

Prefix-tuning和P-tuning通过引导模型生成过程,使模型能够更准确地满足任务需求。
Adapter技术通过添加轻量级的适配器层,实现了快速的任务适应和灵活性。
Low-Rank Adaptation(LoRA)通过低秩近似减少模型参数量,提高模型的效率和部署可行性。
REcurrent ADaption(READ)在保持较高质量模型微调效果的同时,可以节省56%的训练显存消耗和84%的GPU使用量。
免费领99个微调数据/模型/工具
▪️58个开源的微调数据
▪️18个开源垂直微调模型
▪️23个开源的指令微调与强化工具

(文末有福利)

大模型微调给学术界和工业级提供很有价值的研究内容,有很多idea都可以被激发出来,有很多地方都可以赶紧占坑。
我们邀请了清华大学博士,AI顶会审稿人青山老师为大家带来——惊艳的大模型高效参数微调法!来和大家聊一聊有关大模型微调的方法、未来趋势及创新点!
扫描参与课程
免费领99个大模型微调模型/数据/工具
(文末有福利)

讲师介绍—青山老师
▪️研究领域:工业故障诊断、医学图像分割、医学多模态问答、不平衡学习、小样本学习、开集学习和可解释性深度学习等。
▪️共发表20余篇SCI国际期刊和EI会议论文,包括一区期刊IEEE Transactions on Industrial Informatics (影响因子11.648),Applied Soft Computing (影响因子8.263),Neurocomputing (影响因子5.779), ISA Transactions (影响因子5.911),Journal of Intelligent Manufacturing (影响因子7.136) 等。论文引用200+。
▪️长期担任人工智能顶级会议AAAI等审稿人, Neurocomputing,Expert Systems with Applications等国际顶级期刊审稿人。
免费领99个大模型微调模型/数据/工具

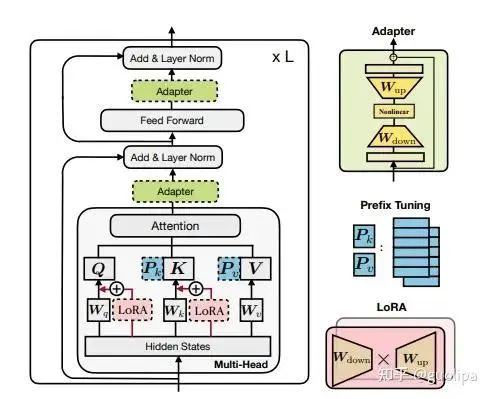
PEFT 方法可以分为三类,不同的方法对 PLM 的不同部分进行下游任务的适配:
Prefix/Prompt-Tuning :在模型的输入或隐层添加 k 个额外可训练的前缀 tokens(这些前缀是连续的伪 tokens,不对应真实的 tokens),只训练这些前缀参数; Adapter-Tuning :将较小的神经网络层或模块插入预训练模型的每一层,这些新插入的神经模块称为 adapter(适配器),下游任务微调时也只训练这些适配器参数; LoRA :通过学习小参数的低秩矩阵来近似模型权重矩阵 W 的参数更新,训练时只优化低秩矩阵参数。
作为一个科研小白,怎么发表一篇大模型微调相关的优质论文?
为了论文,大家都在努力地设计新网络、新策略、新training算法,只要能够在某一问题上做到一个很好的performance,论文就水到渠成。而想要快速达到,来自前辈的指点不可或缺。
一个好的指导老师的作用是,没有课题,能够结合所在课题组具体情况,结合最近热门研究方向,帮你规划课题,如果有了课题而缺少创新方向,老师能够快速帮你找到几种切入点,几种框架,甚至连需要读哪些文献都帮你想好了......
扫描二维码
获取学术大咖科研指导
(文末有福利)
同时向大家推荐一个1v6科研小班,由哈工大计算机博士,多个顶会审稿人Kimi老师授课——基于大模型的自然语言处理。
LLMs(Large Language Models)是一种利用深度学习技术构建的人工智能模型,能够理解和生成自然语言文本。通过在大量文本数据上进行训练,LLMs可以执行各种语言任务,如问答、文本生成、翻译等。OpenAI的GPT系列模型就是大语言模型的典型代表,它们在许多自然语言处理任务中表现出色,能够与人类进行流畅的文字交流。
近一年,各类中文LLMs层出不穷。ChatGLM-6B 是由智谱AI(清华) 开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。MOSS 是由复旦大学发布的一个支持中英双语和多种插件的开源对话语言模型。大数据国家实验室发布的Linly包含 Linly-Chinese-LLaMA , Linly-ChatFlow , Linly-ChatFlow-int4 四个版本。此外,基于医学知识的LLaMA微调模型HuaTuo,在医疗问答领域有着不俗的表现。甚至还有蛋白质预训练大模型ProtTrans。可以说,自然语言处理俨然已经来到了大模型的时代。
正处在时代风口的我们何不来一场大模型的论文狂欢?无论你是想二次预训练or微调LLM使其更专精于某个特定的应用场景;还是想将特定领域的知识与大模型强大的推理能力相结合,以从大模型那里得到更准确的答案;还是将大模型作为一个组件,设计一种多agent的创新方法;在这里都可以得到实现。
授课导师介绍:Kimi老师
-哈工大计算机博士,获2023年度国际青年科学家奖提名
-发表近20篇学术论文,其中包括ACL/EMNLP等
-担任多个中科院一区Top期刊的审稿专家
-研究方向:自然语言处理,小样本,医疗文本处理、法律文本处理等

了解课程详情
作为日常为了论文而忙碌的科研人,小编知道大家一定很需要一些资料。因此,小编精心整理了一份超过20G的AI顶会论文大礼包!包含最新顶会论文、书籍等资料,以及引文论文写作指导保姆级资料,从文献阅读到论文写作,全部帮你整理好~


扫码免费领课程资料↑
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢