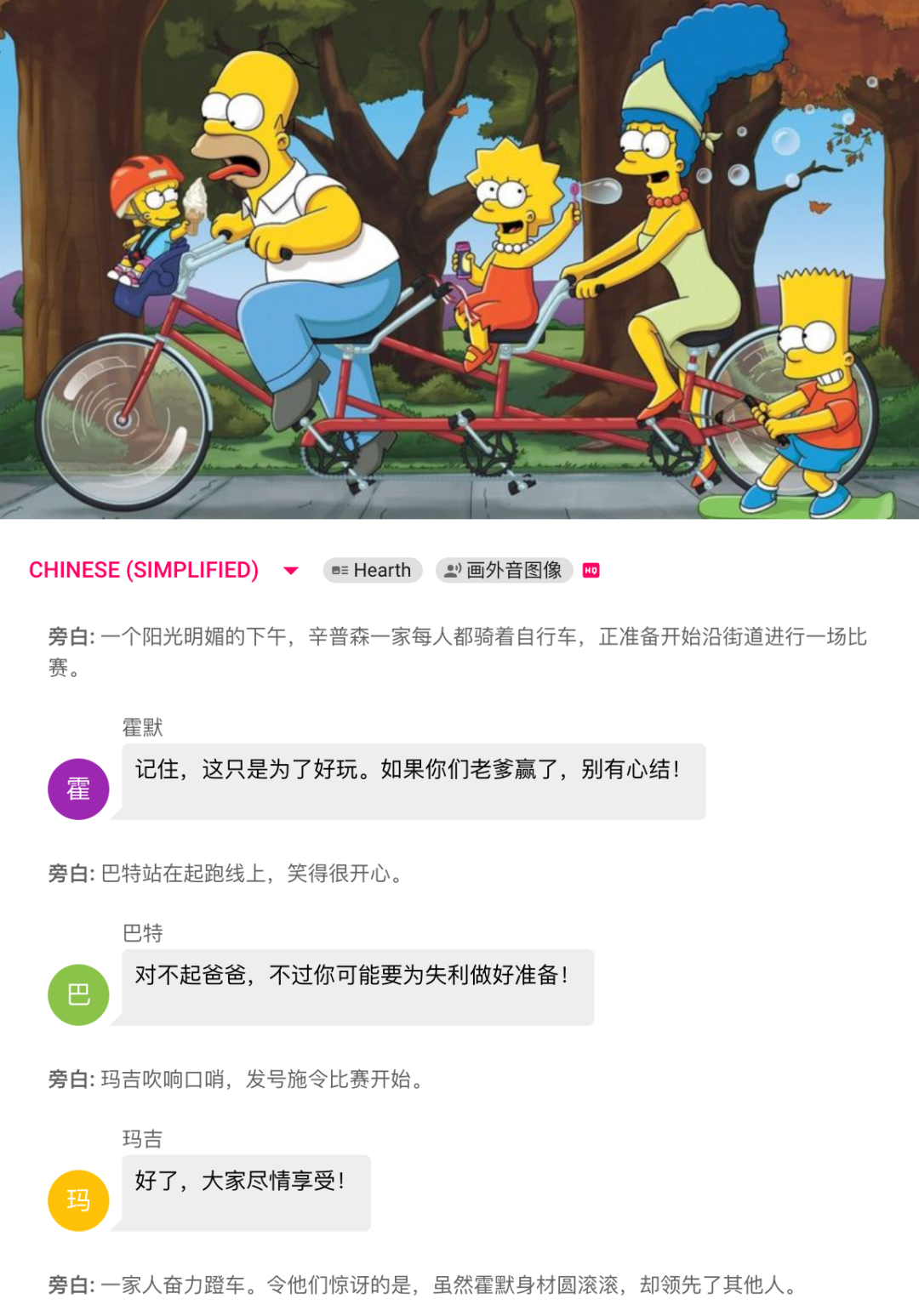
上面的故事不仅编织了一个曲折丰富的故事,还通过生动的人物对话将场景变得栩栩如生。每个人物都被赋予了鲜明的特征和语气,体现了从图像描述中获得的理解深度。
揭秘 Hearth 算法
看到这儿你可能好奇,Hearth 是如何实现这一切的。事实上,我们采用了一种融合 并行与顺序执行策略 的精密架构,以在优化计算性能的同时,生成高度精炼的故事。接下来,让我们将深入探讨该算法的工作机制:
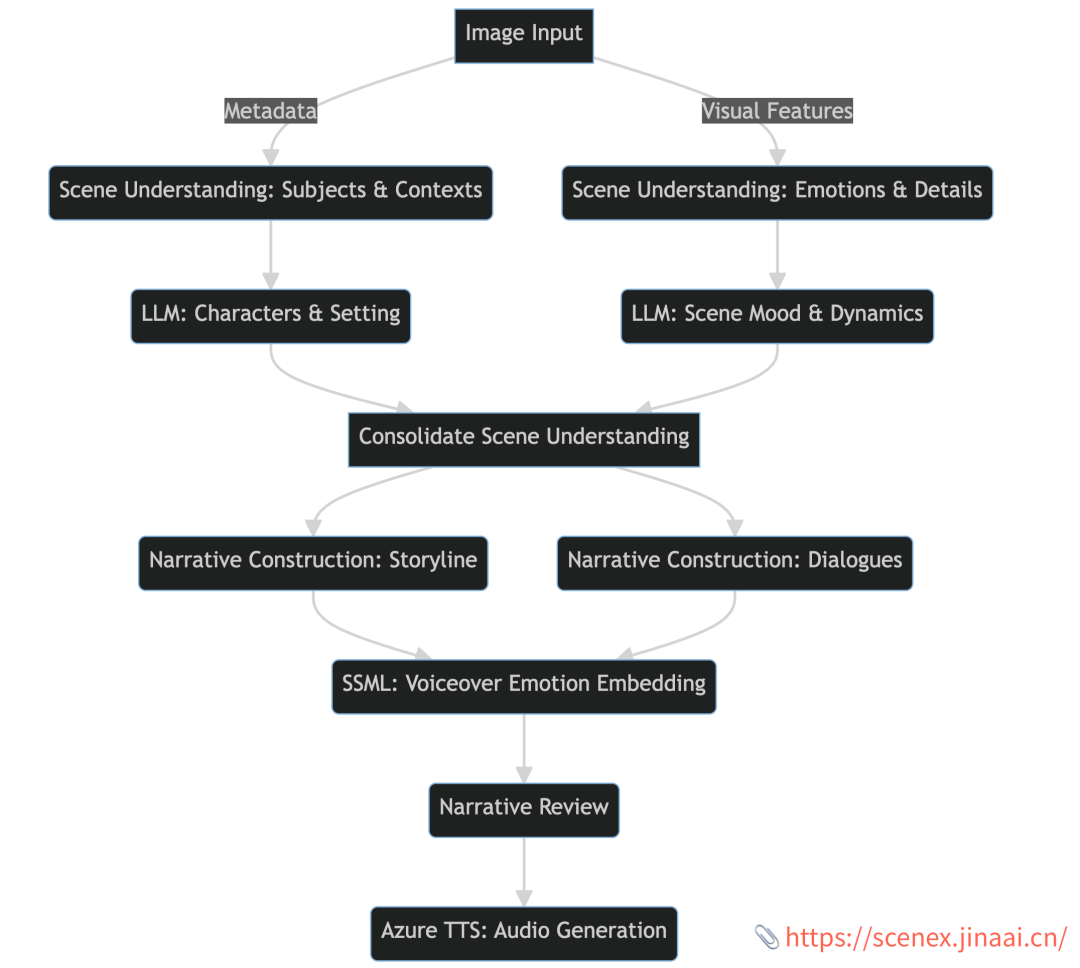
1. 场景理解:不仅看,更要懂
当输入一个图像后,该算法就会同时识别图像的主体和上下文,同时还会从视觉数据中提取潜在的情感和复杂的细节。这些并行的处理流程利用了先进的计算机视觉技术,与我们传统的理解方法相结合,以捕捉图像的本质和微妙之处。
def scene_understanding(image_input):
subjects_and_contexts = get_subject_and_object(image_input)
emotions_and_details = detect_emotions_and_details(image_input)
return subjects_and_contexts, emotions_and_details
2. 大型语言模型(LLM):故事的灵魂
场景理解完后,Hearth 算法会启用大型语言模型(LLM)来构建故事。它会根据从图像中提取的线索,定义故事的角色、环境,以及推导出场景的整体情感和动态。
def llm_processing(subjects_and_contexts, emotions_and_details):
characters_and_setting = derive_characters_and_setting(subjects_and_contexts)
mood_and_dynamics = define_mood_and_dynamics(emotions_and_details)
return characters_and_setting, mood_and_dynamics
3. 叙事构建:不仅要说,更要引人入胜
接着,算法会基于上述信息,编织出吸引人的故事和对话。这里会综合考虑角色、环境和情感,生成与所选故事类型匹配的情节和对话。
def narrative_construction(characters_and_setting, mood_and_dynamics, genre):
storyline = generate_storyline(characters_and_setting, mood_and_dynamics, genre)
dialogues = create_dialogues(characters_and_setting, mood_and_dynamics, genre)
return storyline, dialogues
4. 旁白情感渲染(SSML):听得见的情感
为了让故事更加立体,Hearth 算法会为旁白添加相应的情感色彩。这样,你不仅能“听到”故事,更能“感受”到它。
def ssml_voiceover_embedding(storyline, dialogues):
ssml_output = generate_emotional_ssml(storyline, dialogues)
return ssml_output
5. 故事审查和音频生成:最后的检验
最后,我们对生成的故事进行审查,来确保其逻辑连贯性,并保证和原始场景的相关性。审核通过,文本内容将被发送到 Azure 的文本转语音服务,将文本转换为身临其境的音频体验。
def audio_generation(ssml_output):
reviewed_story = review_narrative(ssml_output)
audio_output = azure_tts(reviewed_story)
return audio_output
通过以上五个步骤,Hearth 算法成功地把一个简单的图像转变为一个充满情感、有声叙述的故事,同时保留了图像本身的信息和情感。
已知限制
和其他前沿技术一样,它也有一些挑战:
幻觉问题:有时,Hearth 算法会为图片创造出一些实际不存在的细节。比如在一幅风景画,算法却在其中添加了一个从未出现过的小人物。这主要是因为算法在学习过程中看过太多的数据,有时会“想象”出一些内容。不过,我们正在努力修正这一点。
速度问题:要达到很高的准确度,算法需要花费更多的时间。但是,为了让算法运行得更快,我们正在研究如何进行优化,这样它在“讲故事”的时候就不会那么慢了。
内容过于政治正确:我们的算法比较倾向于生成符合公众接受度的内容。如果你需要生成一个恐怖故事,那它可能会避免制作过于惊悚的内容。我们正在努力让它可以根据需求生成更多样的内容,采取更平衡的叙事方法。
作为多模态人工智能的领军者,我们的目标是打造功能强大、用户友好的应用。面对上面的挑战,我们有信心在团队和社区的支持下,逐步去解决好。
结论
通过 SceneXplain 的 Hearth 算法,我们不仅可以“看见”图像,还可以“听到”图像背后的故事。
这意味着内容创作者可以从一张图片里找到写故事的灵感,老师可以用图片故事来讲解复杂的课题,公司也可以用它做出引人注目的广告或者产品展示。
所以,别再等了!访问 https://scenex.jinaai.cn,亲自体验从单个图像中挖掘更多的价值和深度。更重要的是,我们真的很希望了解你的反馈,所以立即行动,直接体验到这个技术究竟如何让图片“讲故事”吧!

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢