
今天是8月31日,星期四,繁忙的八月终于过去。
我们继续来谈谈知识库增强大模型问答的话题,今天学到一个新词,RAG (Retrieval-Augmented Generation),指的是通过 RAG 模型来对搜索结果进行增强的过程,这个就是我们一直说的外挂知识库。
在之前的文章中我们介绍了llamaindex利用摘要索引进行增强的方案,但这些都是利用非结构化文本在做。
最近看到一个工作很有趣,https://siwei.io/graph-rag/,结合知识图谱来作为一路召回,提高检索的相关性,这个可以利用好知识图谱内部的知识。
知识图谱可以减少基于嵌入的语义搜索所导致的不准确性。
该工作举了一个很形象的例子,“保温大棚”与“保温杯”,尽管在语义上两者是存在相关性的,但在大多数场景下,这种通用语义(Embedding)下的相关性很高,进而作为错误的上下文而引入“幻觉”。这时候,可以利用领域知识的知识图谱来缓解这种幻觉。
本文对该方法以及优化方案进行介绍,供大家一起参考。
一、Graph RAG具体实现思路
Graph RAG是由悦数图数据提出的概念,是一种基于知识图谱的检索增强技术,通过构建图模型的知识表达,将实体和关系之间的联系用图的形式进行展示,然后利用大语言模型 LLM进行检索增强。
Graph RAG 将知识图谱等价于一个超大规模的词汇表,而实体和关系则对应于单词。通过这种方式,Graph RAG 在检索时能够将实体和关系作为单元进行联合建模。
一个简单的 Graph RAG 思想在于,对用户输入的query提取实体,然后构造子图形成上下文,最后送入大模型完成生成,如下代码所示:
def simple_graph_rag(query_str, nebulagraph_store, llm):
entities = _get_key_entities(query_str, llm)
graph_rag_context = _retrieve_subgraph_context(entities)
return _synthesize_answer(
query_str, graph_rag_context, llm)
首先,使用LLM(或其他)模型从问题中提取关键实体。
def _get_key_entities(query_str, llm=None ,with_llm=True):
...
return _expand_synonyms(entities)
其次,根据这些实体检索子图,深入到一定的深度,例如可以是2度甚至更多。
def _retrieve_subgraph_context(entities, depth=2, limit=30):
...
return nebulagraph_store.get_relations(entities, depth, limit)
最后,利用获得的上下文利用LLM产生答案。
def _synthesize_answer(query_str, graph_rag_context, llm):
return llm.predict(PROMPT_SYNTHESIZE_AND_REFINE, query_str, graph_rag_context)这样一来,知识图谱召回可以作为一路和传统的召回进行融合。
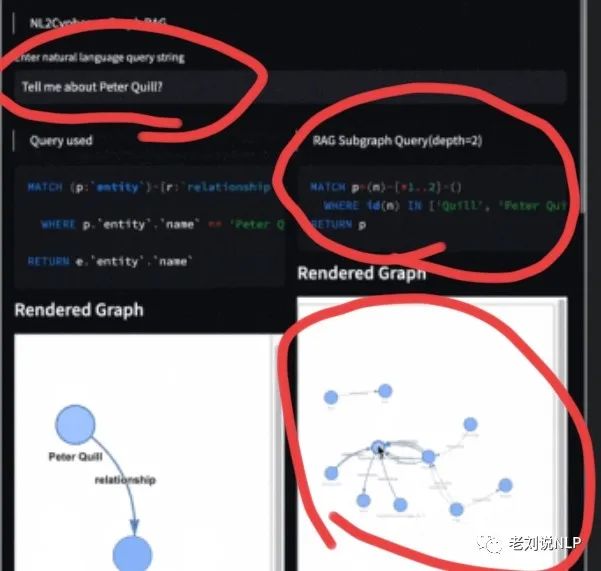
例如,下图所示,当用户输入,tell me about Peter quill时,先识别关键词quil,编写cypher语句获得二跳结果。
又如,如下例子来说明:
用户输入:Tell me events about NASA
得到关键词:Query keywords: ['NASA', 'events']
召回二度逻辑:
Extracted relationships: The following are knowledge triplets in max depth 2 in the form of `subject [predicate, object, predicate_next_hop, object_next_hop ...]
nasa ['public release date', 'mid-2023']
nasa ['announces', 'future space telescope programs']
nasa ['publishes images of', 'debris disk']
nasa ['discovers', 'exoplanet lhs 475 b']
送入LLM完成问答。
INFO:llama_index.indices.knowledge_graph.retriever:> Starting query: Tell me events about NASA
> Starting query: Tell me events about NASA
> Starting query: Tell me events about NASA
INFO:llama_index.indices.knowledge_graph.retriever:> Query keywords: ['NASA', 'events']
> Query keywords: ['NASA', 'events']
> Query keywords: ['NASA', 'events']
INFO:llama_index.indices.knowledge_graph.retriever:> Extracted relationships: The following are knowledge triplets in max depth 2 in the form of `subject [predicate, object, predicate_next_hop, object_next_hop ...]`
nasa ['public release date', 'mid-2023']
nasa ['announces', 'future space telescope programs']
nasa ['publishes images of', 'debris disk']
nasa ['discovers', 'exoplanet lhs 475 b']
> Extracted relationships: The following are knowledge triplets in max depth 2 in the form of `subject [predicate, object, predicate_next_hop, object_next_hop ...]`
nasa ['public release date', 'mid-2023']
nasa ['announces', 'future space telescope programs']
nasa ['publishes images of', 'debris disk']
nasa ['discovers', 'exoplanet lhs 475 b']
> Extracted relationships: The following are knowledge triplets in max depth 2 in the form of `subject [predicate, object, predicate_next_hop, object_next_hop ...]`
nasa ['public release date', 'mid-2023']
nasa ['announces', 'future space telescope programs']
nasa ['publishes images of', 'debris disk']
nasa ['discovers', 'exoplanet lhs 475 b']
INFO:llama_index.token_counter.token_counter:> [get_response] Total LLM token usage: 159 tokens
> [get_response] Total LLM token usage: 159 tokens
> [get_response] Total LLM token usage: 159 tokens
INFO:llama_index.token_counter.token_counter:> [get_response] Total embedding token usage: 0 tokens
> [get_response] Total embedding token usage: 0 tokens
> [get_response] Total embedding token usage: 0 tokens
INFO:llama_index.token_counter.token_counter:> [get_response] Total LLM token usage: 159 tokens
> [get_response] Total LLM token usage: 159 tokens
> [get_response] Total LLM token usage: 159 tokens
INFO:llama_index.token_counter.token_counter:> [get_response] Total embedding token usage: 0 tokens
> [get_response] Total embedding token usage: 0 tokens
> [get_response] Total embedding token usage: 0 tokens二、再谈进一步的排序优化方式
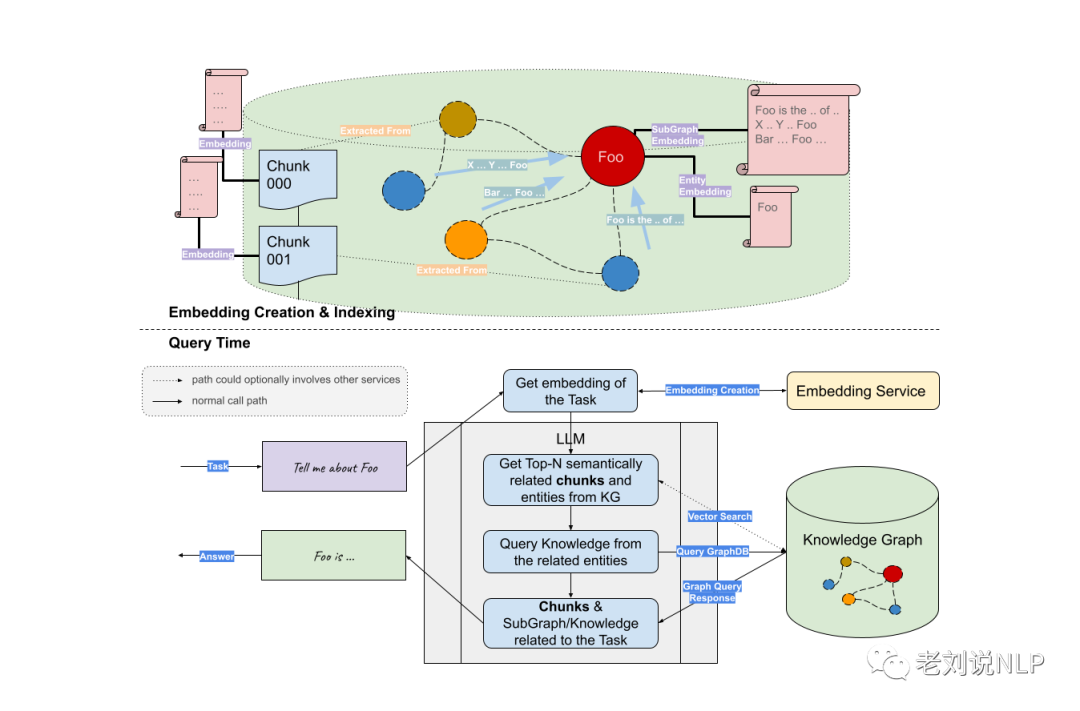
基于知识图谱召回的方法可以和其他召回方法一起融合,但这种方式在图谱规模很大时其实是有提升空间的。
突出的缺点在于:
子图召回的多条路径中可能会出现多种不相关的。
实体识别阶段的精度也有限,采用关键词提取还比较暴力,方法也值得商榷。
这种方式依赖于一个基础知识图谱库,如果数据量以及广度不够,有可能会引入噪声。
因此,还可以再加入路径排序环节,可参考先粗排后精排的方式,同样走过滤逻辑。
例如,在粗排阶段,根据问题query和候选路径path的特征,对候选路径进行粗排,采用LightGBM机器学习模型,保留topn条路径:
• 字符重合数
• 词重合数
• 编辑距离
• path跳数
• path长度
• 字符的Jaccard相似度
• 词语的Jaccard相似度
• path中的关系数
• path中的实体个数
• path中的答案个数
• 判断path的字符是否全在query中
• 判断query和path中是否都包含数字 • 获取数字的Jaccrad的相似度
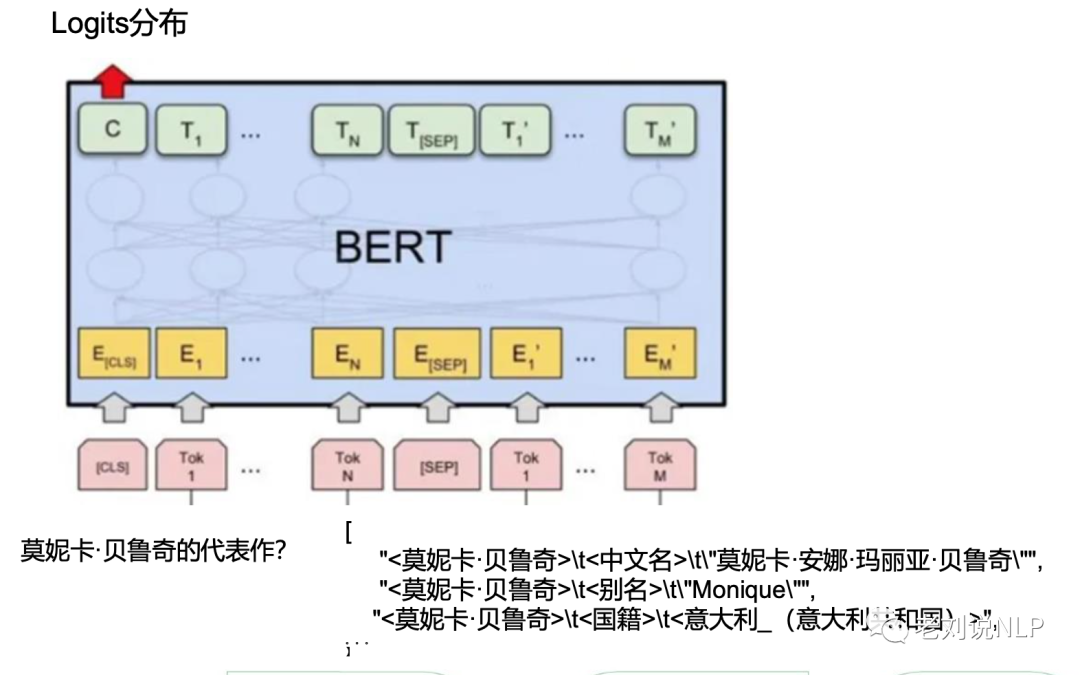
在精排阶段,采用预训练语言模型,计算query和粗排阶段 的path的语义匹配度,选择得分top2-3答案路径作为答案。
总结
本文主要介绍了基于知识图谱召回来进行大模型问答增强的方案,其思想很简单,也有很多优化空间,之前做实体链接、实体查询,路径排序这一套都可以集成进来。
知识图谱与大模型融合,缓解幻觉问题,值得关注。
参考文献
1、https://siwei.io/graph-rag/
2、https://mp.weixin.qq.com/s/xm_8jWIRL5zdFj_jZoxq9Q
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢