

“大模型格局又双叒叕变天了!”
在刚刚过去的两个月里,大量的大模型依然密集地发布着。伴随着一波波的宣传,大模型界更是动辄变天,天气实在不太稳定。

如今,大模型界看似都是在神仙打架,评测的标准也是一团迷雾,让人真假莫辩。为了解决大家的疑惑,OpenCompass 团队将会在每个月定期发布大模型评测月度榜单,对当月的热门大模型进行五大能力维度的全面评测,主打一个开放、全面、可复现。
另外,我们也会尝试在评测的数据中定位一些有趣的研究方向,希望共同促进大模型界的进步。

废话不多说,我们先来看一下 OpenCompass 发布后的一个多月里都有哪些大模型的新闻。
大模型 7-8 月进展速览
7 月 6 日,上海人工智能实验室发布了书生·浦语开源体系,开源了书生·浦语的轻量版本(InternLM-7B)以及全链条工具体系,首次在国内提供完全免费的商用许可;
7 月 11 日,百川智能发布 Baichuan-13B 模型;
7 月 14 日,智谱科技宣布 ChatGLM2-6B 免费商用;
7 月 15 日,Google 发布 Bard升级,开放多语言能力,支持中文对话,支持图文理解;
7 月 18 日,FlashAttention v2 发布,比标准 Attention 提速 5-9 倍
7 月 19 日,Meta 开源了性能更强的 Llama-2,提供了更加宽松的商用许可。
8 月 2 日,清华等机构提出工具模型 ToolLLM,支持调用各类工具 API
8 月 3 日,阿里巴巴开源了千问 7B 模型,支持长文本与工具调用
8 月 10 日,斯坦福开源了基于大语言模型的“虚拟小镇”
8 月 18 日,字节跳动“豆包”开启邀测
8 月 24 日,好未来开源数学领域千亿大模型 MathGPT
8 月 25 日,Meta开 源了专攻代码生成的基础模型 Code Llama
OpenCompass 更新速览
OpenCompass 旨在为社区提供灵活易用,功能强大的大模型评测工具和榜单。基于社区用户的反馈,我们新增了一批重磅功能,让我们一起快速了解一下:
扩展开源数据集支持情况,新增 LLM 评测集 Xiezhi, SQuAD2.0, ANLI, CMMLU
提供长文本评测能力,支持 L-Eval, LongBench 等长文本评测集
开放多模态评测能力,支持 MMBench, SEED-Bench, MME, ScienceQA 等十余个多模态评测集
提升代码评测能力,支持 HumanEval-X,并提供统一的多语言代码能力测试环境
天花板 GPT-4 到底有多强
在过去的两个月里,我们重点测评了数个热门的大语言模型,包括新推出的 LLaMA2, StableBeluga2, ChatGPT 和 GPT4,并同步向社区开放了详细的模型性能报告。
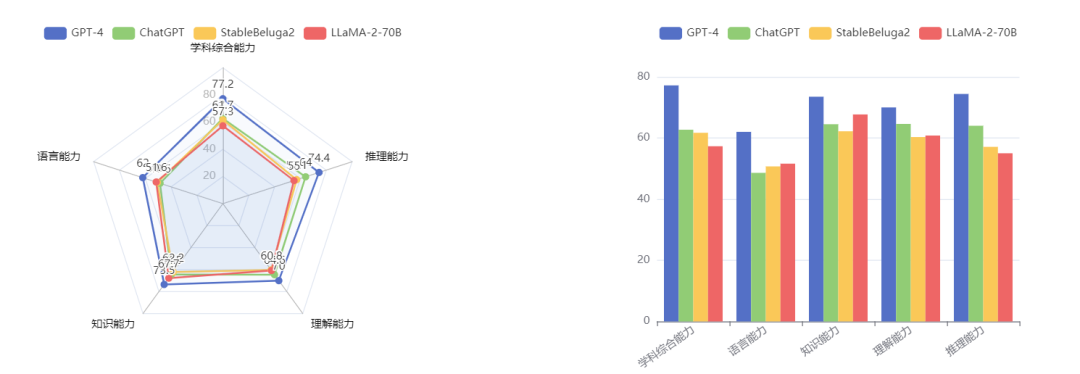
图片来源:OpenCompass 大模型性能对比功能
基于 OpenCompass 大模型评测平台的性能榜单,我们可以看出:
GPT 系模型性能强劲,推理能力突出:GPT4 以绝对优势在所有维度上超越其他 65B 以上量级模型,相较于 ChatGPT 各方面能力跃升了 5-15 个百分点不等,是大语言模型里当之无愧的霸主。同时,尽管已经推出半年有余,综合名次第二位的 ChatGPT 相较最新的开源模型也仍然优势明显。总的来说,GPT 系模型在涉及推理的任务上极大领先于开源模型,而在强调记忆的任务上(语言、知识)优势则相对缩小。
开源模型 LLaMA-2 性能相比上代提升明显:在开源模型方面,近期开源的 LLaMA-2 及 StableBeluga2 性能相近,总体比起 LLaMA 进步明显。其中,LLaMA-2 的知识、StableBeluga2 的语言能力表现突出,分别超越了 ChatGPT;然而,它们与 ChatGPT 在其它方面差距仍然较大,其中数学评测集 MATH 和代码评测集 HumanEval 的差距都超过了一倍,仍需继续追赶。
中英文考试,大模型学科综合能力几何?
多元化考试通常会与实际应用场景更加贴近,且具有一定的挑战性。我们选用了 C-Eval、AGIEval、MMLU、GAOKAO-Bench、ARC-c/e, CMMLU 等 多个中英文多领域的数据集来进行性能评估。GPT4 优势依然十分明显,但 ChatGPT 已经在 C-Eval、AGIEval、MMLU 上被开源模型几近追平。
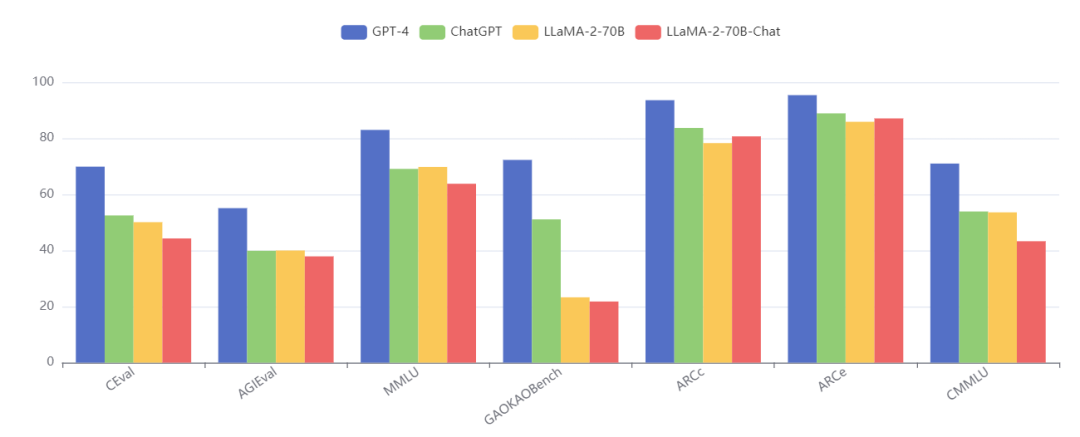
图片来源:OpenCompass 大模型性能对比功能
社区开源模型评测结果速览
大模型评测是一项复杂的系统性工程,如何构建合理的评测集与公平的评测方式,期待产业界和学术界持续共同探索。OpenCompass 基于学术社区的 50+ 余个主流中英文评测集上开展评测分析,并发布 8 月中英文综合榜单(相关评测结果受评测集,评测方法等限制,仅反映在 OpenCompass 现有能力维度体系下的模型性能)。
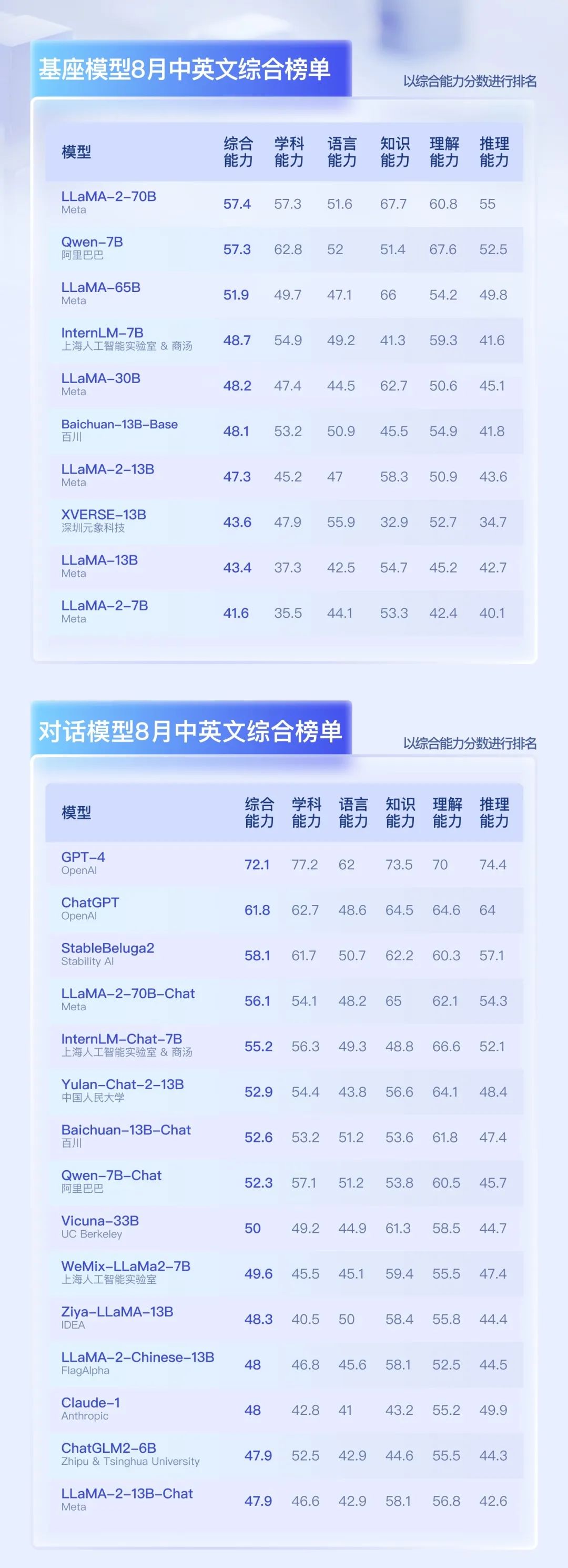
需要注意的是本榜单是在学术客观评测集上对模型的多种能力进行评测,主要反映在自然语言处理相关任务上的基础能力。
同时 OpenCompass 团队正在开展主观评测体系的构建,OpenCompass 主观评测排行榜也即将出炉,敬请期待(也欢迎学术界与企业界的各类模型与我们联系开展全方位的模型能力评测)
大模型评测探索方向
一如本文开头所提到的,尽管当今流行的开源大语言模型已经在记忆为主的任务上领先了 ChatGPT,但在考试、推理、理解等三个普遍需要推理能力的维度上仍然一致落后。显然,现今流行的开源训练方案并不能很好地提升模型的推理能力。
虽然目前学界已经存在许多关于激发 LLM 推理能力的研究,但我们更期待能有更多的研究从训练维度展开,最终产生一种简洁而通用的范式,根本地提升模型的推理能力。
此外,在评测 GPT 系模型的时候,我们发现了一个比较有趣的现象。它们有时并不会严格地跟随用户指令,但会返回更符合使用场景的回复。例如,我们在测评 HumanEval 时使用的一段 prompt 如下:
Complete the following python code:from typing import Listdef separate_paren_groups(paren_string: str) -> List[str]:""" Input to this function is a string containing multiple groups of nested parentheses. Your goal is toseparate those group into separate strings and return the list of those.Separate groups are balanced (each open brace is properly closed) and not nested within each otherIgnore any spaces in the input string.>>> separate_paren_groups('( ) (( )) (( )( ))')['()', '(())', '(()())']"""
在之前的评测中,其它模型的输出通常会严格跟随指令,只输出后半段的代码。而 GPT-4 则更加倾向于输出完整的解释、代码(甚至测例),这样用户在交互时便可以一键复制并测试代码:
Here is a Python function that does the task:```pythonfrom typing import Listdef separate_paren_groups(paren_string: str) -> List[str]:# Remove spaces from the input stringno_space_string = paren_string.replace(" ", "")paren_groups = []start = 0open_count = 0for i, char in enumerate(no_space_string):if char == '(':open_count += 1elif char == ')':open_count -= 1if open_count == 0:paren_groups.append(no_space_string[start:i+1])start = i+1return paren_groups```This function works by iterating over the input string and keeping track of the number of open parentheses. When it encounters a closing parenthesis that matches an open one (i.e., the count of open parentheses becomes zero), it knows that it has found a complete group, so it adds this group to the list and starts looking for the next one.
类似地,GPT-3.5 也会返回一个完整的函数,但不包含语言上的解释。尽管 GPT4 对比 GPT3.5 在 HumanEval 数值上的提升看似不大,但无法被量化的“用户体验”却是大大提升的。
在其它一些数据集如 SIQA 中,GPT4 的表现也略逊于 GPT3.5,因为它会更倾向于拒绝回答它认为信息不足的问题,而并不会严格地跟随指令。
Sasha protected the patients' rights by making new laws regarding cancer drug trials.Question: What will patients want to do next?A. write new lawsB. get petitions signedC. live longerAnswer:GPT-3.5: C. live longerGPT-4: The text does not provide information on what the patients will want to do next.
在当前的评测模式下,模型的客观指标测量很大程度上受制于指令跟随性。但指令跟随性的降低与模型的客观性能并不完全相关,它可能是模型在训练时,对于其它方面存在考量所致。
因此,在传统客观指标之外,如何更好地量化模型的指令跟随性及对场景的适应性,并以此指导未来训练的模型,也是亟需业界关注的问题。
社区共建
OpenCompass 现已接入多个优秀开源项目,例如:
大模型 Agent 框架:
https://github.com/InternLM/lagent
大模型微调工具:
https://github.com/InternLM/xtuner
大模型部署工具:
https://github.com/InternLM/lmdeploy
书生·浦语大模型:
https://github.com/InternLM/InternLM
TigerBot 大模型:
https://github.com/TigerResearch/TigerBot
中文大模型评测数据集:
https://github.com/haonan-li/CMMLU
.......
诚挚欢迎更多社区项目加入 OpenCompass 生态,一同持续提升大模型能力。
我们也正在积极筹备组建贡献者组织 OpenCompass SIG,第一期为社区小伙伴们精心准备了 10+ 数据集支持社区共建任务,欢迎大家访问以下链接领取任务,完成任务将获得一定积分,累计 50 积分可兑换定制抱枕、鼠标垫和水杯等精美周边~
https://github.com/open-compass/opencompass/discussions/categories/community-task

滴水聚江海,欢迎小伙伴们扫描上方二维码加入 OpenCompass 社区交流群~
未来展望
随着大模型相关领域的快速发展,如何科学、全面、公平的评估模型能力,对于指导大模型迭代与进步起着至关重要的作用。OpenCompass 作为开源大模型评测平台,将持续提供更丰富完善的评测功能,并支持更多社区评测数据集。
欢迎登录 OpenCompass 官网获取更多信息:
https://opencompass.org.cn/
大模型评测榜单:
https://opencompass.org.cn/leaderboard-llm
多模态评测榜单:
https://opencompass.org.cn/leaderboard-multimodal
大模型评测工具:
https://github.com/open-compass/opencompass
OpenCompass GitHub:
https://github.com/open-compass/
2023-08-30

2023-08-29

2023-08-28



点击下方“阅读原文”直达 OpenCompass
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢