
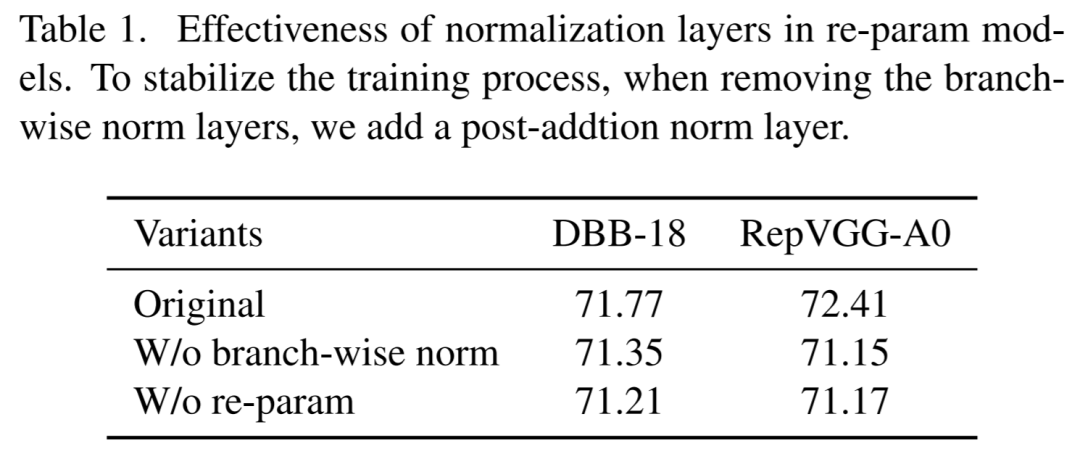
BN层是重参中多层和多分支结构的关键结构,是重参模型性能的基础。如表1所示,以DBB和RepVGG为例,去掉BN层后(改为多分支后统一进行BN操作)性能会有明显的下降。
在推理阶段,重参数结构中的所有中间操作都是线性的,可以进行合并计算。而在训练阶段,由于BN层是非线性的无法进行合并计算。无法合并就会导致中间操作需要单独计算,产生巨大的计算消耗和内存成本。
根据实验和分析,论文发现BN层中的缩放因子能够使不同分支的优化方向多样化。
答:可以,那就是——在线重参数化方法OREPA或者RepOpt,关于RepOpt可以参见前一篇文章重参巅峰 | 你喜欢的RepVGG其实也是有缺陷的,RepOpt才是重参的巅峰。
OREPA减少了由中间层引起的计算和存储开销,能够显著降低训练消耗(65%-75%显存节省、加速1.5-2.3倍)且对性能的影响很小,使得探索更复杂的重参数化结果成为可能。
OREPA的逻辑图如下图所示,主要包含两个步骤:
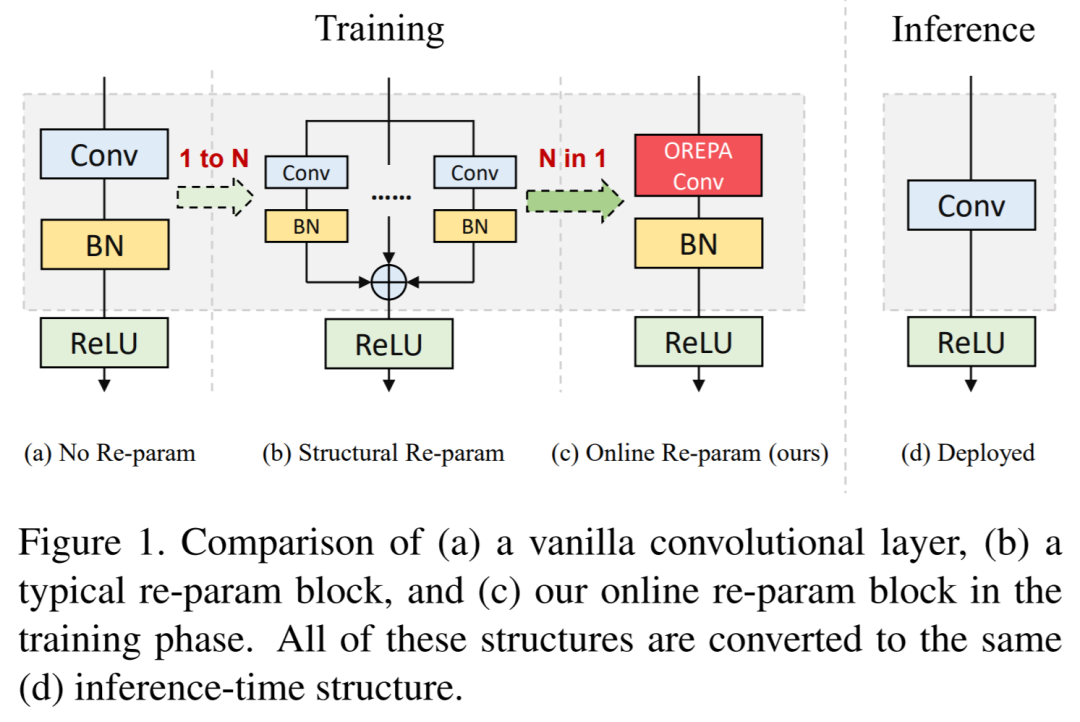
block linearization:去掉所有非线性泛化层,转而引入线性缩放层。线性缩放层不仅能与BN层一样使不同分支的优化方向多样化,还可以在训练时合并计算。block squeezing:将复杂的线性结构简化为单个卷积层。
虽然BN层阻止了训练期间的合并计算,但由于准确率问题,仍然不能直接将其删除。为了解决这个问题,论文引入了channel-wise的线性缩放作为BN层的线性替换,通过可学习的向量进行特征图的缩放。线性缩放层具有BN层的类似效果,引导多分支向不同方向进行优化,这是重参数化性能的核心。
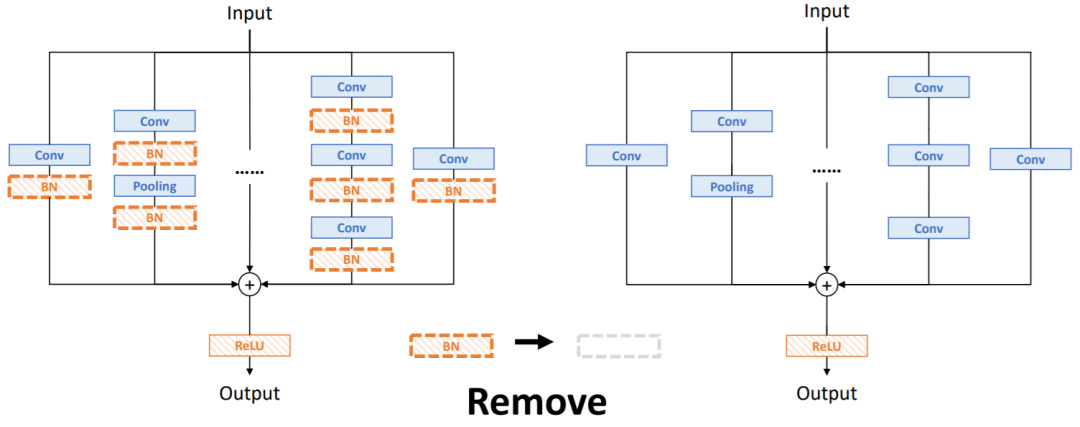
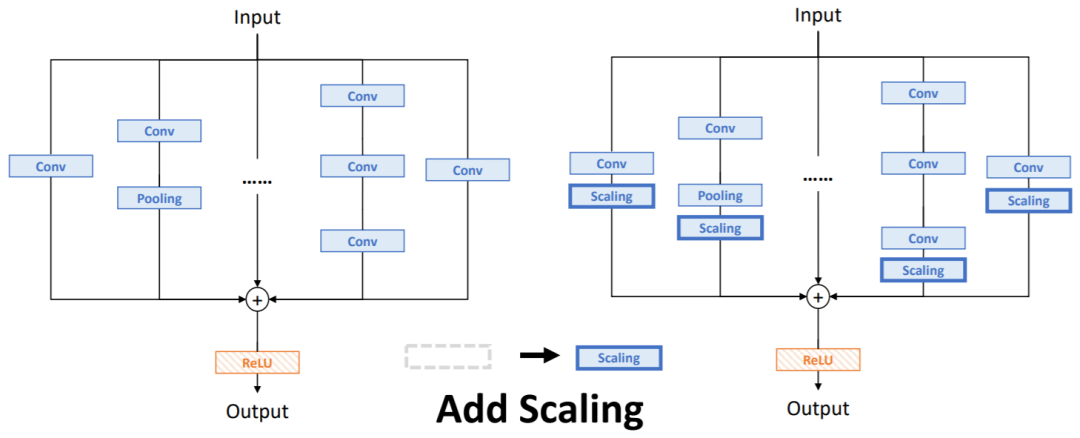
这里由于整个模块是线性的,因此可以在后面添加。
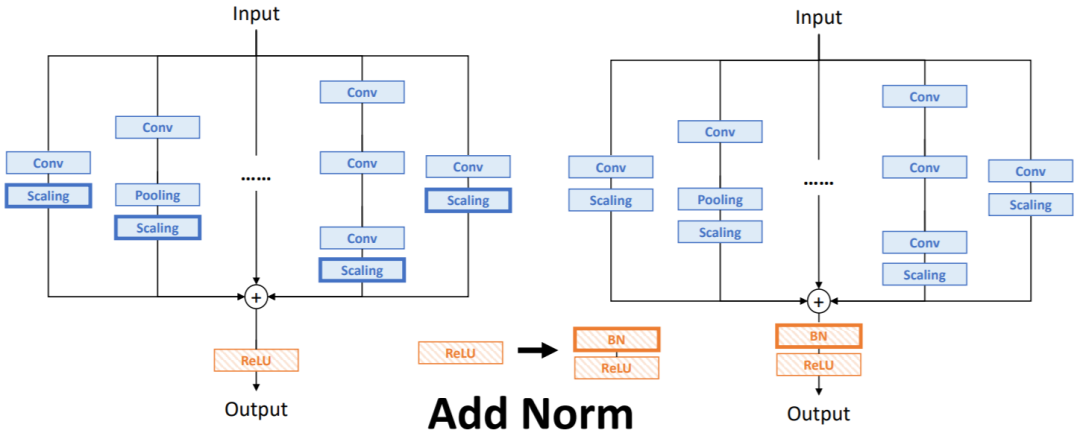
经过block linearization操作后,重参结构中就只存在线性层,这意味着可以在训练阶段便可以合并模块中的所有组件。
Block squeezing将计算和内存过多的中间特征图上的操作转换为单个卷积核核操作,这意味着在计算和内存方面将重参的额外训练成本从减少到,其中是卷积核尺寸。
一般来说,无论线性重参数结构多复杂,以下两个属性都始终成立:

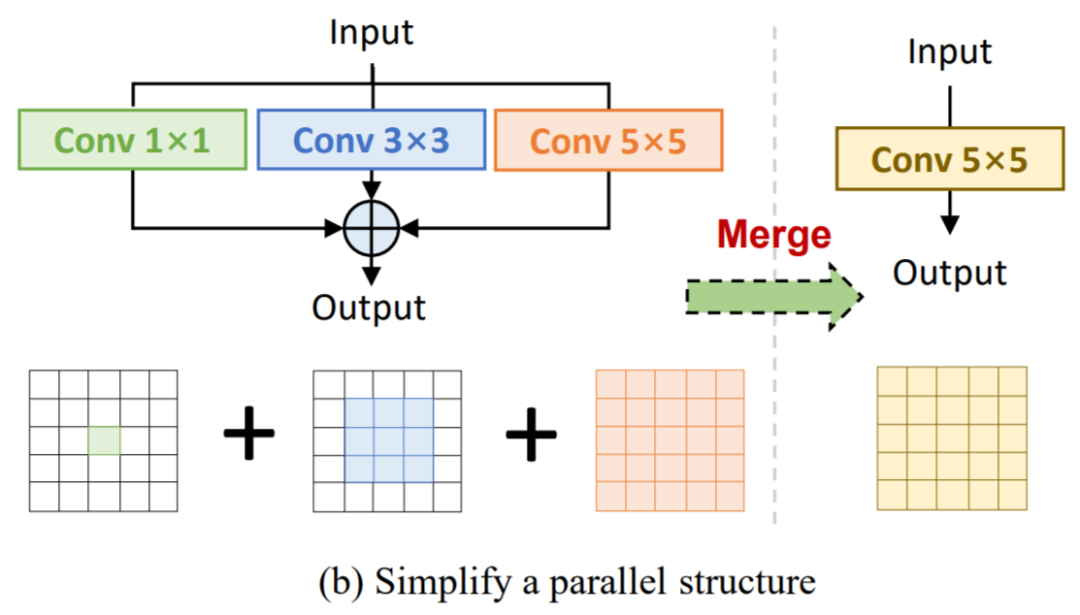
Frequency prior filter:Fcanet指出池化层是频域滤波的一个特例,参考此工作加入1×1卷积+频域滤波分支。

Linear depthwise separable convolution:对深度可分离卷积进行少量修改,去掉中间的非线性激活以便在训练期间合并。

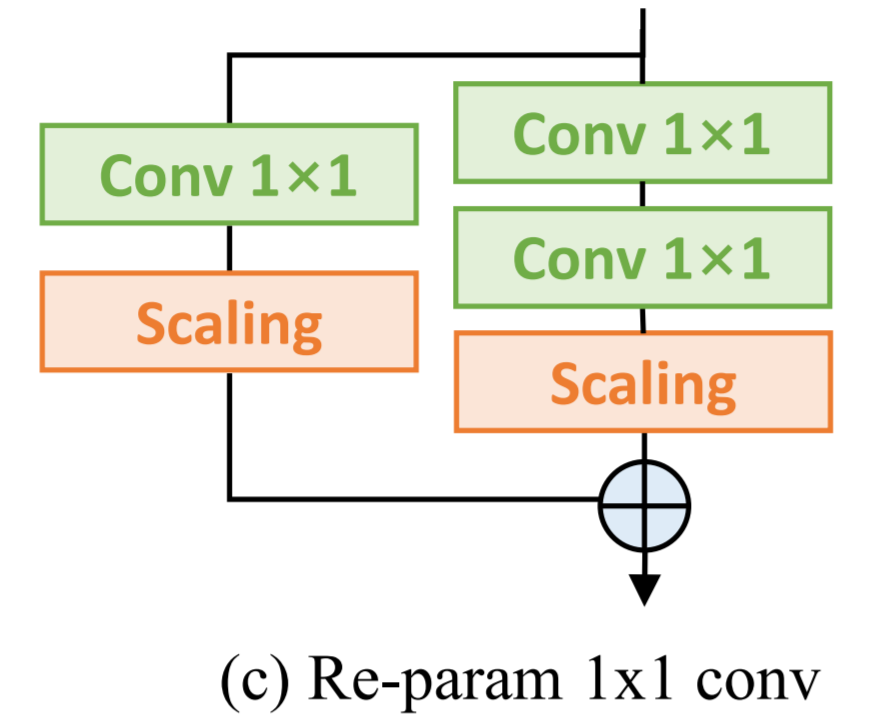
Re-parameterization for 1×1 convolution:之前的研究主要关注3×3卷积层的重参数而忽略了1×1卷积,但1×1卷积在bottleneck结构中十分重要。其次,论文添加了一个额外的1×1卷积+1×1卷积分支,对1×1卷积也进行重参。
Linear deep stem:一般网络采用7×7卷积+3×3卷积作为stem,也有模型选择将其替换为3个连续的3×3卷积,也取得了不错的准确率。但论文认为这样的堆叠设计在开头的高分辨率特征图上的计算消耗非常高,为此将3个3×3卷积与论文提出的线性层一起压缩为单个7×7卷积层,能够大幅降低计算消耗并保存准确率。

OREPA-ResNet中的block设计如下图所示,这应该是一个下采样的block,最终被合并成单个3×3卷积进行训练和推理。

话不多说,直接看上述模块的效果对比吧!
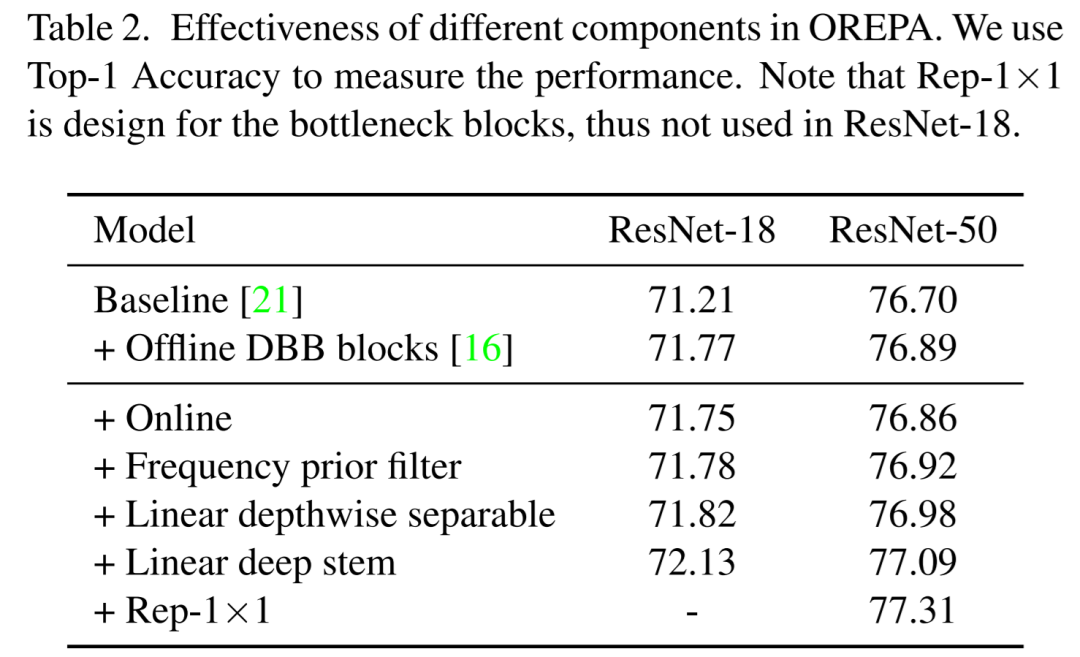
[1].Online Convolutional Re-parameterization.
重参系列 | 以伤换杀,RMNet带你一键将ResNet重参为VGG(附代码及ONNX对比)
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢