
点击下方卡片,关注“人工智能AI算法工程师”公众号
今天自动驾驶之心很荣幸邀请到李弘洋来分享全新的将2D特征拉升到3D空间的基础算子—DFA3D,如果您有相关工作需要分享,请在文末联系我们!
论文作者 | 李弘洋
编辑 | 自动驾驶之心

开源地址:https://github.com/IDEA-Research/3D-deformable-attention.git
大家好,很开心能够受邀来自动驾驶之心分享我们最近为3D计算机视觉社区所贡献的一个新的将2D特征拉升到3D空间的基础算子--3D DeFormable Attention (DFA3D)。这篇工作是华南理工大学、IDEA等几家单位联合出品,下面将会给大家详细介绍DFA3D的设计思路以及我们在3D目标检测任务上所做的验证实验。
本文提出了一种新的操作符,称为三维可变注意力(3D DeFormable Attention,简称DFA3D),用于二维到三维特征拉升,将多视角二维图像特征转换到统一的三维空间,用于三维物体检测。现有的特征拉升方法,如基于 Lift-Splat 和基于二维注意力的方法,要么利用估计的深度获取伪 LiDAR 特征,然后将它们投射到三维空间,受限于单次操作(one-pass)而没有特征优化;要么忽略深度,通过二维注意力机制拉升特征,虽然可以实现更精细的语义,但会遇到深度不确定性问题。相比之下,我们基于DFA3D的方法首先利用估计的深度将每个视角的二维特征图扩展到三维,而后再利用DFA3D从扩展的三维特征图中聚合特征。借助DFA3D,可以从根本上有效地减轻深度不确定性问题,并且由于类Transformer架构的存在,DFA3D可以逐层逐层地逐渐优化拉升的特征。此外,我们提出了DFA3D的数学等效实现,可以显著提高其内存效率和计算速度。仅仅使用少量的代码修改,我们便实现将DFA3D集成到多种使用二维注意力的特征拉升方法中,并在 nuScenes 数据集上进行了评估。实验结果显示mAP平均提升了+1.41%,并且在高质量深度信息可用时,mAP 提升高达 +15.1%,展示了DFA3D的优越性、适用性和巨大潜力。代码链接:https://github.com/IDEA-Research/3D-deformable-attention.git。
总的来说,我们的主要贡献如下:
我们提出了一种新的基本操作符,称为三维可变注意力(3D deformable attention,简称DFA3D),用于特征拉升。通过利用二维特征与其估计深度之间的外积性质,我们开发了一种高效且快速的实现方法。 基于DFA3D,我们开发了一种新颖的特征拉升方法,不仅从根本上减轻了深度不确定性问题,还可以受益于类Transformer架构的多层特征优化。由于DFA3D具有简单的接口,只需对代码进行少量的修改我们就可以将基于DFA3D的特征拉升方法实现在任何使用基于二维可变注意力(包括其退化形式)的特征拉升方法的方法中。 在nuScenes数据集进行对比实验时,我们的方法表现出了稳定的提升(平均提升+1.41 mAP),证明了基于DFA3D的特征拉升方法的优越性和泛化能力。
基于DFA3D的多视角端到端三维检测方法的总揽如图所示(见图2)。在本节中,我们介绍了如何构建用于DFA3D的扩展三维特征图(3.1节),并介绍了DFA3D如何实现特征拉升(3.2节)。此外,我们解释了我们高效的DFA3D实现方法(3.3节)。最后,我们对基于DFA3D的特征拉升方法与当前主流特征拉升方法进行了详细的分析和比较(3.4节)。
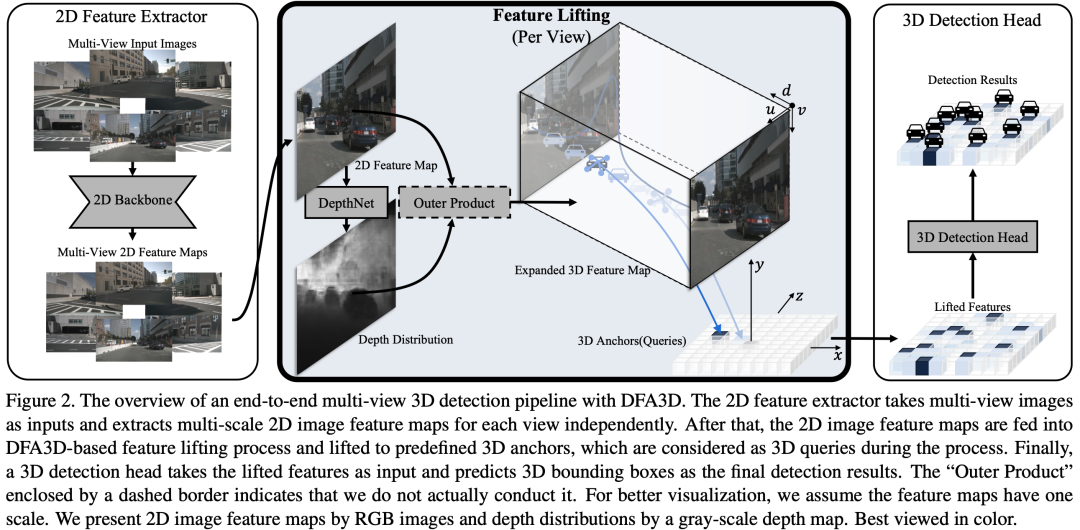
在多视角三维检测的背景下,输入图像的深度信息不可用。我们仿照BEVDepth,引入单目深度估计来为二维图像特征补充深度信息。具体而言,我们使用了一个DepthNet模块,以2D主干网络所输出的二维图像特征图作为输入,为每个二维图像特征生成离散的深度分布,以补充深度信息。DepthNet模块可以通过使用由LiDAR信息或ground truth 3D边界框信息所生成的深度信息来进行监督训练。
我们将多视角的二维图像特征图表示为 ,其中 、、 和 分别表示视角数、特征图的高度、特征图的宽度和特征图的通道数。我们将多视角的二维图像特征图输入DepthNet,以获取离散的深度分布。这些分布具有与 相同的空间形状,可以表示为 ,其中 表示预定义的离散的深度类别数。在这里,为了简化起见,我们假设 只有一个特征尺度。在多尺度的情况下,为了保持多个尺度之间的深度一致性,我们选择一个尺度的特征图参与深度分布的生成。然后,通过对生成的深度分布进行插值,以获取多尺度特征图的深度分布。
在获取离散深度分布 后,我们通过在 和 之间进行外积,将 的维度扩展到三维。具体公式为 , 其中 表示在最后一个维度进行外积, 表示多视角扩展的三维特征图。有关扩展的三维特征图的更多细节,可以参考我们文章的附录部分,我们提供了清晰的可视化。
直接通过外积扩展二维图像特征图会导致高内存消耗,特别是在考虑多尺度时。我们将在3.3节解释如何解决这个问题。
在获取了多视角扩展的三维特征图后,我们将DFA3D作为后端,将其转换为统一的三维空间,以获得拉升后的特征。具体而言,在特征拉升的背景下,DFA3D将预定义的三维锚点视为三维查询,将扩展的三维特征图视为三维键和值,并在三维像素坐标系(比常规的图像坐标系多了深度维度)中执行可变注意力。
更具体地说,对于在自车坐标系中位于 处的三维查询,其在第 个视角的三维像素坐标系中的视图参考点可以通过小孔相机模型来得到,我们将该参考点记作 。
我们将三维查询的内容(content)特征表示为 ,其中 表示 的维度。第 个视角中的DFA3D过程可以表示为(这里我们将注意力头数设置为1,特征尺度数设置为1,并且为了简化记法,我们省略了它们的索引符号。):
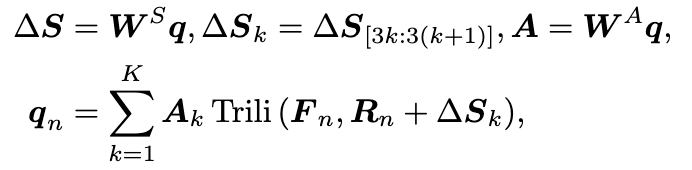
其中 是第 个视角中的查询结果, 表示采样点数, 和 是可学习的参数, 和 分别表示三维像素坐标系中的视图采样位置偏移量和相应的注意力权重。 表示用于在扩展的三维特征图中采样特征的三线性插值。关于 的详细实现和我们的简化将在第3.3节中解释。
在多视角中通过DFA3D获取查询结果后,三维查询的最终拉升特征 通过对查询结果进行聚合来获得,即
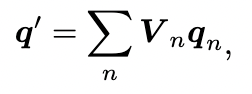
其中 表示在第 个视角中的三维查询的可见性。得到的拉升后的特征用于更新三维查询的内容特征,以实现特征的优化。
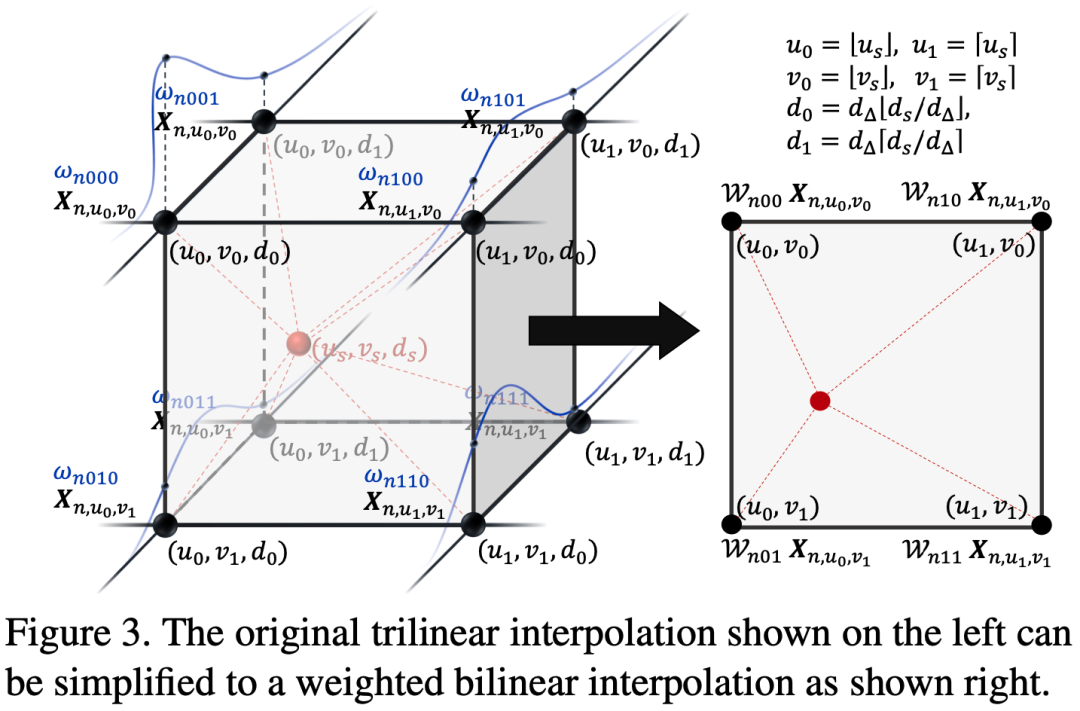
虽然三维可变注意力已在上一节中进行了公式化,但是在内存中维持多视角扩展的三维特征图 将导致巨大的内存消耗,尤其在考虑多尺度特征时。我们证明,在通过二维图像特征图与其离散深度分布之间的外积进行特征扩展的背景下,三线性插值可以转化为深度加权的双线性插值。因此,三维可变注意力也可以相应地转化为深度加权的二维可变注意力。如上图所示,在不失一般性的情况下,对于一个特定视角(例如第 个视角),其扩展的三维图像特征图 ,,假设在三维像素坐标系中,采样点 落在一个由八个点组成的立方体中:,其中 ,这些点是采样点在 中的八个最近点。采样点对这八个点的特征执行三线性插值以获取采样结果。由于具有相同 坐标的点会共享相同的二维图像特征,它们在插值过程中的贡献可以表示为 ,其中 用于简化记法,表示 。 表示从离散深度分布 中根据其深度值采样到的点 的深度置信度。因此,三线性插值可以表示为:

其中 表示两个相邻深度分档之间的深度间隔。该公式可以进一步公式化为
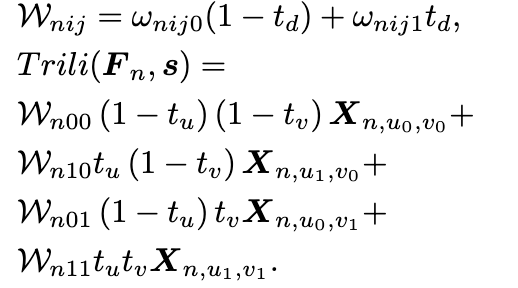
通过比较上面的两个公式,我们可以发现,这里的三线性插值实际上可以分为两部分:1)沿深度轴对估计的离散深度分布进行简单的单线性插值,以获取深度置信度得分 ,2)在二维图像特征图中进行被深度置信度得分加权了的双线性插值。与双线性插值相比,我们唯一需要额外计算的是通过单线性插值来采样深度置信度得分 。通过这样的优化,我们可以地实时计算三维可变注意力,而无需维持所有庞大的扩展的特征在内存中。因此,整个注意力机制可以更高效地实现。此外,这种优化可以减少一半的乘法操作,从而加速整体计算。
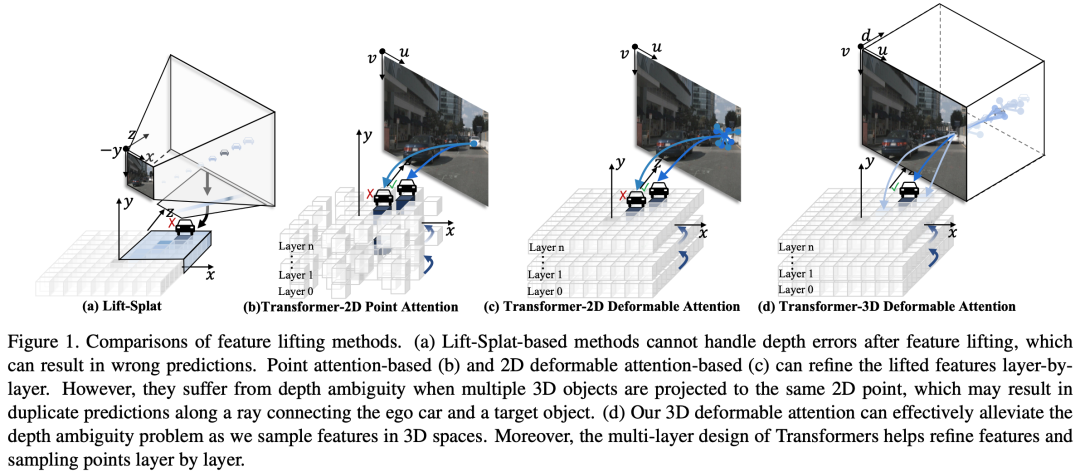
与基于Lift-Splat的特征拉升方法的比较。 基于Lift-Splat的特征拉升方法遵循基于LiDAR的方法的流程。为了构建就像是从LiDAR数据中获取的伪LiDAR特征,它也利用深度估计来补充深度信息。它构建单尺度的三维扩展特征图,并通过以相机参数显式地将它们从三维像素坐标系转换到自车坐标系。伪LiDAR特征进一步被分配给最近临的三维锚点,以生成下游任务所需的拉升后的特征。由于三维锚点和伪LiDAR特征的位置是是基于它们的几何关系所确定的,是恒定的,因此它们之间的分配规则是固定的,无法通过学习的方式以及多层优化的方式进行改进。
在DFA3D中,基于估计的采样位置计算的3D查询与扩展的三维特征之间的关系也可以被视为一种分配规则。与固定的规则不同,DFA3D可以通过在类Transformer架构中逐层更新采样位置来逐步改进分配规则。此外,DFA3D的高效实现使得能够利用多尺度的三维扩展特征,这对于检测小型(远处)物体更为关键。
与基于2D注意力的特征拉升方法的比较。 与DFA3D类似,基于2D注意力的特征拉升也将每个3D查询转换为像素坐标系。然而,为了满足现有的2D注意力操作的输入,3D查询需要投影成2D查询,其深度信息被丢弃。这是一种在实现中的妥协,但这可能会导致多个3D查询塌缩为一个2D查询。因此,多个3D查询可能会极大地纠缠在一起。根据针孔相机模型,我们可以简单地证明出来,只要3D查询在自车坐标系中的坐标 满足
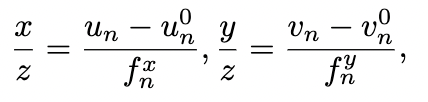
它在目标2D像素坐标系中的参考点就将被投影到共享的 坐标,导致将要被用于更新3D查询的内容以及下游任务的拉升后的特征难以被区分开。(为第n个view的相机内参。)
为了公平地比较不同的特征拉升方法,我们将特征拉升设置为唯一的变量,并保持其他条件相同。具体而言,我们block住了时间信息,使用相同的2D主干网络和3D检测头。结果如下表所示
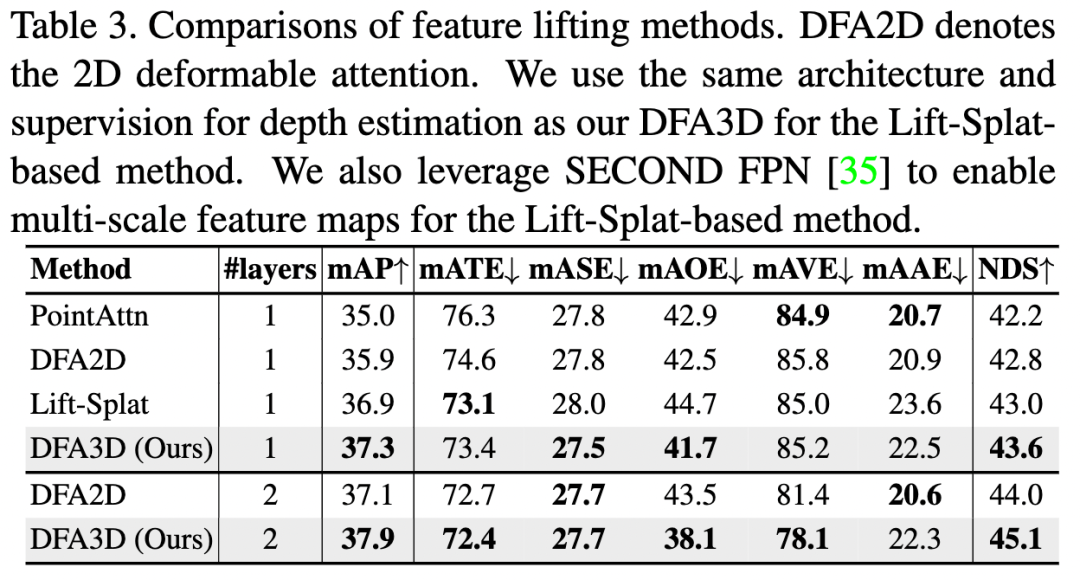
我们首先比较了上表中的前四行中四种不同的特征拉升方法。所有模型都只使用了一层从而进行公平比较。结果显示,DFA3D胜过了所有以前的方法,证明了其有效性。尽管较大的感受野使得基于2D可变注意力(DFA2D)的方法比基于点注意力的方法取得了更好的结果,但与基于Lift-Splat的方法相比,其性能还不够令人满意。DFA2D 和 Lift-Splat 之间的一个关键区别在于它们对深度的感知。额外的深度信息使得基于Lift-Splat的方法可以取得更好的性能,尽管深度信息是预测的且不够准确。不同于基于DFA2D的特征拉升,DFA3D 可以在可变注意力机制中利用深度信息,有助于我们的基于DFA3D的特征拉升取得最佳性能。
如在第3.4节中讨论的那样,可调整的分配规则使得基于注意力的方法能够进行多层次的优化。通过再多一层的优化,基于DFA2D的特征拉升超过了基于Lift-Splat的方法。然而,受益于更好的对深度信息的利用,我们基于DFA3D的特征拉升仍然保持着优越性。
为了验证基于DFA3D的特征拉升的方法的泛化性和可移植性,我们在依赖于2D可变注意力或点注意力的特征拉升方法的各种开源方法上进行了评估。
我们在下表中将baseline方法与集成了DFA3D特征拉升的方法进行了比较。结果显示,在不同的方法中,DFA3D 都带来了稳定的提升,表明它在不同模型上具有泛化能力。此外,DFA3D 在 BEVFormer-t、BEVFormer-s 和 BEVFormer-b 上分别带来了 、 和 mAP 的显著提升,显示出 DFA3D 在不同模型尺寸上的有效性。
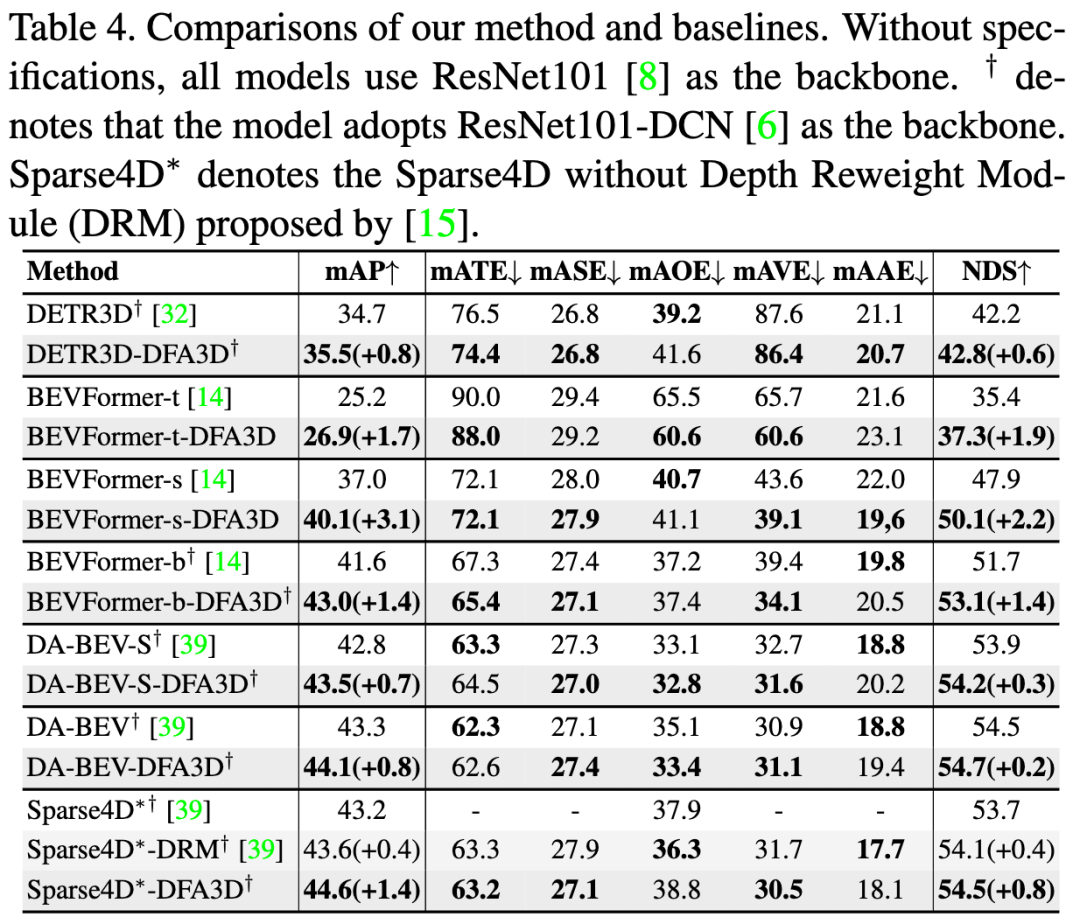
为了更全面地比较,我们还在 DA-BEV 和 Sparse4D 这两个同期工作上进行了实验,它们通过隐式或后续优化来解决深度歧义问题。与之不同的是,我们从特征拉升过程中的根本问题开始着手解决这个问题,这是一种更合理的解决方案。结果显示,尽管他们已经对对深度模糊进行了缓解,但DFA3D 在 DA-BEV-S、DA-BEV 和 Sparse4D 上分别获得了 、 和 mAP 的改进,验证了我们新的特征拉升方法的必要性。
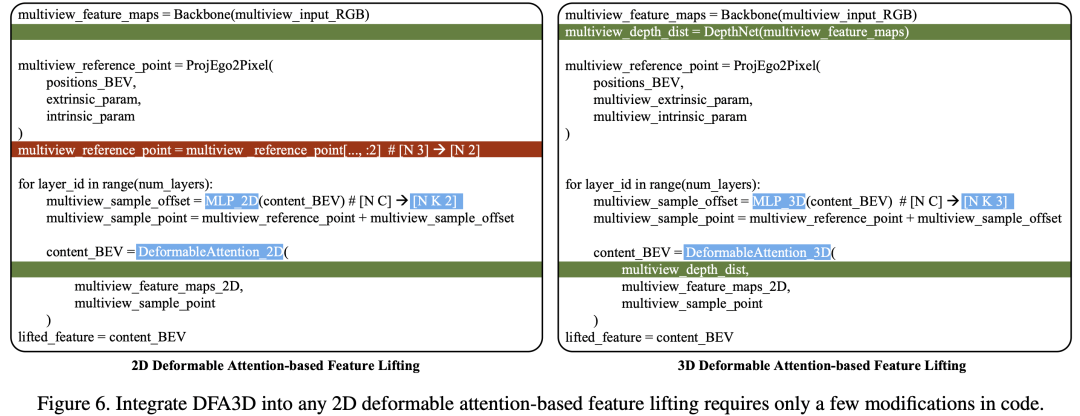
值得注意的是,由于我们在DFA3D上所作的数学上的优化,我们的基于DFA3D的特征拉升可以通过仅对代码进行少量修改就轻松集成到基于2D注意力机制来做特征拉升的方法中,如下图所示。
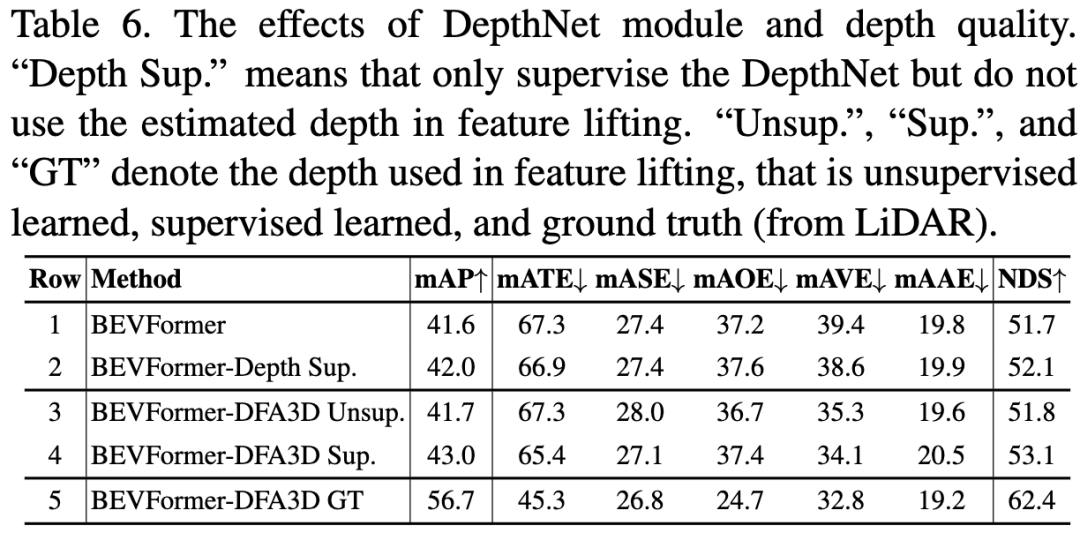
如下表所示,我们首先展示了 DepthNet 模块本身做带来的影响。与 DFA3D 带来的 1.4% mAP 增益(第4行对比第1行)相比,仅仅给 BEVFormer 配备 DepthNet 并监督它只能带来 0.4% mAP 的增益(第2行对比第1行),相对较小。这种比较表明,主要的改进不是来自于 DepthNet 的额外参数和监督,而是来自于更好的特征拉升。
然后,我们评估了深度质量对性能的影响。我们实验了三种不同质量的深度:1)通过无监督学习获得的深度,2)通过有监督学习获得的深度,以及 3)通过 LiDAR 生成的ground truth的深度。这些不同质量的深度对应结果在下表的第3、4和5行中。结果显示,随着深度质量的提高,性能也会随着提升。值得注意的是,具有ground truth深度的模型达到了 56.7% 的 mAP,比baseline提高了 15.1% 的 mAP。这表明存在很大的改进空间,值得进一步深入研究如何获得更好的深度估计。
限于篇幅,请大家参考我们的原文来获得更多对比实验以及消融实验的信息。
在本论文中,我们提出了一个称为 3D 可变形注意力(DFA3D)的基本运算符,并在此基础上开发了一种新颖的特征拉升方法。这种方法不仅考虑了深度信息以解决深度歧义问题,还从多层优化机制中受益。我们通过数学方法简化了 DFA3D 并开发了一种内存高效的实现。简化后的 DFA3D 使得通过可变形注意力在 3D 空间中查询特征成为可能且高效。实验结果表明,该方法能够带来稳定的提升,展示了 DFA3D 特征拉升方法的优越性和泛化能力。
局限性和未来工作展望: 在本文中,我们仅仅使用单目深度估计来为 DFA3D 提供深度信息,这种估计不够准确和稳定。最近提出的方法已经证明,长时序信息可以为网络提供更好的深度感知能力。如何充分利用优越的深度感知能力来显式地生成高质量的深度图,并利用它们来改善基于 DFA3D 的特征拉升方法的性能,仍然是一个需要进一步研究的问题,我们将其留作未来的工作。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢