
作者 | 求求你们别学了
原文链接:https://zhuanlan.zhihu.com/p/646144802
本文只做学术分享,如有侵权,联系删文
传统的问题

Occupancy优点



思想
不分动静态,用占据网格 能否用分割完全代替目标检测(难,分割干扰太多,没有检测好) 相机和lidar殊途同归,最后呈现的形式都差不多。因为真值相似,深度学习泛化。 占据栅格更像是BEV的3D升级 bevformer和LSS的区别, LSS可解释性强,但是会被限制。BEV选LSS,3D栅格选former
Occupancy Networks:特斯拉占据栅格网络
特斯拉的Occupancy Networks是一种用于3D目标检测和场景重建的神经网络模型,它能够从点云数据中提取出场景中各个物体的三维形状、位置和朝向等信息。
Occupancy Networks的基本思想是将点云数据转化为一个体素网格,并在每个体素上学习一个二值分类器,用于判断该体素是否属于某个物体。具体地,网络首先将输入点云映射到一个球形表面上,并利用一个编码器将球面图像转换为一个隐式函数,该隐式函数可以预测空间中任意点的占据状态。然后,网络在三维空间中将该隐式函数采样为一个体素网格,并对每个体素进行二值分类,从而得到每个体素的占据状态,进而重建出场景中各个物体的三维形状。
Occupancy Networks具有很强的泛化能力,可以在仅有少量标注数据的情况下,实现高质量的物体检测和重建。此外,该模型还可以在物体检测的同时输出物体的朝向和位置,有助于实现更加精细的场景理解和场景重建。
这里输出的并非是对象的确切形状,而是一个近似值,可以理解为因为算力和内存有限,导致轮廓不够sharp,但也够用。另外还可以在静态和动态对象之间进行预测,以超过 100 FPS 的速度运行。基于视觉的系统有 5 个主要缺陷:地平线深度不一致、物体形状固定、静态和移动物体、遮挡和本体裂缝。特斯拉旨在创建一种算法来解决这些问题。新的占用网络通过实施 3 个核心思想解决了这些问题:体积鸟瞰图、占用检测和体素分类。这些网络可以以超过 100 FPS 的速度运行,可以理解移动对象和静态对象,并且具有超强的内存效率。
BEV->OCC
Bird's Eye View (BEV) 算法和 Occupancy Grid Mapping 是两种常用的环境感知和表示方法。BEV 是一种二维表示,它从鸟瞰视角(即,从上往下看)展示环境。而 Occupancy Grid Mapping 则是一种三维表示,它将环境划分为一系列的立方体(或称为体素,voxels),并为每个体素分配一个值,表示该体素是否被物体占据。
从 BEV 特征转换到 3D voxel 特征的一个常见方法是通过一系列的卷积和反卷积(或称为转置卷积)操作。这些操作可以将 2D BEV 特征映射到 3D 空间,生成一个 3D 特征图。然后,这个 3D 特征图可以被送入一个 3D 卷积网络,用于预测每个体素的占据状态。
然而,这种方法的一个挑战是,由于 3D 卷积操作的计算复杂性,处理大规模的 3D 特征图可能会非常耗时和计算密集。因此,一些方法可能会采用一些策略来降低计算复杂性,例如,只在感兴趣的区域(例如,地面附近的区域)进行 3D 卷积,或者使用稀疏卷积来只处理那些包含有意义信息的体素。
总的来说,从 2D BEV 特征转换到 3D voxel 特征,然后再接上一个预测占据状态的head,可以被看作是一种占据栅格算法。但是,具体的实现细节可能会根据具体的应用和需求有所不同。
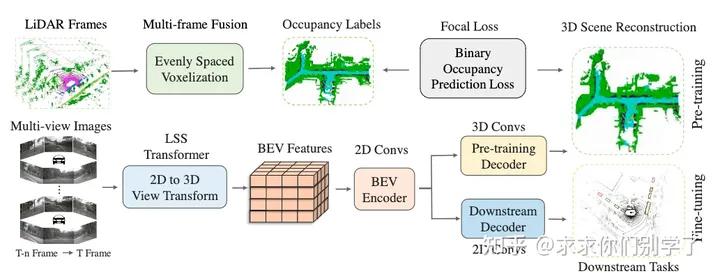

总结:
当前仅基于视觉的系统的算法存在问题:它们不连续,在遮挡方面做得不好,无法判断物体是移动还是静止,并且它们依赖于物体检测。因此,特斯拉决定发明“Occupancy network”,它可以判断 3D 空间中的一个单元格是否被占用。 这些网络改进了 3 个主要方面:鸟瞰图、物体类别和固定大小的矩形。 occupancy network分 4 个步骤工作:特征提取、注意和occupancy检测、多帧对齐和反卷积,从而预测光流估计和占用估计。 生成 3D 体积后,使用 NeRF(神经辐射场)将输出与经过训练的 3D 重建场景进行比较。 车队平均采集数据用于解决遮挡、模糊、天气等场景


推荐阅读
西电IEEE Fellow团队出品!最新《Transformer视觉表征学习全面综述》 润了!大龄码农从北京到荷兰的躺平生活(文末有福利哟!) 如何做好科研?这份《科研阅读、写作与报告》PPT,手把手教你做科研 奖金675万!3位科学家,斩获“中国诺贝尔奖”! 又一名视觉大牛从大厂离开!阿里达摩院 XR 实验室负责人谭平离职 最新 2022「深度学习视觉注意力 」研究概述,包括50种注意力机制和方法! 【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载! 2021李宏毅老师最新40节机器学习课程!附课件+视频资料
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢