
全文速览
金属有机框架(MOFs)是一类具有高度可调的纳米多孔结构和主客体相互作用的气体吸附材料。虽然机器学习(ML)已被用来帮助设计或筛选用于不同目的的MOF,但大数据的需求并不总是得到满足,这限制了针对小数据集训练的ML模型的适用性。在这项工作中,作者引入了一种归纳迁移学习技术,以提高用少量MOF吸附数据训练的ML模型的准确性和适用性。该技术利用来自源任务的潜在可共享知识来改进目标任务的模型。作为演示,使用在100bar和243K下具有13506个MOF结构的H2吸附数据上训练的深度神经网络(DNN)作为源任务。当将知识从源任务转移到100bar和130K下的H2吸附(一个目标任务)时,目标任务的平均预测精度从0.960(直接训练)提高到0.991(迁移学习),迁移学习在89.3%的情况下有效。作者还测试了不同气体种类(即从H2到CH4)的迁移学习,CH4吸附的平均预测精度从0.935(直接训练)提高到0.980(迁移学习),迁移学习在82.0%的情况下有效。更重要的是,通过直接训练,迁移学习可以有效地改进目标任务的模型,但精度较低。然而,当将知识从源任务转移到Xe/Kr吸附时,转移学习并没有显著提高预测准确性,甚至在约50.0%的情况下使预测准确性变差,这归因于缺乏对基础知识至关重要的通用描述符。
背景介绍
金属-有机框架(MOFs)是一类高度可调的纳米多孔材料,具有特殊的主客体性质。可用于制造MOFs的金属节点和有机连接体的几乎无限的组合导致了一类极其多样化的材料,从而导致了MOFs可应用的同样多样化的应用,如气体储存、催化、非线性光学和光采集。大量可能的结构既带来了机遇,也带来了挑战。机会是显而易见的,因为可能会发现新材料优于当前技术,或者可能具有新应用的新特性。挑战在于寻找那些性能优异的结构,因为合成和表征这些材料的实验工作可能需要耗费时间和资源。因此,计算机模拟在许多应用的MOF的发现和设计中发挥了重要作用。
先进的分子模拟技术使计算MOFs的结构和功能特性变得可靠,只考虑材料的晶体结构。例如,MOF的气体吸收能力可以在不到半小时的时间内在现代工作站上通过蒙特卡罗(GCMC)模拟来预测。然而,最近的硅MOF设计产生了由数十万个MOF结构组成的材料数据库,这些结构可用于高通量计算筛选。即使使用快速方法生成模拟参数和表征材料,对如此巨大的搜索空间进行彻底筛选也可能令人望而却步。
在这项工作中,作者将TL应用于训练DNN替代模型,以预测不同MOF结构中气体的吸附能力。作者利用生成的13 506 MOF结构的数据库,这些结构由5个纹理描述符值(Void fraction,Vol.美国,Grav.nenenebb S.A.,孔隙极限直径和最大空腔直径)的矢量和计算的气体吸收能力表示。作为第一个演示,作者将从使用一个条件(100bar和243K)下的完整13506个H2吸收数据点(即源任务)训练的DNN中学习到的知识转移到使用另一个条件下(100bar,130K)的有限数据集(数据大小为100)构建另一个新DNN中。作者的结果表明,与使用小数据集的直接训练相比,可以提高预测准确性。然后,作者将从源任务中学到的知识转移到构建用于甲烷吸附的DNN中,并且改进再次明显。作者发现,这些情况之间优异的可转移性源于影响这些气体吸附的MOF结构的关键描述符的共同性。基于进一步的分析,TL将以较低的可推广性(即测试集的预测准确性较低)处理目标任务。然而,TL无法提高Xe/Kr吸附的预测精度,这可归因于控制结构-性质关系的关键描述符的差异。作者的研究证明了TL在气体吸附MOFs筛选中的适用性,但它也表明,包括正确的描述符可能是应用TL的限制因素。
数据集与方法
数据集:作者工作中使用的数据集包含41种不同拓扑结构的13506个MOF,这些MOF由自上而下的MOF构建包ToBaCCo.3通过(1)在固定晶胞晶格参数的同时进行优化,从而在最大限度地减少过度结构变形的同时释放任何键应变,从而使用Materials Studio中的Forcete模块对每个MOF结构进行能量优化;(2)重新优化,同时取消对晶胞晶格参数的固定。然后计算MOF的文本描述符。MOFs的表面积(包括体积表面积(Vol.美国)和重量表面积(Grav.nenenebb S.A.))通过在框架原子上滚动氮探针来计算;使用He的Widom插入计算MOFs的空隙率(空隙率);使用Zeo++计算MOFs的孔隙极限直径(PLD)和最大空腔直径(LCD)。之后,使用GCMC计算这些拓扑上不同的MOFs组吸附H2、CH4和Xe/Kr混合物的能力,使用RASPA代码实现。
迁移学习:具有两个隐藏层的DNNs用于量化结构描述符和气体吸附之间的关系,其结构如图1a所示。作者首先使用100bar和243K(源任务)下的完整13006 H2吸收数据点来训练DNN,并保存其权重。当为其他任务训练DNN时,而不是从头开始学习(称之为直接学习(DL)),作者微调来自源任务的预训练DNN的输出层和最后一个隐藏层之间的权重(即,使用预训练的权重作为初始值),同时保持其他权重固定(由于这是归纳迁移学习,前几层共享相同域的表示),使用可用于新目标任务的较小数据集(图1b)。
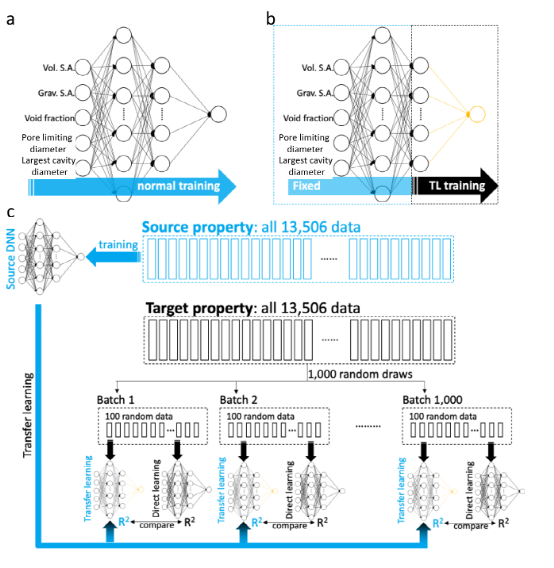
图1。用于说明TL的示意图:(a)训练DNN的正常过程;(b)在TL场景中,只有输出层和最后一个隐藏层之间的参数被微调;(c)TL性能测试程序示意图。
结果与讨论
作者首先使用在100bar和243K下H2吸附的完整数据集(13506数据)作为源任务来训练DNN(训练细节可以在方法部分中找到)。训练后的DNN在测试集上具有0.998的高决定系数(R2)。然后将TL应用于三个目标任务:(1)在不同条件(100bar和130K)下的H2吸附;(2) CH4在100bar和298K下的吸附;和(3)在5bar和298K下的Xe/Kr吸附。对于每个目标任务,在DL和TL场景中使用1000批随机选择的数据集(以使结果具有统计学意义),每个数据集的大小为100个数据点(图1c)。
小数据集可以使直接学习的预测精度因随机数据绘制而不同,这可以在下面观察到,因此TL可以通过非常不同的可推广性水平进行全面测试,结果可以更具代表性。
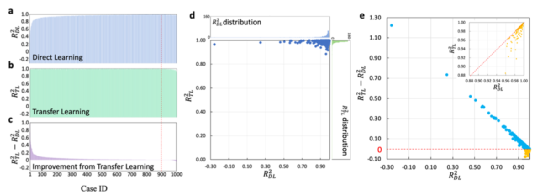
图2:从100bar和243K下的H2吸附到100bar和130K下的氢气吸附的迁移学习:所有1000个目标案例的(a)直接学习(RDL2)、(b)迁移学习(RTL2)和(c)从迁移学习的改进(RTL2−RDL2)的R2。面板(a−c)中的案例ID按RTL2−RDL2降序排列。(d) RTL2相对于RDL2绘制,还示出了它们各自的分布。(e) RTL2−RDL2作为RDL2的函数,其中插图显示RTL2−RDL2<0的情况下RTL2与RDL2的比较。
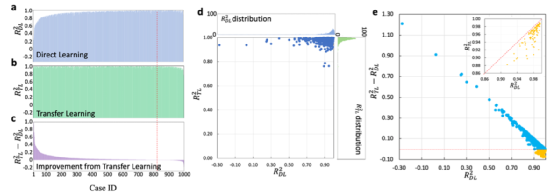
图3。从100bar和243 K下的H2吸附到100bar和298 K下的CH4吸附的迁移学习:(a)直接学习(RDL2)、(b)迁移学习(RTL2)和(c)所有1000个目标案例的迁移学习改进(RTL2−RDL2)的R2。面板(a−c)中的案例ID按RTL2−RDL2降序排列。(d) RTL2相对于RDL2绘制,还示出了它们各自的分布。(e)RTL2−RDL2作为RDL2的函数,其中插图显示RTL2−RDL2<0的情况下RTL2与RDL2的比较。
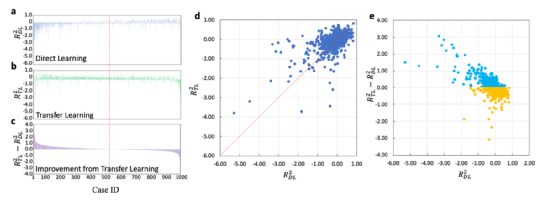
图4。从100bar和243K下的H2吸附到5bar和298K:R2下的Xe/Kr吸附的迁移学习,用于(a)直接学习(RDL2)、(b)迁移学习(RTL2)和(c)所有1000个目标案例的迁移学习改进(RTL2−RDL2)。面板(a−c)中的案例ID按RTL2−RDL2降序排列。(d) RTL2相对于RDL2绘制。(e) RTL2−RDL2作为RDL2的函数。
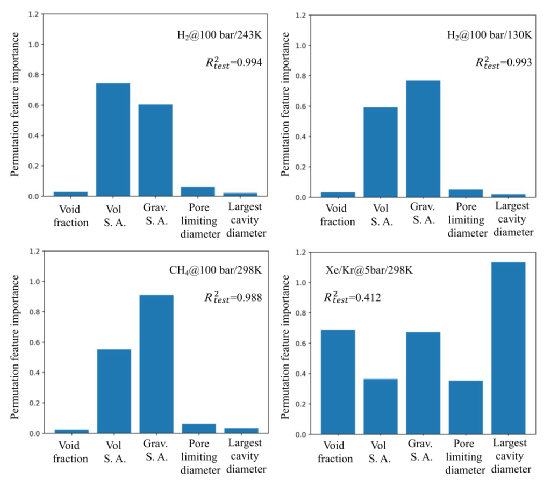
图5。使用DNN的描述符和标签之间的定量关系,以及相应排列特征重要性的测量。
结果与展望
总之,基于DNNs对MOF中不同气体吸附进行了详细的TL研究。知识被证明在不同条件下的H2吸附之间以及从H2吸附到CH4吸附之间是非常可转移的。TL被证明在DL测试集预测精度较低的目标任务中更有效,并且它可以帮助避免性能非常低的模型。然而,当源任务和目标任务之间没有可共享的知识时,TL失败了,从H2吸附转移到Xe/Kr混合物吸附的案例研究证明了这一点。通过对所有四种气体吸附的整个数据集的排列特征重要性的研究,可以理解,本研究中使用的纹理描述符并不总是适合于对结构-性质关系进行建模。因此,TL在可以由相同描述符描述的任务中运行良好,而在由不同描述符主导的任务中可能失败。
原文链接:https://dx.doi.org/10.1021/acsami.0c06858

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢