
点击下方卡片,关注「集智书童」公众号

视觉Transformer(Vision Transformers,ViT)作为图像分类的首选模型,其不断增长的受欢迎程度导致了大量的架构修改,声称比原始ViT更高效。然而,由于各种各样的实验条件,仅基于它们报告的结果很难对所有这些模型进行公平比较。
为了填补这一可比性的差距,作者对30多个模型进行了全面分析,评估了视觉Transformer和相关架构的效率,考虑了各种性能指标。作者的基准测试提供了一个跨效率导向的Transformer领域的可比较Baseline,揭示了大量令人惊讶的见解。
例如,作者发现尽管存在多种声称更高效的替代方法,但ViT在多个效率指标上仍然是帕累托最优的。结果还表明,当涉及到推理内存和参数数量较少时,混合注意力-CNN模型表现特别出色,而且模型规模的扩大要优于图像大小的扩大。
此外,作者发现FLOPS数量与训练内存之间存在很强的正相关关系,这使得可以仅通过理论测量来估算所需的VRAM。由于作者的全面评估,这项研究为从业者和研究人员提供了有价值的见解,有助于在选择特定应用的模型时做出明智的决策。
代码:https://github.com/tobna/WhatTransformerToFavor
近年来,对Transformer架构的兴趣导致了自然语言处理(NLP)和计算机视觉(CV)领域的最先进解决方案。过去,不同的AI问题通常依赖于不同的专门架构。语言任务通常依赖于循环神经网络(RNNs),而视觉问题通常使用卷积神经网络(CNNs)。
然而,Transformer的引入触发了研究社区,使其适应解决语言和视觉等各种问题的原则。特别是对于图像分类,Vision Transformer(ViT)已经成为最知名的原始架构应用之一。ViT在像ImageNet这样的基准上取得了最先进的性能,超越了更传统的CNN架构。
然而,在使用Transformer模型时的一个主要挑战是处理自注意力机制的计算复杂性。这个机制使得Transformer能够捕捉序列位置之间的所有对之间的全局依赖关系,但它在输入长度上具有的计算复杂性,这使得它在长序列和高分辨率图像上不切实际。
已经在减少Transformer模型的计算复杂性方面付出了努力,特别是在资源受限的环境中,比如嵌入式系统。CV和NLP领域的研究人员已经探索了许多策略,比如实施稀疏、局部化或核化的注意力机制,以及通过减少序列长度来减少Token的移除标准。
然而,选择最有效的模型,以满足某些性能标准,仍然是一项具有挑战性的任务。这个目标尤其困难,因为“效率”可以指不同的概念,比如训练资源、推理速度、内存需求或模型参数数量。此外,在文献中报告的不同训练和评估条件使得很难了解来自NLP的效率权衡如何传递到视觉任务中。
为了解决这些问题,作者设计了一个分类Transformer,以提高其效率的方式。这有助于作者将效率提高归因于一般策略。然后,作者设计了一个公平的测试平台,以比较最近一些高效ViT的最新进展,使用了各种性能指标。通过这个测试平台,作者为图像分类中的高效ViT提供了全面的Baseline,对当前关于高效Transformer模型研究的状态进行了全面的回顾和基准测试。
为了确保公平的实证比较,作者采用了DeiT III的训练流程,并在该流程上对每个模型架构进行了训练。这是DeiT 广泛流行的流程的更新,已经在几篇论文中用于训练高效的视觉Transformer。
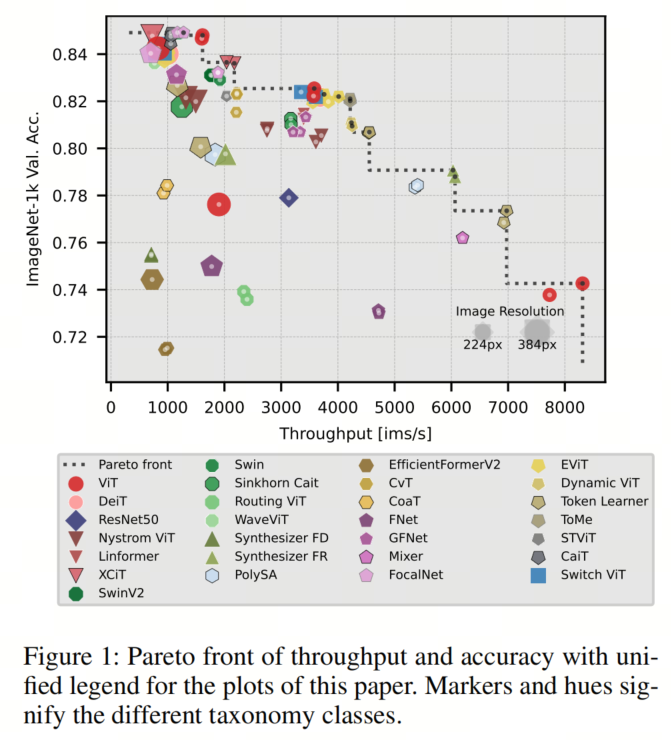
如图1所示,作者的结果表明,即使出现了声称更高效的替代架构,经过良好训练的ViT仍然是帕累托最优的,展示了在保持高准确性的同时具有卓越吞吐量的效率。
此外,作者获得了关于序列缩减技术和混合注意力模型的帕累托最优性以及在更高分辨率下微调的低效性的宝贵见解。作者的方法使作者能够评估不同模型架构的固有优势和劣势,并在一致的条件下测量现实世界的性能指标,为研究人员和从业者选择最有效和最有效的模型架构提供了有价值的资源,以满足其特定用例。
一个分类法,突出显示了可以提高基于Transformer的架构效率的不同方式,以及在NLP和CV中使用的高效Transformer的概述。 对不同基于Transformer的模型进行了全面的基准测试。实验在相似的条件下运行,使结果可以相互比较。特别是,作者为那些被提出用于NLP的模型提供了图像分类的Baseline。 在不同标准下对模型效率进行了比较分析:参数数量、速度和内存,识别了帕累托最优模型,并进行了这些指标之间的相关性分析。
先前的研究已经对不同问题领域中的Transformer进行了调查。此外,研究人员已经从理论和实践的角度评估了不同的深度学习模型的效率。本节概述了关于Transformer调查和测量效率方法的相关工作,而分类法部分则深入探讨了特定的高效Transformer类似架构。
效率已经成为Transformer的一个关键方面,导致在不同领域探索了各种策略和评估方法。关于高效Transformer的调查提供了有价值的分类法和见解。例如,[Efficient Transformers: A Survey]主要关注NLP领域的效率提升,而[ A Practical Survey on Faster and Lighter Transformers]和[ A Survey on Efficient Training of Transformers]收集了增强模型效率的一般方法,包括适用于Transformer的方法。
对于ViT, Efficiency 360 提供了一个基于不同方面(如计算复杂性、稳健性和透明性)分类的高效版本详细列表。他们以及[A Survey of Visual Transformers]根据原始论文中的数据比较了ViT的效率,涵盖了参数、ImageNet准确性和其他性能指标。
对ViT类似模型的调查,由[A Survey on Vision Transformer]、[Transformers Meet Visual Learning Under standing: A Comprehensive Review]和[Transformers in Vision: A Survey]进行,重点是根据不同的视觉任务对模型进行分类,而[Vision transformers for dense prediction: A survey]则专注于密集预测。
此外,[Recent Advances in Vision Transformer: A Survey and Outlook of Recent Work]考察了ViT类似模型随时间在各种视觉任务中的发展情况,[Transformers in computational visual media: A survey]关注于不同使用层次,如高层次、低层次和Backbone模型。
专门的调查研究了在特定领域中应用Transformer的情况,例如动作识别[Vision Transformers for Action Recognition: A Survey]、图像恢复[Vision Transformers in medical computer vision—A contemplative retrospection]、医学图像处理( Transformers in medical imaging: A survey;Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives;Transformers in medical image analysis;Vision Transformers in medical com puter vision—A contemplative retrospection)或遥感(Transform ers in Remote Sensing: A Survey)。
其他调查还探讨了在其他模态中的Transformer的应用,如语音识别(Transformers in Speech Processing: A Survey)、语言处理(Pre-trained transformers: an empirical comparison)、时间序列分析(Transformers in Time Series: A Survey)或多模态任务(Multimodal Learn ing with Transformers: A Survey)。
深度学习模型的效率评估是另一个研究领域。例如,Compute-Efficient Deep Learning: Algorithmic Trends and Opportunities提供了关于效率方面和指标的理论概述,以及测量方法。The Efficiency Misnomer详细讨论了效率指标,突出了仅依靠理论指标的潜在陷阱。An Analysis of Deep Neural Network Models for Practical Applications进行了关于CNN效率的广泛调查,Not All Patches are What You Need: Expediting Vision Transformers via Token Reorganizations使用吞吐量和准确性的帕累托前沿比较了他们的新型架构与旧模型的效率。最后,Long Range Arena: A Benchmark for Efficient Transformers构建了一个全面的基准测试,以量化Transformer模型性能的各个方面,有助于进行效率评估。
与此相反,本文专注于使视觉中的Transformer更加高效的不同总体策略。作者通过在多个指标上对高效Transformer进行实证评估,为这些不同方法之间提供了见解和比较。
首先,作者介绍了ViTs的关键要素,这些要素已经被研究以使其更加高效,以及其主要瓶颈:的计算复杂度。通过识别这些组成部分,作者可以建立一个基于文献中已提出的主要增强Transformer效率策略的分类。
ViT是原始Transformer模型的一种适应,用于图像处理任务。与文本不同,ViT以图像作为输入,并将其转换为一系列不重叠的Patch。每个Patch都被线性嵌入到大小为的Token中,附加了位置编码和分类Token[CLS],然后将其馈送到Transformer编码器中。
在那里,自注意力机制计算Token之间的注意力权重A,利用query()和key()矩阵:
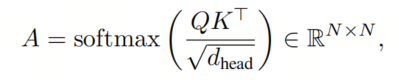
其中是按行计算的。这个矩阵编码了每对Token之间的全局交互作用,但也是注意力机制具有计算(空间和时间)复杂性的原因。自注意力机制的输出序列是输入序列的加权和,使用Value矩阵(V):

经过自注意力机制之后,序列通过具有MLP层的前馈网络传递,最后只使用[CLS]Token进行分类决策。
现在作者已经介绍了构成ViT的主要组成部分,作者可以讨论已经提出的最重要的修改,以使其更加高效。为了更好地理解不同的方法,作者提出了一个基于模型中进行更改的位置的分类(见图2)。
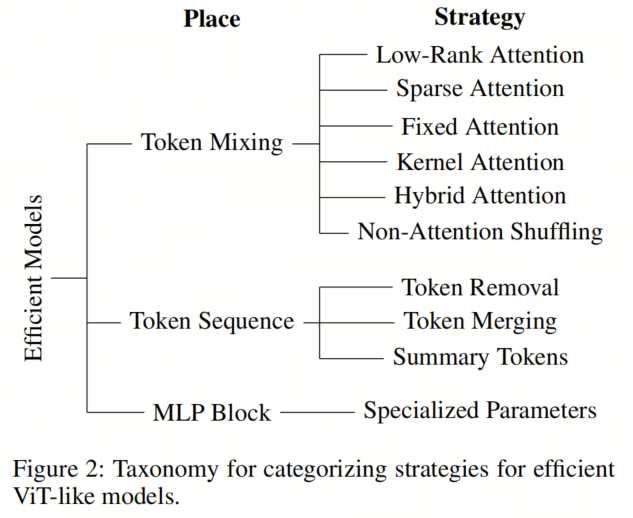
在这里,作者识别了3个主要领域:Token Mixing机制、Token序列和MLP块。下面作者将对每个领域进行更详细的描述。尽管这个分类不是为了全面了解类似ViT的模型,但它被提出作为一个工具,用于识别使ViTs更高效的最流行策略。
第一个也是最流行的方法是改变Token Mixing机制,直接解决了自注意力的计算复杂度。有多种策略可以实现这一目标:一些方法用减少计算量的方式来近似注意力机制,这可以通过矩阵分解、改变操作顺序或固定注意值来实现。
其他方法将注意力与CNN结合起来,在注意力机制中执行子采样或减少注意力机制的使用次数。最后,一些方法舍弃了注意力机制,而是引入了全新的Token混合策略。
低秩注意力利用了方程(1)中的Q和K是形状为的矩阵的事实,这使得成为秩的矩阵。Linformer利用这一事实将K和V的序列方向投影到维度,而不会太多地减少注意矩阵的信息内容。
类似地,Nystromformer使用了矩阵分解的Nystrom方法来近似矩阵。然后,通过将分别应用于每个部分,以线性复杂度计算近似注意力机制的输出。XCiT的方法利用了一个转置的注意力机制:
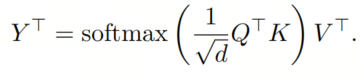
在这里,使用来替代低秩矩阵QK^T,以定义一个全局信息滤波器,该滤波器应用于每个Token。由于query()和key()都很可能是秩为d的,前者很可能具有完全秩,这可以实现更高效的信息编码。
与这些动态近似全局交互的方法不同,还有稀疏注意力。正常的注意力往往只关注少数输入Token,并为大多数其他Token分配较低的注意力分数。稀疏注意力利用了这一点,将大多数注意力权重设置为零,并仅计算最重要的那些。动态确定的注意力矩阵的部分可以基于固定模式,就像在广泛使用的Swin Transformer和SwinV2中一样,在这些模型中,注意力仅在局部图像Token集内执行,或者在HaloNet中,每个Token只能关注其局部邻域。另外,Routing Transformer通过基于其内容对Token进行分组来确定交换信息的Token集。
与之相反,Sinkhorn Transformer固定了局部群组,并允许Token只能使用动态置换矩阵关注不同的群组。保持注意力矩阵稀疏的另一种方法是对key和值进行子采样。例如,WaveViT使用离散小波变换进行子采样,而CvT利用带Stride为2的卷积。
将注意值预先设定的极端示例是学习一个固定的注意力矩阵A。在这种情况下,注意力仅依赖于Token的位置。这在Synthesizer中有所探讨。
核心注意力是一种改变方程(1)中计算顺序的方法。它不是在乘积上使用softmax,而是将核函数分别应用于query Q和key K:
其中可以在Token数量为N时以线性复杂度O(N)计算。已经提出了各种核函数,包括随机高斯核,它是由Performer引入的,并在FourierLearner-Transformer中通过在相位空间中添加相对位置编码来扩展。Scatterbrain将Performer的注意力机制与稀疏注意力相结合。Poly-SA使用恒等函数,Linear Transformer使用ELU,Performer的另一变种使用ReLU核。
混合注意力方法将卷积与注意力机制结合起来。EfficientFormer(-V2)最初使用卷积来关注局部交互作用,然后使用注意力机制来捕捉全局交互作用。另一种方法是在注意力机制内部使用卷积来创建具有局部信息的query、key和值,就像在CvT中用于子采样key和值以及在CoaT中一样。
除了这些基于注意力的方法外,最近的研究还探索了非注意力的Shuffle技术来捕捉全局交互作用。MLP-Mixer沿着Token序列应用全连接层进行全局交互,而FocalNet使用卷积提取一系列上下文。此外,FNet直接利用快速傅里叶变换(FFT)进行O(N log N)复杂度的Token混合,而GFNet则利用它来实现全局卷积。
第二类,即Token序列,在计算机视觉中的高效Transformer中比自然语言处理中更为普遍。这里的想法是移除通常包含在图像中的冗余信息,通过这样做,降低计算成本而不显著影响模型的性能。方法旨在通过移除不必要的图像块(例如与背景相关的块),通过合并相似的块以最小化冗余信息,或通过将信息汇总为更少的抽象Token来减少Token序列。这些模型利用了自注意力机制的复杂度,以实现计算成本的大幅降低,因为移除30%的Token可将所需的操作减少约50%。
对于Token的移除,关键是确定哪些Token可以移除而不丢失关键信息。为此,Dynamic ViT使用Gumbelsoftmax来确定Token保留的概率,而A-ViT学习了加权不同深度的Token输出的停止概率。相比之下,EViT通过利用前一层的注意力矩阵来移除Token,避免了引入额外的参数。
另一种策略是通过Token合并来去除冗余信息。虽然EViT的某个版本合并了不重要的Token,但ToMe则根据它们的相似性合并Token,使用快速的二部匹配算法。
到目前为止讨论的方法修改了现有的Token序列。然而,另一种策略是将其压缩成少数摘要Token。CaiT通过对最后几层的单个Token进行交叉注意力的Token摘要,来收集有关分类决策的全局信息。Token Learner通过对图像Token进行动态求和,创建了一组摘要Token,并且STViT通过使用分步卷积将摘要Token初始化为局部信息,然后使用交叉注意力将全局信息注入其中。
提出的方法改变Transformer架构的最后一种方式是将计算移至MLP块,该块相对于序列长度具有线性复杂度。尽管还有提高效率的空间,但作者只发现了一种采用这种方法的模型。Switch Transformer专注于在保持类似的计算成本的同时提高性能。这是通过为每个MLP块引入多组专门的参数,并通过不同的参数集将不同的Token传递到不同的块来解决的。因此,Switch Transformer可以拥有多倍于ViT的参数数量,而不会引入大量额外的计算。
总结一下,作者提出的分类法为理解改进ViT样式模型效率的各种方法提供了一个结构化框架。因此,研究人员可以更深入地了解用于提高ViT效率的关键变化,同时也使作者能够比较各种策略之间的广泛趋势。
为了找到最高效的模型,作者需要通过将它们与原始的ViT以及其后续版本进行比较,来量化它们的效率提升。作者还包括ResNet50的指标作为CNN架构的代表性Baseline,以及跨论文的比较点。作者在ImageNet-1k数据集上进行评估,因为这是计算机视觉领域最知名的基准之一。
这些模型经过了总共140个Epoch的训练,使用了DeiT III引入的训练流程。这是DeiT模型DeiT 使用的流程的更新版本,已经被许多计算机视觉领域的作者成功用于训练高效的ViT模型(见表1),这就是为什么作者认为这个更新版本是所有模型的一个公平比较点。预训练在ImageNet-21k的清理版本上进行,持续90个Epoch,分辨率为224×224和192×192像素,然后在ImageNet-1k上进行224×224和384×384像素的微调,持续50个Epoch。
在训练不稳定的情况下,作者根据相应的出版物中的值调整了一些超参数。所有训练都是在4或8个NVIDIA A100 GPU上进行的。尽管大多数模型在作者的训练流程中表现良好,但作者无法使Performer、Linear Transformer和HaloNet收敛。
术语"效率"可以有不同的含义;因此,在评估模型的效率时考虑多个维度是至关重要的。在本文中,作者关注三个维度:内存效率、推理效率和训练效率。内存效率是指在有限的VRAM上训练或部署模型,推理效率评估预测速度,训练效率衡量模型在有限时间内学习的能力。
为了评估效率,作者使用了参数数量和FLOPS的理论指标,这些指标提供了模型的表示能力和计算需求的估计。然而,理论指标不总是与现实性能相关,特别是在比较不同的架构时。相反,通过在硬件上运行模型获得的经验指标可以提供更准确的评估,因此作者还跟踪了训练的GPU时间、在最佳批处理大小下的推理吞吐量以及VRAM需求。尽管经验指标可能对硬件和软件配置敏感,但作者通过为所有模型使用相同的设置来确保一致的评估。
由于效率存在复杂的权衡,不能通过一个单一的数字来捕捉。因此,作者关注帕累托前沿,以识别在两个指标之间实现最佳权衡的模型。帕累托前沿代表了最有效的折衷方案,前沿上的一个点在至少一个指标上胜过其他每个点。
为确保公平评估和跨模型可比的结果,作者首先比较原始论文中报告的ImageNet准确性和在作者的流程中训练后获得的准确性,见表1。作者可以看到,相当大一部分这些流程都基于DeiT III的流程,使它们非常适合用于使用该流程的更新版本进行训练。
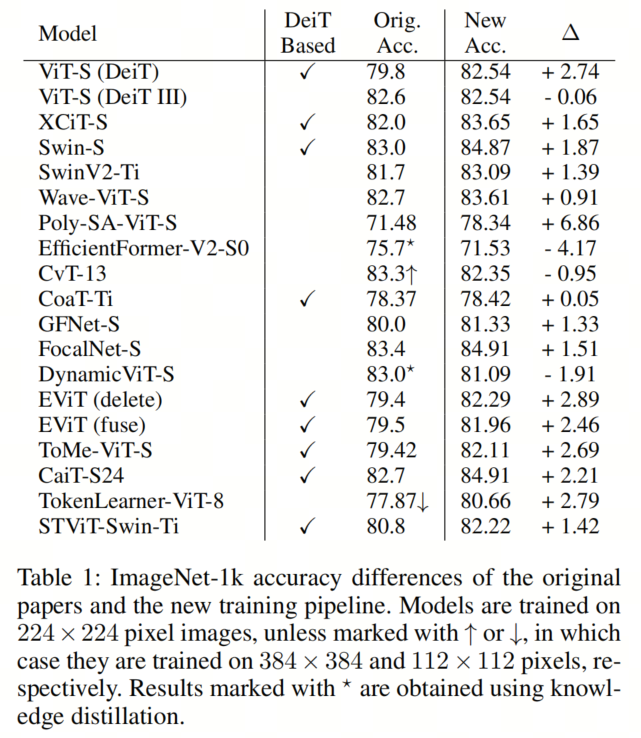
总体而言,作者观察到几乎所有使用作者流程训练的模型都获得了更高的准确性,平均提高了1.35%。此外,原始流程明显优于作者流程的所有模型都是使用知识蒸馏或在更高分辨率下进行微调训练的。最高的改进为+6.86%,对Poly-SA来说,这表明原始论文中可能存在训练不稳定性问题,类似于作者在其他Kernel Attention模型中遇到的问题。
大多数分类类别中,模型的最高准确度约为85%。但是,有两个显著的例外情况:Kernel Attention类,该类模型在优化方面存在挑战,以及Fixed Attention类,其中使用恒定的注意矩阵固有地导致较低的准确性。总之,该流程为所有模型提供了一个强大且可比的Baseline,无论其架构差异如何。
在文献中,参数数量被用作追踪模型复杂性以及使用模型的总体计算成本的代理指标。

在分析不同模型的参数效率时(见图3),很明显,对于大多数较小的模型,每个参数的准确性保持相对恒定,约为。然而,对于较大的模型,这个值约减半,这表明模型大小扩展带来的回报逐渐减少。较小的混合注意力模型,如EfficientFormerV2-S0和CoaT-Ti,在每个参数的准确性方面表现最佳,明显优于其他基于注意力的模型以及卷积神经网络ResNet50。这表明了注意力和卷积的结合允许开发非常参数高效的模型。
对于Baseline的ViT模型,随着模型大小的增加,每个参数的准确性明显下降。虽然ViT-Ti在准确性上优于具有相似准确性的模型,并且ViT-S在与类似模型的表现上差不多,但与其他更大的模型相比,ViT-B的表现稍逊一筹。
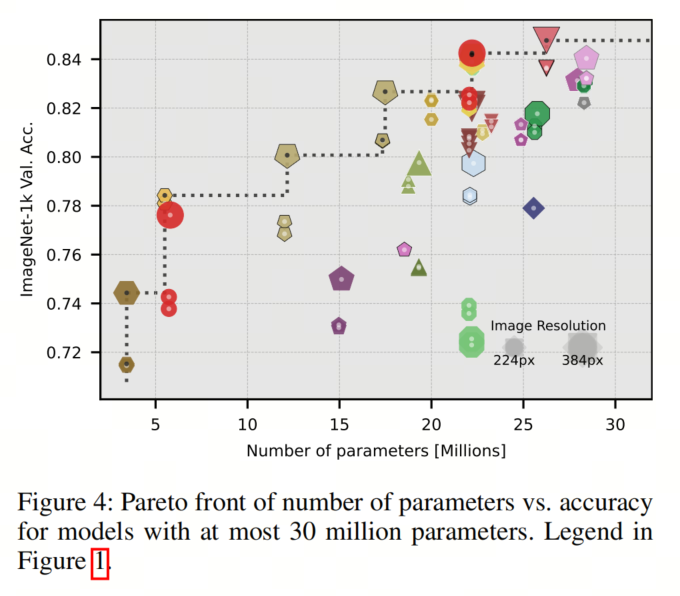
图4突出显示了准确性和参数数量之间的帕累托边界,显示了具有少于3000万参数的模型。值得注意的是,大多数帕累托最优模型都在更高分辨率的384像素上进行了微调,这有助于提高准确性,而不增加参数数量。
在最小的模型尺寸下,作者再次观察到,EfficientFormerV2-S0和CoaT-Ti是帕累托最优模型,而TokenLearner是在ViT-Ti和同样帕累托最优的ViT-S之间的帕累托最优选择。
推理速度是从业者在决定模型部署时非常重要的关键指标。无论是受到对实时处理的严格要求还是希望在合理的时间内获取模型输出的愿望,推理速度直接影响了部署模型的可用性和效果。作者评估的模型通常声称在吞吐量与准确性的权衡方面优于原始的ViT模型。
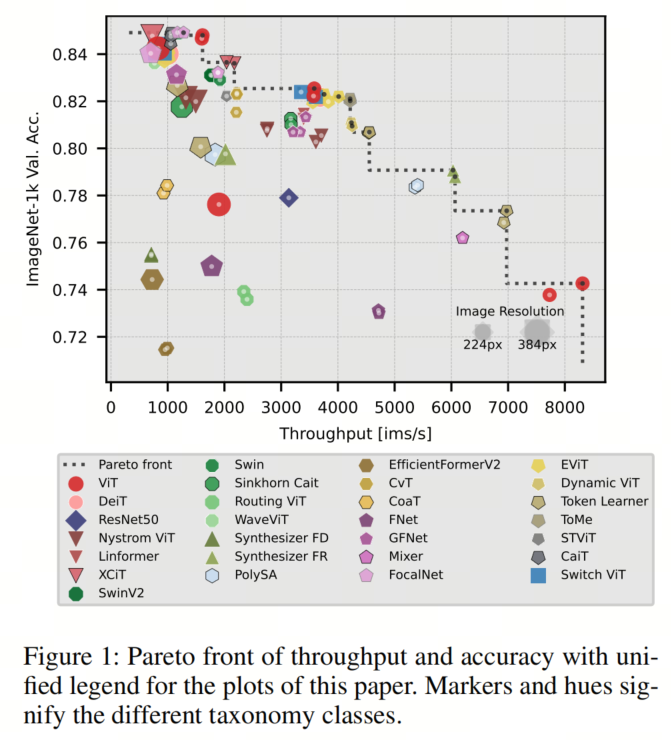
然而,作者的全面评估(见图1)揭示了ViT在所有尺寸上仍然是帕累托最优的。此外,明显可以看出,只有一小部分模型,即Synthesizer-FR和一些序列缩减模型,在与相应尺寸的ViT进行比较时在帕累托前沿上表现出改进。
此外,作者的观察表明,以384像素的更高分辨率进行微调并不是一种高效的策略。虽然这可能会导致模型准确性的提高,但它伴随着计算成本的显著增加,导致吞吐量大幅降低。因此,选择下一个更大的模型事实证明更加高效。尽管较大的模型可能涉及更多的浮点运算,但这些运算可以更有效地并行化,从而实现更高的总体吞吐量以及更高的准确性。
作者观察到推理时间和微调时间之间存在0.81的显著相关性,这得到了作者在帕累托前沿中看到的总体相似性的支持。此外,在作者对微调时间的分析中,TokenLearner模型表现出色,展示了最快的微调速度,同时实现了令人称赞的77.35%的准确性。
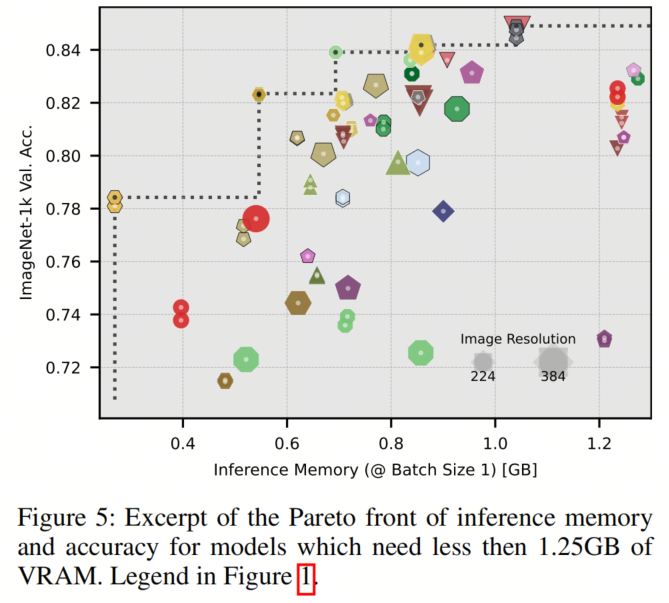
VRAM对深度学习研究和实践施加了重要的限制,因为它对可用模型强加了严格的限制。在推理期间优化VRAM使用情况的分析(见图5)显示,混合注意力模型CoaT和CvT表现出了出色的性能。
值得注意的是,Wave-ViT、EViT、ToMe以及在384像素上微调的模型以及CaiT构成了更大尺寸的Pareto前沿。重要的是,ViT在这个度量标准下无法实现帕累托最优性。这一观察表明,与参数数量类似,混合注意力模型在内存受限环境中表现出色。
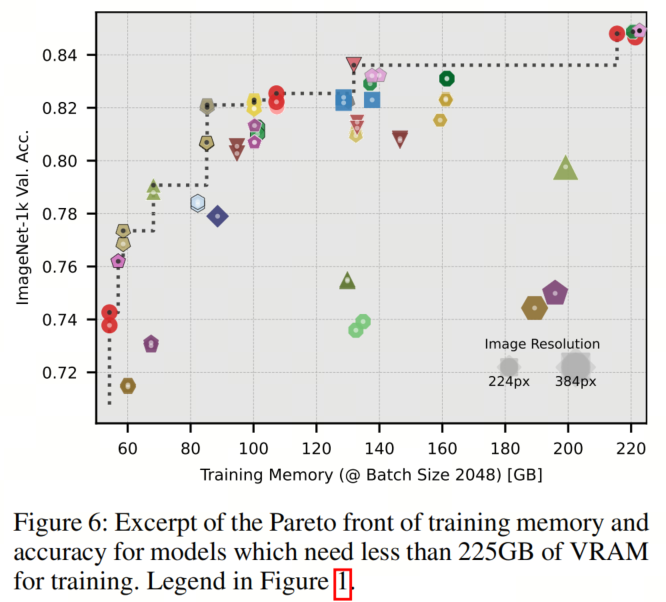
相反,在训练内存方面(见图6)表现出了与吞吐量观察到的相似模式,因此作者测得了训练内存和推理时间之间相对较高的0.71的相关性。在这里,CoaT和CvT需要比其他具有相似准确性的模型更多的内存,而ViT仍然保持其在Pareto优化性方面的优势,与序列缩减模型EViT、ToMe、TokenLearner、Synthesizer-FR和XCiT一样。
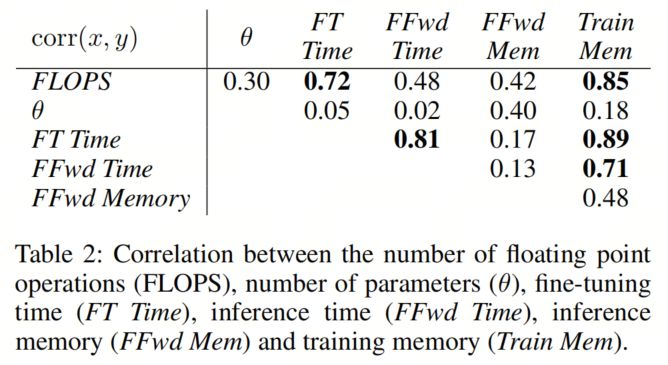
作者发现微调时间和训练内存之间的最高相关系数为0.89。这强烈的相关性表明存在一个共同的潜在因素或瓶颈,可能与训练过程中的内存读取需求有关。了解这种关系可以为了解影响训练效率的因素提供有价值的见解。令人感兴趣的是,一个理论度量中最高的相关系数为0.85,发现在FLOPS和训练内存之间,这表明可以根据理论FLOPS粗略估算用于训练的VRAM,使用以下近似值:
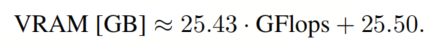
令人惊讶的是,当考虑不同的模型架构时,其他评估的度量在表2中表现出相对较弱的相关性,这突显了仅基于理论度量来估算计算成本的可靠性有限。因此,评估实际场景中模型的效率需要测量新型架构的吞吐量和内存需求。
作者对类似于Transformer的视觉架构进行了广泛而实证的分析,为它们在多个维度上的性能和效率提供了有价值的见解。通过严格的实验,作者已经证明,一个经过良好训练的ViT在各个维度上仍然保持帕累托最优,强调了它作为基准模型的有效性。
此外,作者的研究结果突显了序列缩减技术的效率。作者还确定了在更高分辨率下微调并不是一种高效的策略,因为扩展模型大小的方式更加有效。在比较不同的效率度量时,作者揭示了仅仅基于理论度量来估算计算成本的局限性。然而,可以根据模型的理论FLOPS粗略估算训练所需的VRAM。
重要的是,作者希望作者的研究可以被用作参考Baseline,为进一步研究高效深度学习模型的不断努力提供坚实的基础。从这项研究中获得的见解可以为各种实际应用的模型设计和优化提供指导。
[1].Which Transformer to Favor:A Comparative Analysis of Efficiency in Vision Transformers.
清华联合北航提出全新多模态融合方法SkipcrossNets,更快更强!!
CS-Mixer | MLP-Like 中的王者,让MLP Token也有跨尺度交互
新加坡国立大学提出SG-Former | ViT中的好学生,超越SWin和CSWin Transformer!

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)





前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢