

一种从大脑活动中非侵入性地重建语言的方法。
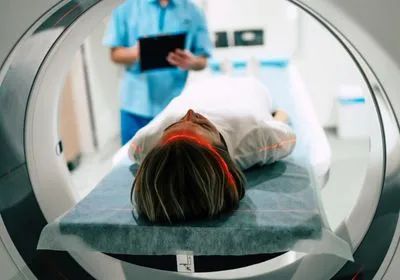
近日,科学家报告说他们设计了一种方法,可以使用功能性磁共振成像大脑记录来重建连续的语言。这些发现是开发更好的脑机接口的基础,这些接口正在被开发为用于提供给不能说话或打字的人的辅助技术。
在 9 月 29 日发布在bioRxiv上的预印本中,德克萨斯大学奥斯汀分校的一个团队详细介绍了一种“解码器”算法,它可以“读取”一个人在功能性磁共振成像 (fMRI) 期间听到或思考的单词脑部扫描。虽然其他团队之前曾报告说在基于大脑植入物的信号重建语言或图像方面取得了一些成功,但该解码器是第一个使用非侵入性方法来实现这一目标的解码器。
“如果你在 20 年前问世界上任何一位认知神经科学家这是否可行,他们会一笑置之。”德克萨斯大学奥斯汀分校的神经科学家、该研究的合著者Alexander Huth说。
没有参与这项研究的京都大学计算神经科学家Yukiyasu Kamitani在给The Scientist的电子邮件中写道,看到非侵入式解码器能生成可理解的语言序列是“令人兴奋的”。“这项研究为 BCI 应用程序奠定了坚实的基础。”他说。
使用 fMRI 数据进行此类研究很困难,因为与人类思维的速度相比,数据得出结果相当缓慢。MRI机器不是检测毫秒级的神经元放电,而是测量大脑内血流的变化,作为大脑活动的表征;这样的改变需要几秒钟。Huth 说,这项研究的设置之所以有效,是因为该系统不是逐字解码语言,而是试图辨别句子或思想等更高层次的含义。
Huth 和他的同事们用 fMRI 大脑记录训练他们的算法:三个研究对象——一个女人和两个男人,都在 20 多岁或 30 多岁——听了 16 小时的播客和广播故事:The Moth Radio Hour、TED 演讲和 John Green's Anthropocene Reviewed是使用的媒体之三。Huth 说,为了构建一个准确且广泛适用的解码器,研究对象聆听广泛的媒体非常重要。他指出,收集的 fMRI 数据量与大多数使用 fMRI 记录的其他研究相匹配,尽管他的研究对象还比较少。
基于对个人大脑 16 小时 fMRI 记录的训练,解码器对 fMRI 读数的结果进行了一系列预测。Huth 表示,使用这些“预言”训练是确保解码器能够翻译与训练中使用的已知录音无关的其它想法的关键。根据实时 fMRI 记录检查这些“猜测”,最接近真实读数的预言决定了解码器最终生成的单词。
为了确定解码器的成功率成功程度,研究人员对解码器的生成与呈现结果进行了评分。他们还对同一解码器生成的语言进行了评分,这些语言尚未与 fMRI 记录进行匹配。然后他们比较了这些分数并测试了两者之间差异的统计显着性。
结果表明,该算法的猜测和检查程序最终会从 fMRI 录音中生成一个完整的“故事”,Huth 说,这与录音中讲述的实际故事“非常吻合”。但是,它确实有一些缺点;例如,它不太擅长保留代词,并且经常混淆第一人称和第三人称。Huth 说,解码器“非常准确地知道发生了什么,但不知道是谁在做这些事情。”
普林斯顿神经科学研究所的研究员兼讲师Sam Nastase没有参与这项研究,他说使用 fMRI 记录进行这种类型的大脑解码是“令人震惊的”,因为这些数据通常非常缓慢和嘈杂。“他们在这篇论文中展示的是,如果你有一个足够聪明的建模框架,就可以从 fMRI 记录中提取出惊人数量的信息。”他说。
该系统不是逐字解码语言,而是辨别句子或思想的更高层次的含义。
由于解码器使用非侵入性 fMRI 大脑记录,Huth 说它比侵入性方法具有更高的实际应用潜力,尽管使用 fMRI 机器的费用和不便也是一个明显的挑战。此外,脑磁图是另一种非侵入性但更便携的脑成像技术,在时间上比 fMRI 更精确,它可能与类似的计算解码器一起使用,为非语言的人提供一种交流方法。
Huth 说,解码器技术成功的最令人兴奋的作用是是它体现了一种对大脑是如何工作的洞察力。例如,他指出,研究结果揭示了大脑的哪些部分负责创造“意义”。通过在前额叶皮层或顶叶颞叶皮层等特定区域的记录上使用解码器,研究小组可以确定哪个部分代表什么语义信息。他们的发现之一是,大脑的这两个部分会向解码器表示相同的信息,并且解码器在使用来自两者中任一大脑区域的记录时工作得同样好。
Huth 补充说,最令人惊讶的是,解码器能够重建未使用语义语言的刺激,比如它可以针对听口语的受试者进行训练。例如,经过训练,该算法成功地重建了观看无声电影主题的“意义”,以及参与者想象的讲述故事的体验。“这些东西在大脑中如此重叠的事实是我们刚刚开始发现的现象。”他说。
对于 Kamitani 和 Nastase,Huth 实验室的结果(尚未经过同行评审)提出了关于解码器如何处理潜在含义与文本或语音语言的问题。Nastase 说,由于新的解码器检测的是意义或语义,而不是单个单词,因此它的成功可能难以衡量,因为许多单词组合都可以算作“好的”输出。“这是他们提出的一个有趣的问题。”他说。
Huth 承认,对某些人来说,能够有效“读心”的技术可能有点“令人毛骨悚然”。他的团队对这项研究的影响进行了深入思考,并且出于对心理隐私的关注,研究了解码器在没有参与者自愿合作的情况下是否可以工作。在一些试验中,当播放音频时,研究人员要求受试者通过执行其他心理任务来分散自己的注意力,比如数数、命名和想象动物,以及想象讲述一个不同的故事。他们发现,命名和想象动物在使解码不准确方面最有效。
Huth 说,从隐私的角度来看,同样值得注意的是,在一个人的大脑扫描上训练的解码器无法重建另一个人的语言,在研究中返回了“基本上没有可用的信息”。因此,参与者需要参加广泛的培训课程,才能准确解码他们的想法。
对 Nastase 来说,研究人员努力寻找精神隐私保护证据的事实令人欣慰。“如果没有任何这些隐私相关的实验,你可以很容易地在六个月前发表这篇论文。”他说。然而,他不相信隐私一定会成为一个问题,因为未来的研究可能会找到绕过研究人员详述的心理隐私问题的方法。“这是一个问题,技术的好处是否超过了可能的危害?”Nastase 说。
本篇文章来源:
https://www.the-scientist.com/news-opinion/researchers-report-decoding-thoughts-from-fmri-data-70661
来源:中国信通院知产与创新中心
仅用于学术交流,若有侵权,请后台留言,即时删侵!
更多阅读

加入社群
欢迎加入脑机接口社区交流群,
探讨脑机接口领域话题,实时跟踪脑机接口前沿。
加微信群:
添加微信:RoseBCI【备注:姓名+行业/专业】。
加QQ群:104048131
欢迎来稿
1.欢迎来稿。投稿咨询,请联系微信:RoseBCI
2.加入社区成为兼职创作者,请联系微信:RoseBCI


点个在看祝你开心一整天!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢