

作者 | Guodun Li
整理 | NewBeeNLP
大家好,这里是 NewBeeNLP。今天分享一篇 KDD 2023论文,来自Pinterest,相信大家都听说过他家那篇经典的 PinSage。
Pinterest是一家位于美国的图片分享社交平台,类似于国内的小红书,月活达4亿,营收主要来自于广告投放。其广告服务平台也采用了经典的多级漏斗模式,分为Ads Targeting, Ads Retrieval, Ads Ranking和Ads Auction。
这篇文章主要研究了在召回阶段面临的样本选择偏差问题,以及调研了包括二分类、batch内负采样、蒸馏、迁移学习、对抗学习以及无监督域适应策略在缓解该问题的表现,设计了一种改进的无监督域适应策略部署到线上,提高了转化率,降低了广告成本。
论文:An Empirical Study of Selection Bias in Pinterest Ads Retrieval 链接:https://dl.acm.org/doi/10.1145/3580305.3599771 会议:KDD2023
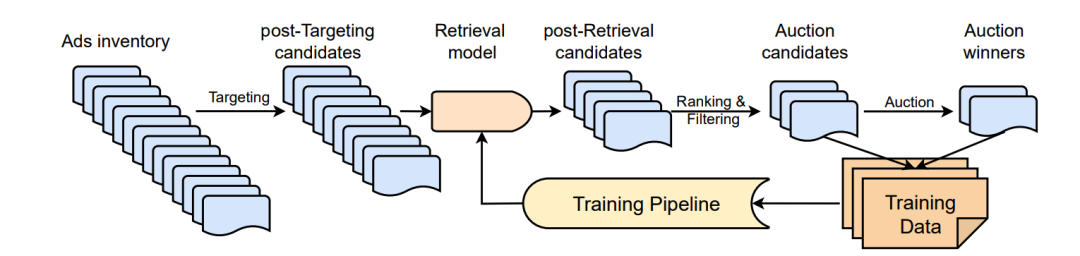
Pinterest广告漏斗分为Ads Targeting, Ads Retrieval, Ads Ranking和Ads Auction四个阶段,首先通过定向模块圈选出符合广告主要求的数百万候选,而后通过召回、排序模块进一步过滤,最后经过拍卖模块返回十几个真正展现给用户的物料。
在这个过程中,采用双塔DNN的召回模型的训练物料由两部分构成:经过排序模型过滤得到的Auction Candidates,以及真正展现给用户的Auction winners。
召回模型学习的目标则是排序模型的预估值。召回模型采用天级更新的策略,即T天数据训练,T+1天数据进行评估。很明显,在这个流程中同样存在经典的样本选择偏差SSB问题,即训练集的样本空间是排序后的候选和展现样本,而实际打分样本空间是近似全库的广告物料。

为了实锤这一问题,作者构造了三份天级别的数据集,来分析候选的后验转化率、点击率以及排序模型预估分在不同阶段候选的分布。
第一个是post-Targeting Candidates,也就是召回模型在serving时的实际打分对象(被称为unbiased dataset),第二个和第三个则是召回模型的训练集来源(称为biased dataset)。
实际在构造天级别的unbias dataset时,考虑到性能问题,每天采样10w个query,以及每个query采样6k个候选,并采用排序模型预估值作为伪标签。
从上图可以看到不同阶段的候选的分布明显的差异,即存在样本选择偏差现象,特别是用于召回模型学习的排序预估值分布不一样。
为了缓解该问题,作者实现和对比了一系列方案。
线上基线模型: 在biased dataset(即曝光样本+排序排出样本)上回归排序模型的预估值,损失函数是LogMAE,学习率1e-4,batch size 6144,输出向量32维,输出的激活函数是sigmoid,其他层是selu。
二分类: 仅在曝光样本上(即auction winners)利用BCE loss训练二分类任务,正例是真实点击广告,负例是曝光未点击广告。设计这个方案目的是为了证明线上基线为什么没直接用真实样本去做二分类。
Batch内负采样: 点击样本为正例,batch内其他query的点击样本为难负例,batch size=1000
知识蒸馏: 仅在曝光样本上回归排序模型的预估值
迁移学习: 考虑到训练和测试分布主要是candidate上的差异,所以双塔召回模型先在biased dataset上利用LogMAE回归排序模型的预估值,然后把query tower冻结住,继续在unbiased dataset上去微调ads tower。
对抗学习: 采用biased + unbiased dataset,在线上基线模型的loss上,额外加一个对抗loss,用DNN的中间输出作为一个单层MLP discriminator的输入,二分类dataset的来源,目的就是让模型区分不出source domain和target domain,loss也是经典的DANN做法。
无监督域适应: 把这个问题看做从source domain到target domain的transfer问题,target domain则是unbiased dataset,并通过biased dataset(source domain)上训练的精排模型去打伪标签,学习的目标就是只在unbiased dataset上去回归精排伪标签的预估值,loss同样用logMAE。优点是只在unbiased dataset上训,不会存在训练测试不一致问题,缺点主要是unbiased dataset本身就是sample的,数量少不能完全代表真实的target domain,同时source domain都是经过排序模块和拍卖模块筛出来的高质量候选,也没法代表真实的target domain。
作者主要从伪标签质量角度改进了上述朴素版本的无监督域适应方案,提出MUDA,即筛掉那些精排模型打分低置信度的样本。具体来说就是在unbiased dataset上去回归精排伪标签,但是需要先对精排预估值按照两个阈值(通过后验点击率来确定)进行三分桶,仅保留0号分桶和2号分桶的样本,标签也从预估值转成二分类,利用BCE loss训练。
上述模型在T+1天的有真实行为的曝光样本上评估,离线指标是AUC,除此以外还有△IMP(展现数相对基线变化率),△CTR(CTR变化率),△gCTR30(30s的CTR变化率),iCVR(转化率),Cost Per Action(CPA,平均每次用户行为的广告成本)。
离线评测结果中,和线上基线相比,二分类、蒸馏、迁移学习,对抗学习的AUC都差不多,因为他们都包含了曝光样本集合的训练,batch内负采样AUC很低,因为没有用真实负例去训练,UDA类的方法比基线低一些原因是仅在unbiased dataset上训练,评估集则是曝光样本集合。
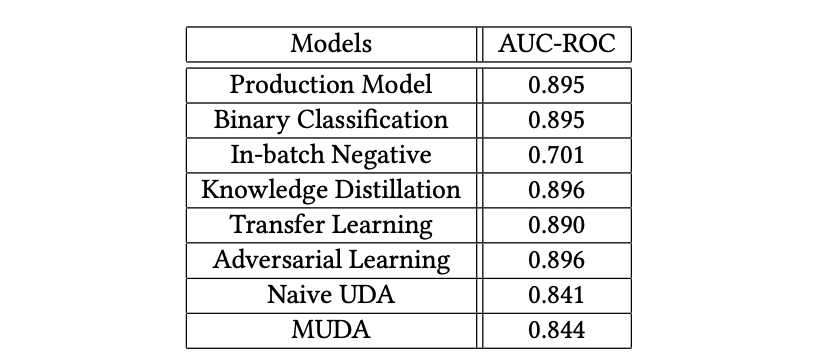
在线评测结果中,二分类的展现数提高,但点击率下降严重,说明通过漏斗的广告数变多,但是用户却不喜欢点;batch内负采样和蒸馏则是反着,这说明点击率的提升主要是通过漏斗的广告数变少,分母变小了。对比二分类,batch内负采样和蒸馏的ssb现象会更好些,因为二分类的负例都是同一个session下的,batch内则是其他session的,蒸馏的label相比binary也更有信息量。
迁移学习的gCTR30下降也较多,同时随着权重的热启,用户参与度也下降,主要是因为微调的unbiased dataset是随机sample的,可能缺少比较高质量的交互query-item pair去学好的表征。
对抗学习比迁移学习有更好的用户参与度,虽然展现数上涨幅度没迁移学习多。主要原因在于它搞了一个正则loss去约束模型不要太偏向学特定领域,同时,不像迁移学习,正则loss的label也不会依赖于unbiased dataset的质量。但是对抗学习的点击率还是有所下降,说明相比基线而言,也损失了一些有用的信息。
朴素的UDA表现平平无奇,其CTR的糟糕表现和迁移学习的原因差不多,都是因为在unbiased dataset上训练,采样出来的大部分都是负例。
改进的UDA:MUDA则在这三个指标上都获得了一致的提升。展现数提升,点击率也提升,说明用户参与度的提高来源于展现了更多高质量的广告。其效果的提升主要还是来源于分桶的操作,提升了UDA中伪标签的质量,没有过拟合排序模型的预测。
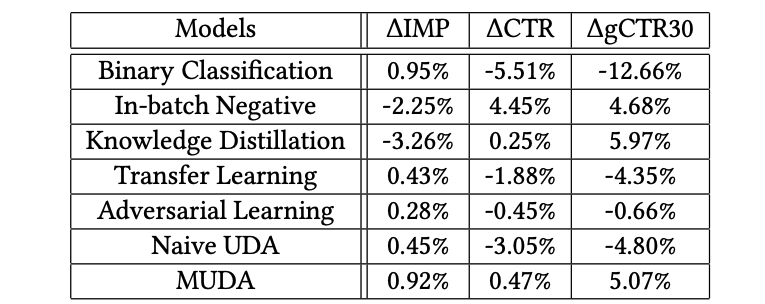

Awareness是指知名度,Traffic是流量,web conversion则是指转化。
batch内负采样模型在知名度广告上的点击提升是因为展现数的大量减少。知名度广告这种主要是提高品牌知名度的,本身点击就比其他类型的广告少,而batch内负采样都是在点击正例上训的,自然对这种广告不友好。流量广告则是为了提升知名度,挖掘潜在客户,推动转化。
而batch内负采样模型在这种类型广告上取得了一致的提升,还是因为它的训练集都是一些高点的交互pair,所以挖掘的广告倾向于吸引高点记录的用户。
MUDA在转化广告方面取得了最高的一致性提升,因为学的排序预估分可能倾向于高转化的,同时分桶策略也进一步促进了更高转化质量的广告候选的挖掘。

很明显MUDA完胜,这说明虽然两者都增加了长期点击,但MUDA通过从这些增加的长期点击中产生更多的转化来表现得更好。
MUDA模型表现更好的一个原因是,该模型更能召回高转化的高质量候选的性能,从而降低广告主的按行为广告计费。
此外,MUDA用的伪标签可能会捕获更多关于用户行为和偏好的相关信息,从而在CPA方面获得更好的性能。
考虑到不同的阈值有不同的影响,所以做了消融,主要是在unbiased dataset上,将排序模型预估的gCTR30按照分位数进行分桶。然后对每个桶,按照两种方式来计算后验的gCTR30,一种方式计算有真实用户行为的那部分样本的gCTR30,还有一种方式是统计真实点击数除以桶内候选数。由此,可以得到如下消融模型:
v1:使用第一个阈值选择策略在有偏和无偏数据集上训练MUDA模型 v2:仅在使用第一个阈值选择策略的无偏数据集上训练MUDA模型 v3:仅在使用第二个阈值选择策略的无偏数据集上训练MUDA模型
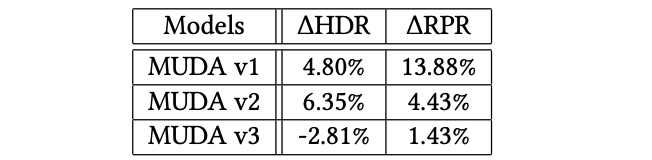

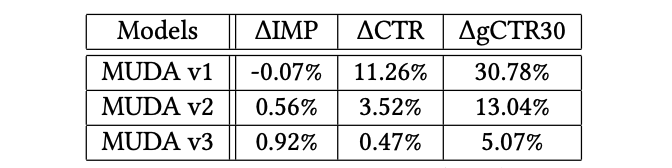
v1模型似乎效果最好,但按照广告类型看,v1过于倾向转化广告类型,这表明使用有偏数据集确实会让模型去学到高转化的信息,毕竟训练集合中都是排序排出来和实际展现出的高转化广告。对比v2和v3,v3在所有广告类型中取得了很好的平衡,说明计算阈值的时候,第二种策略比较接近召回候选的真实gCTR30。
HDR和RPR是两个业务指标,一个是广告隐藏率,一个是广告的re-pin率。虽然RPRdou增加了,但v1和v2模型都推荐了更多将被用户隐藏的广告,这表明这些模型推荐的一些广告并没有为用户提供良好的体验。相比之下,MUDA v3模型通常在所有指标中具有最平衡的改进,这表明用户参与度的积极提升和不需要的用户体验(HDR)的减少。
在实际操作中,感觉上如果不用精排排出的数据集做训练,仅在全库候选中采样一批数据的话,效果并不一定会很好,这更取决于候选库的大小和采样的质量。本人读完这篇文章可能更倾向于选择v1版本的模型。此外,之所以定“v1”也许这也是作者团队本来的选择,只是做消融时,发现v3可能更好。
从缓解ssb问题本身来看,这篇文章核心还是为训练集补充了全库随机样本集合。只是这种制作数据集的方式也很难应用到流式更新的召回模型中。不过这篇文章还是非常翔实地调研了各种策略,或许后续可以将其中的一些策略结合起来使用。
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢