
本篇文章介绍来自南洋理工大学的论文 ReVersion: Diffusion-Based Relation Inversion from Images,研究图像生成中的Relation定制化。
详细信息如下:

论文:https://arxiv.org/abs/2303.13495 代码:https://github.com/ziqihuangg/ReVersion 主页:https://ziqihuangg.github.io/projects/reversion.html 视频:https://www.youtube.com/watch?v=pkal3yjyyKQ Demo:https://huggingface.co/spaces/Ziqi/ReVersion

新任务:Relation Inversion
今年,diffusion model 和相关的定制化(personalization)的工作越来越受人们欢迎,例如 DreamBooth,Textual Inversion,Custom Diffusion 等,该类方法可以将一个具体物体的概念从图片中提取出来,并加入到预训练的text-to-image diffusion model中,这样一来,人们就可以定制化地生成自己感兴趣的物体,比如说具体的动漫人物,或者是家里的雕塑,水杯等等。
现有的定制化方法主要集中在捕捉物体 外观(appearance) 方面。然而,除了物体的外观,视觉世界还有另一个重要的支柱,就是物体与物体之间千丝万缕的 关系(relation) 。目前还没有工作探索过如何从图片中提取一个具体关系(relation),并将该relation作用在生成任务上。为此,我们提出了一个新任务:Relation Inversion 。
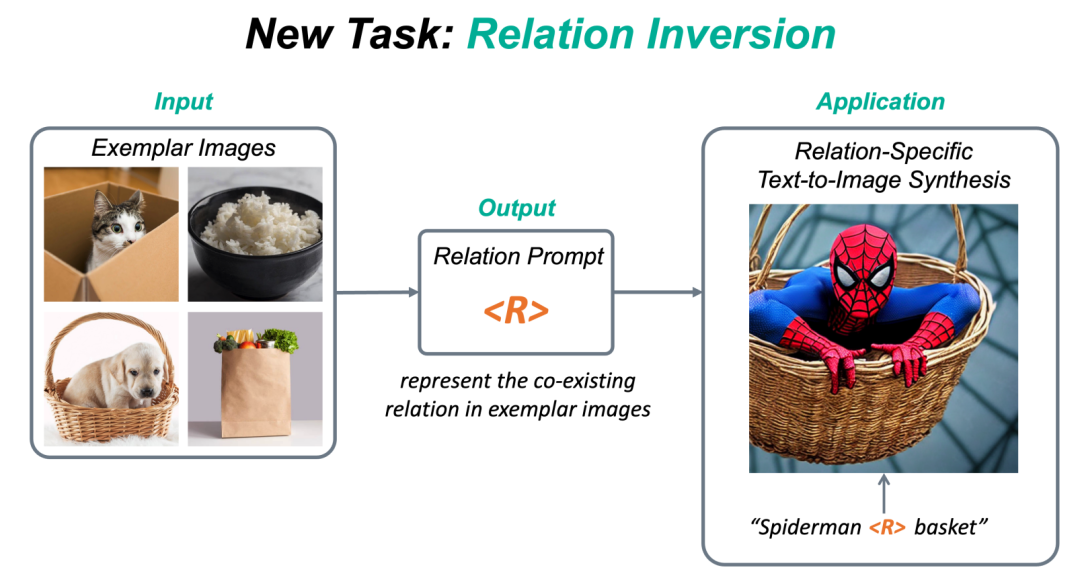
如上图,给定几张参考图片,这些参考图片中有一个共存的relation,例如“物体A 被装在 物体B中”,Relation Inversion的目标是找到一个relation prompt
ReVersion框架
作为针对Relation Inversion问题的首次尝试,我们提出了ReVersion框架:
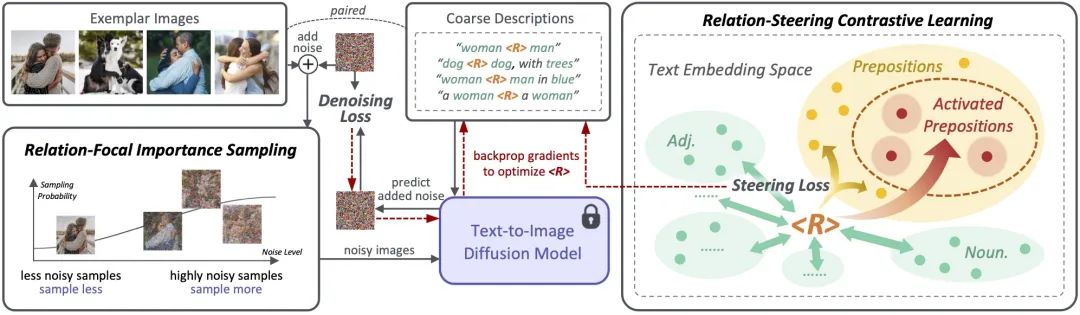
相较于已有的Appearance Invesion任务,Relation Inversion任务的难点在于怎样告诉模型我们需要提取的是relation这个相对抽象的概念,而不是物体的外观这类有显著视觉特征的方面。
我们提出了relation-focal importance sampling策略来鼓励<R>更多地关注high-level的relation;同时设计了relation-steering contrastive learning来引导 <R>更多地关注relation,而非物体的外观。更多细节详见论文。
ReVersion Benchmark
我们收集并提供了
ReVersion Benchmark:https://github.com/ziqihuangg/ReVersion#the-reversion-benchmark
它包含丰富多样的relation,每个relation有多张exemplar images以及人工标注的文字描述。我们同时对常见的relation提供了大量的inference templates,大家可以用这些inference templates来测试学到的relation prompt
结果展示
丰富多样的relation
我们可以invert丰富多样的relation,并将它们作用在新的物体上


丰富多样的背景以及风格
我们得到的relation

同一个 Relation,丰富多样的物体组合

推荐阅读
西电IEEE Fellow团队出品!最新《Transformer视觉表征学习全面综述》 润了!大龄码农从北京到荷兰的躺平生活(文末有福利哟!) 如何做好科研?这份《科研阅读、写作与报告》PPT,手把手教你做科研 奖金675万!3位科学家,斩获“中国诺贝尔奖”! 又一名视觉大牛从大厂离开!阿里达摩院 XR 实验室负责人谭平离职 最新 2022「深度学习视觉注意力 」研究概述,包括50种注意力机制和方法! 【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载! 2021李宏毅老师最新40节机器学习课程!附课件+视频资料
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢