
MVDream: Multi-view Diffusion for 3D Generation
解决问题:该论文旨在解决从文本提示生成几何一致的多视图图像的问题,并通过Score Distillation Sampling实现3D生成的多视图先验模型的稳定性。
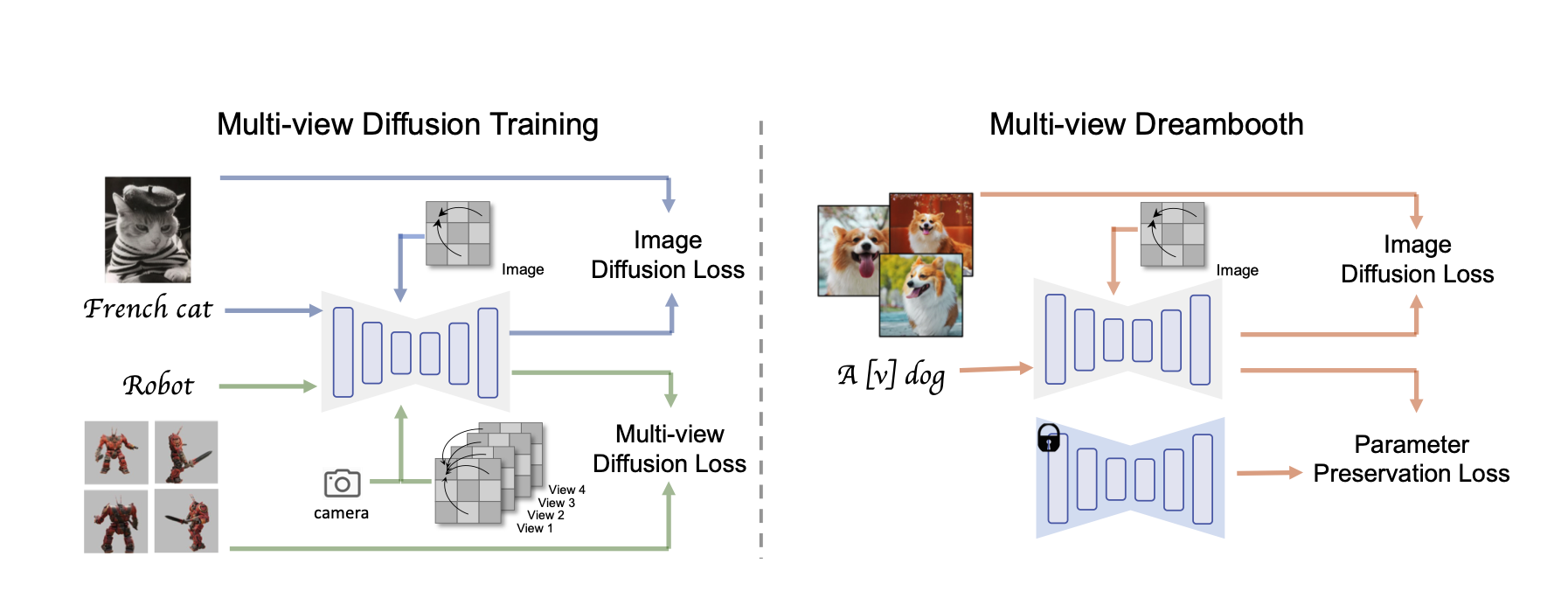
关键思路:该论文的关键思路是利用预先在大规模网络数据集上训练的图像扩散模型和从3D资产渲染的多视图数据集来实现多视图扩散模型。该模型可以同时实现2D扩散的一般性和3D数据的一致性,从而成为3D生成的多视图先验。通过Score Distillation Sampling,该模型可以解决现有2D-lifting方法的3D一致性问题,从而极大地提高了模型的稳定性。
其他亮点:该论文的实验设计合理,使用了多视图数据集和大规模网络数据集。该论文还提出了一种个性化3D生成的方法,即DreamBooth3D应用程序。该方法可以在几次训练后学习主体身份并保持一致性。该论文未提供开源代码。
相关研究:最近的相关研究包括“NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections”(Ben Mildenhall等,UC Berkeley)和“Generative Modeling for Multi-View Human Body Pose Estimation”(Jiahui Zhang等,UC Berkeley)。
论文摘要:我们提出了MVDream,这是一个多视角扩散模型,能够根据给定的文本提示生成几何一致的多视角图像。通过利用在大规模网络数据集上预训练的图像扩散模型和从3D资产渲染出的多视角数据集,最终的多视角扩散模型可以实现2D扩散的通用性和3D数据的一致性。这样的模型可以作为Score Distillation Sampling的多视角先验,用于3D生成,从而通过解决3D一致性问题,极大地提高了现有2D-lifting方法的稳定性。最后,我们展示了多视角扩散模型也可以在少样本情况下进行微调,用于个性化3D生成,即DreamBooth3D应用程序,在学习主体身份后可以保持一致性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢